






Spark多语言开发
学习目标
1.掌握使用Java语言开发Spark程序
2.了解线性回归算法案例
3.了解使用Python语言开发Spark程序
4.了解决策树分类算法案例

1. JavaSpark
1.1 编程语言说明
Spark 在诞生之初就提供了多种编程语言接口:Scala、Java、Python 和 SQL,在后面的版本中又加入了 R 语言编程接口。
对于 Spark 来说,虽然其内核是由 Scala 编写而成,但编程语言从来就不是它的重点,从 Spark 提供这么多的编程接口来说,Spark 鼓励不同背景的人去使用它完成自己的数据探索工作。尽管如此,不同编程语言在开发效率、执行效率等方面还是有些不同,对比如下:
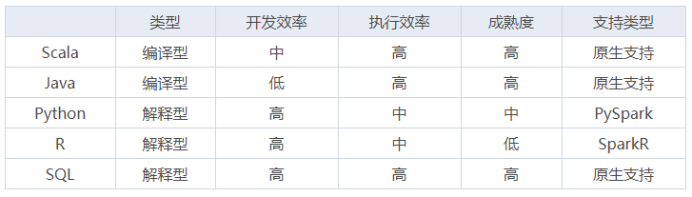
ü Scala 作为 Spark源码 的开发语言当然得到了原生支持,也非常成熟,它简洁的语法也能显著提高开发效率;
ü Java 也是 Spark 原生支持的开发语言,但是1.7之前 Java 语法冗长且不支持函数式编程,导致它的 API 设计得冗余且不合理,1.8 以后开始支持函数式编程,且Java语言规范性好,应用范围广,用户基数大,所以Java API 也是一个很好的选择;
ü Python 与 R 语言都是解释型脚本语言,可以直接解释执行,不用编译。尤其是 Python 更以简洁著称,开发效率自不必说,此外 Python 与 R 语言本身也支持函数式编程,这两种语言在开发 Spark 作业时也是非常自然,但由于其执行原理是计算任务在每个节点安装的 Python 或 R 的环境中执行,结果通过管道输出给JVM,所以效率要比 Scala 与 Java 低;
ü SQL 是 Spark 原生支持的开发语言,从各个维度上来说都是最优的,所以一般情况下,用 Spark SQL 解决问题是最优选择。
★注意 1:
这里要特别说明的是,Spark 是由 Scala 开发而成,对于Java、Scala 编程接口来说,在执行计算任务时,是由集群中每个节点的 JVM(Scala 也是 JVM 语言)完成。
但是如果采用 Python、R 语言编程接口,那么执行过程是由集群中每个节点的 Python 与 R 进程计算并通过管道回传给 JVM,所以性能上会有所损失。具体来说:PySpark是借助Py4j实现Python调用Java,来驱动Spark应用程序,本质上主要还是JVM runtime。在大数据场景下,JVM和Python进程间频繁的数据通信导致其性能损耗较多,恶劣时还可能会直接卡死,所以建议对于大规模机器学习或者Streaming应用场景还是慎用PySpark,应该尽量使用原生的Scala/Java编写应用程序,对于中小规模数据量下的简单离线任务,可以使用PySpark快速部署提交。
★注意 2:
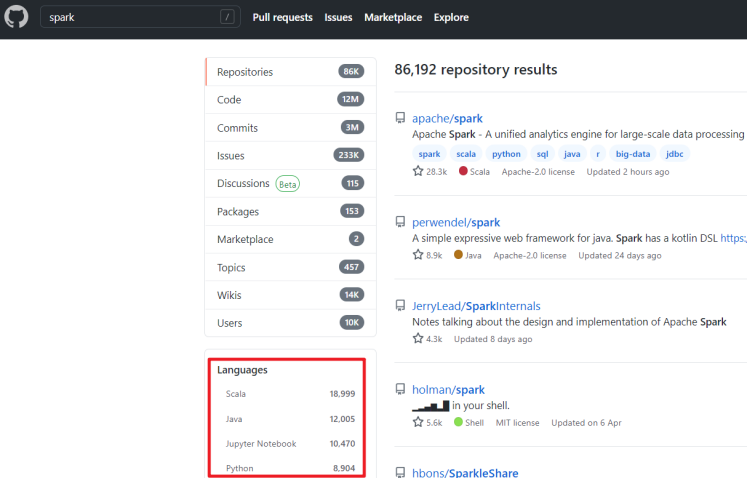
此外,通过GitHub上Spark相关项目的使用语言上来看,也是Scala使用的最多,所以课程中使用Scala语言为主,但会扩展讲解使用其他语言进行Spark开发
https://github.com/search?q=spark
1.2 SparkCore
| package cn.itcast.hello;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import scala.Tuple2;import java.util.Arrays;import java.util.List;public class SparkCoreDemo { public static void main(String[] args) { //1.创建sc SparkConf conf = new SparkConf().setAppName("wc").setMaster("local[*]"); JavaSparkContext jsc = new JavaSparkContext(conf); jsc.setLogLevel("WARN"); //2.读取文件 JavaRDD<String> fileRDD = jsc.textFile("data/input/words.txt"); //3.处理数据 //3.1每一行按照" "切割 /* java8中的函数格式: (参数列表)->{函数体;} 注意:原则也是能省则省 public interface FlatMapFunction<T, R> extends Serializable { Iterator<R> call(T t) throws Exception; } */ //通过查看源码,我们发现,flatMap中需要的函数的参数是T(就是String) //返回值是Iterator //所以我们在函数体里面要返回Iterator JavaRDD<String> wordRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(" ")).iterator()); //3.2每个单词记为1 (word,1) /* public interface PairFunction<T, K, V> extends Serializable { Tuple2<K, V> call(T t) throws Exception; } */ JavaPairRDD<String, Integer> wordAndOneRDD = wordRDD.mapToPair(word -> new Tuple2<>(word, 1)); //3.3按照key进行聚合 /* public interface Function2<T1, T2, R> extends Serializable { R call(T1 v1, T2 v2) throws Exception; } */ JavaPairRDD<String, Integer> wrodAndCountRDD = wordAndOneRDD.reduceByKey((a, b) -> a + b); //4.收集结果并输出 List<Tuple2<String, Integer>> result = wrodAndCountRDD.collect(); //result.forEach(t->System.out.println(t)); result.forEach(System.out::println); //函数式编程的思想:行为参数化 //5.关闭 jsc.stop(); }} |
1.3 SparkStreaming
| package cn.itcast.streaming;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.streaming.Durations;import org.apache.spark.streaming.api.java.JavaPairDStream;import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;import org.apache.spark.streaming.api.java.JavaStreamingContext;import scala.Tuple2;import java.util.Arrays;/** * Author itcast */public class SparkStreamingDemo { public static void main(String[] args) throws Exception { SparkConf sparkConf = new SparkConf().setAppName("wc").setMaster("local[*]"); JavaSparkContext jsc = new JavaSparkContext(sparkConf); JavaStreamingContext ssc = new JavaStreamingContext(jsc, Durations.seconds(5)); jsc.setLogLevel("WARN"); JavaReceiverInputDStream<String> socketDStream = ssc.socketTextStream("node1",9999); JavaPairDStream<String, Integer> result = socketDStream .flatMap(line -> Arrays.asList(line.split(" ")).iterator()) .mapToPair(word -> new Tuple2<>(word, 1)) .reduceByKey((a, b) -> a + b); result.print(); ssc.start(); ssc.awaitTermination(); }} |
1.4 SparkSQL
| package cn.itcast.sql;import org.apache.spark.SparkContext;import org.apache.spark.sql.Dataset;import org.apache.spark.sql.Encoders;import org.apache.spark.sql.Row;import org.apache.spark.sql.SparkSession;import java.util.Arrays;/** * Author itcast */public class SparkSQLDemo { public static void main(String[] args) { SparkSession spark = SparkSession .builder() .appName("SparkSQL") .master("local[*]") .getOrCreate(); SparkContext sc = spark.sparkContext(); sc.setLogLevel("WARN"); Dataset<String> ds = spark.read().textFile("data/input/words.txt"); ds.printSchema(); ds.show(); Dataset<String> wordDS = ds.flatMap((String line) -> Arrays.asList(line.split(" ")).iterator(), Encoders.STRING()); wordDS.printSchema(); wordDS.show(); //SQL wordDS.createOrReplaceTempView("t_words"); String sql = "select value as word,count(*) as counts\n" + " from t_words\n" + " group by word\n" + " order by counts desc"; spark.sql(sql).show(false); //DSL Dataset<Row> tempDS = wordDS.groupBy("value") .count();//.show(false); tempDS.orderBy(tempDS.col("count").desc()) .show(false); }} |
1.5 StructuredStreaming
| package cn.itcast.structedstream;import org.apache.spark.SparkContext;import org.apache.spark.sql.Dataset;import org.apache.spark.sql.Encoders;import org.apache.spark.sql.Row;import org.apache.spark.sql.SparkSession;import java.util.Arrays;/** * Author itcast */public class StructuredStreamingDemo { public static void main(String[] args) throws Exception { SparkSession spark = SparkSession .builder() .appName("SparkSQL") .master("local[*]") .config("spark.sql.shuffle.partitions", "4") .getOrCreate(); SparkContext sc = spark.sparkContext(); sc.setLogLevel("WARN"); Dataset<Row> lines = spark .readStream() .format("socket") .option("host", "node1") .option("port", 9999) .load(); Dataset<Row> result = lines.as(Encoders.STRING()) .flatMap((String line) -> Arrays.asList(line.split(" ")).iterator(), Encoders.STRING()) .groupBy("value") .count(); result.writeStream() .outputMode("complete") .format("console") .start() .awaitTermination(); }} |
1.6 线性回归算法-房价预测案例
1.6.1 需求
根据房屋面积和房屋价格历史数据, 预测新给定房屋面积的价格

1.6.2 实现思路
l 找规律/模型/函数
可以将这些数据放到二维坐标系中,进行描点

通过观察可以发现, x轴/横轴 面积和y轴/纵轴 价格 呈现出一个一元一次线性关系,(当然也可以用更复杂的如一元二次描述)
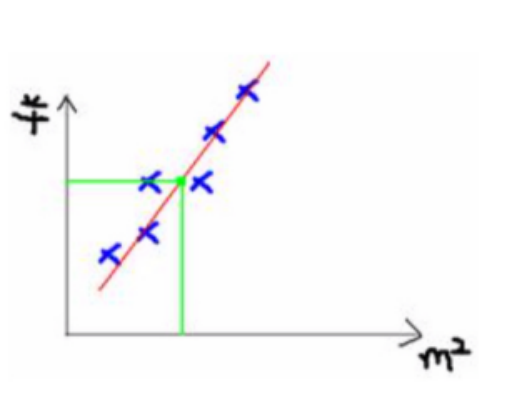
那这个一元一次线性关系,就是红色的那条直线可以用如下方程表示:
y = ax + b
y就是y轴/纵轴,也就是价格
x就是x轴/横轴,也就是面积
l 做预测
既然这样,我们就可以使用该直线: y = ax + b 来拟合这些点,
那么现在的问题就是如何求出a和b?
也就是说如果知道a和b的值, 就可以很方便的根据x(面积),求出y(价格)
也就是可以预测房屋的价格
1.6.3 算法原理
上面的给数据+找规律+做预测 就是机器学习的一个最简单的步骤, 但是其中
找规律和做预测的步骤中需要使用数学工具对a和b的值进行计算! 这样才能完成最终的需求
a和b的值如何确定? 如何寻找?
我们可以尝试使用最优化思想来解决这个问题!
因为a和b的取值有很多种,不能说哪一组a和b的值是正确的,只能说哪一组的a和b的值是最优的
可以定义如下规则:
房屋的真实价格: y'
房屋的预测价格:y''
误差Δy = (y'' - y')^2
总误差: sum((y'' - y')^2)
均方误差: sum((y'' - y')^2)/n
如果找到一组a和b能够让均方误差最小(较小),那么就可以可以说该组a和b 为最优(较优)
因为该a和b的取值可以让所有数据的均方误差最小! 也就是预测值和真实值越接近的!!!
也就是在该组a和b的取值下, y=ax+b对房价的预测的越准确!
那么问题就变成了求如下函数在a和b等于多少的时候有的最小值


l 关于公式推断感兴趣可以去阅读如下链接
对于我们只需要知道, 如上的房价预测案例最后会变成一个数学(最优化)问题!
而数学问题的求解程序已经封装好了, 我们后续直接调用即可
当然如果数学水平还可以的同学可以阅读一些课外资料
https://www.zhihu.com/question/37031188/answer/1301921009
https://baijiahao.baidu.com/s?id=1639202882632470513&wfr=spider&for=pc
https://blog.csdn.net/alw_123/article/details/82193535
https://blog.csdn.net/alw_123/article/details/82825785
https://blog.csdn.net/alw_123/article/details/83065764
1.6.4 代码实现
| package cn.itcast.exercise;import org.apache.spark.SparkContext;import org.apache.spark.ml.evaluation.RegressionEvaluator;import org.apache.spark.ml.feature.VectorAssembler;import org.apache.spark.ml.regression.LinearRegression;import org.apache.spark.ml.regression.LinearRegressionModel;import org.apache.spark.sql.Dataset;import org.apache.spark.sql.Row;import org.apache.spark.sql.SparkSession;/** * Author itcast * Desc */public class HousePriceDemo { public static void main(String[] args) { SparkSession spark = SparkSession .builder() .appName("SparkSQL") .master("local[*]") .config("spark.sql.shuffle.partitions", "4") .getOrCreate(); SparkContext sc = spark.sparkContext(); sc.setLogLevel("WARN"); Dataset<Row> fileDS = spark.read() .format("csv") .option("sep", "|") .option("header", "true") .option("inferSchema", "true") .load("data/input/homeprice.data"); fileDS.show(true); fileDS.printSchema(); //|房屋编号mlsNum|城市city|平方英尺|卧室数bedrooms|卫生间数bathrooms|车库garage|年龄age|房屋占地面积acres|房屋价格price Dataset<Row> homeDS = fileDS.select("sqFt", "age", "acres", "price"); //Dataset<Row> homeDS = fileDS.select("city", "sqFt", "age", "acres", "price"); homeDS.show(true); homeDS.printSchema(); /*Dataset<Row> indexDS = new StringIndexer() .setInputCol("city") .setOutputCol("index_city") .fit(homeDS) .transform(homeDS); Dataset<Row> oneHotResultDS = new OneHotEncoder() .setInputCol("index_city") .setOutputCol("onehot_city") .fit(indexDS).transform(indexDS); oneHotResultDS.show(true); oneHotResultDS.printSchema();*/ Dataset<Row> VectorDF = new VectorAssembler() .setInputCols(new String[]{"sqFt", "age", "acres"}) //.setInputCols(new String[]{"onehot_city", "sqFt", "age", "acres"}) .setOutputCol("features") //.transform(oneHotResultDS); .transform(homeDS); VectorDF.show(true); VectorDF.printSchema(); Dataset<Row>[] splits = VectorDF.randomSplit(new double[]{0.8, 0.2}, 100); Dataset<Row> trainSet = splits[0]; Dataset<Row> testSet = splits[1]; LinearRegressionModel model = new LinearRegression().setStandardization(true).setMaxIter(10) .setFeaturesCol("features") .setLabelCol("price") .setPredictionCol("predict_price") .fit(trainSet); Dataset<Row> result = model.transform(testSet); result.show(true); RegressionEvaluator evaluator = new RegressionEvaluator() .setMetricName("rmse") //均方根误差 .setLabelCol("price") .setPredictionCol("predict_price"); Double rmse = evaluator.evaluate(result); //均方根误差: (sum((y-y')^2)/n)^0.5 System.out.println("rmse为:" + rmse); //rmse为:65078.804057320325 //rmse为:86463.42504994274 }} |
2. PySpark
2.1 SparkCore
| from pyspark import SparkContextif __name__ == "__main__": sc = SparkContext(appName="wc",master="local[*]") text_file = sc.textFile("data/words.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) result = counts.collect() for (word, count) in result: print("%s: %i" % (word, count)) sc.stop() |
2.2 SparkStreaming
| from pyspark import SparkContextfrom pyspark.streaming import StreamingContextif __name__ == "__main__": sc = SparkContext(appName="wc",master="local[2]") ssc = StreamingContext(sc, 5) lines = ssc.socketTextStream("node1", 9999) result = lines.flatMap(lambda line: line.split(" "))\ .map(lambda word: (word, 1))\ .reduceByKey(lambda a, b: a+b) result.pprint() ssc.start() ssc.awaitTermination() |
2.3 SparkSQL
| from pyspark.sql import SparkSessionfrom pyspark.sql import Rowdef wordcount(spark): sc = spark.sparkContext text_file = sc.textFile("data/words.txt") words = text_file.flatMap(lambda line: line.split(" ")).map(lambda word: Row(value=word)) df = spark.createDataFrame(words) df.show() df.printSchema() df.groupBy("value").count().show()def basic_query(spark): df = spark.read.json("data/people.json") df.show() # +----+-------+ # | age| name| # +----+-------+ # |null|Michael| # | 30| Andy| # | 19| Justin| # +----+-------+ df.printSchema() # root # |-- age: long (nullable = true) # |-- name: string (nullable = true) df.select("name").show() # +-------+ # | name| # +-------+ # |Michael| # | Andy| # | Justin| # +-------+ df.select(df['name'], df['age'] + 1).show() # +-------+---------+ # | name|(age + 1)| # +-------+---------+ # |Michael| null| # | Andy| 31| # | Justin| 20| # +-------+---------+ df.filter(df['age'] > 21).show() # +---+----+ # |age|name| # +---+----+ # | 30|Andy| # +---+----+ df.groupBy("age").count().show() # +----+-----+ # | age|count| # +----+-----+ # | 19| 1| # |null| 1| # | 30| 1| # +----+-----+ df.createOrReplaceTempView("people") sqlDF = spark.sql("SELECT * FROM people") sqlDF.show() # +----+-------+ # | age| name| # +----+-------+ # |null|Michael| # | 30| Andy| # | 19| Justin| # +----+-------+if __name__ == "__main__": spark = SparkSession\ .builder \ .appName("wc") \ .master("local[*]") \ .getOrCreate() wordcount(spark) basic_query(spark) spark.stop() |
2.4 StructuredStreaming
| from pyspark.sql import SparkSessionfrom pyspark.sql.functions import explodefrom pyspark.sql.functions import splitif __name__ == "__main__": spark = SparkSession\ .builder\ .appName("wc")\ .master("local[*]") \ .config("spark.sql.shuffle.partitions", "2")\ .getOrCreate() lines = spark \ .readStream \ .format('socket') \ .option('host', "node1") \ .option('port', 9999) \ .load() words = lines.select( explode( split(lines.value, ' ') ).alias('word') ) result = words.groupBy('word').count() result\ .writeStream\ .outputMode('complete')\ .format('console')\ .start()\ .awaitTermination() |
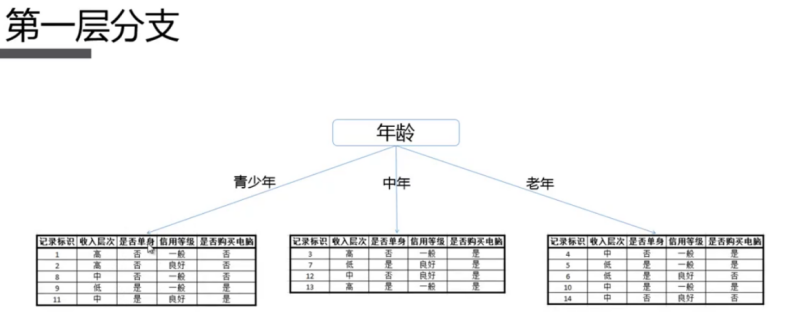
2.5 决策树分类算法-相亲决策案例
2.5.1 需求
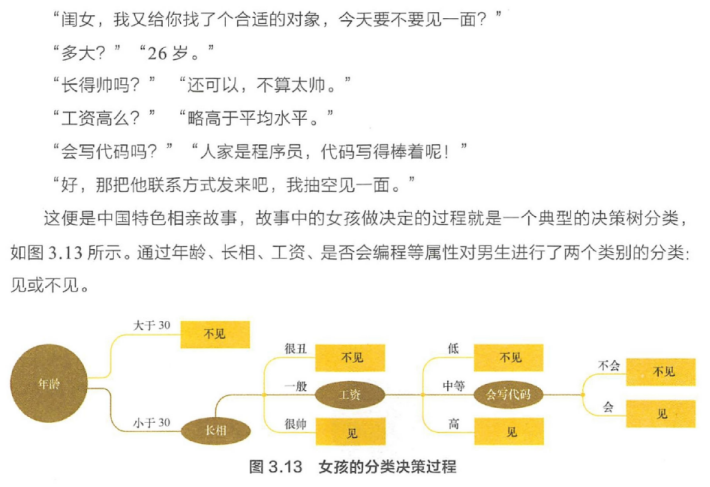
现假设一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是程序员不?
母亲:是,在黑马学习大数据呢,毕业了就是程序员了!
女儿:那好,我去见见。

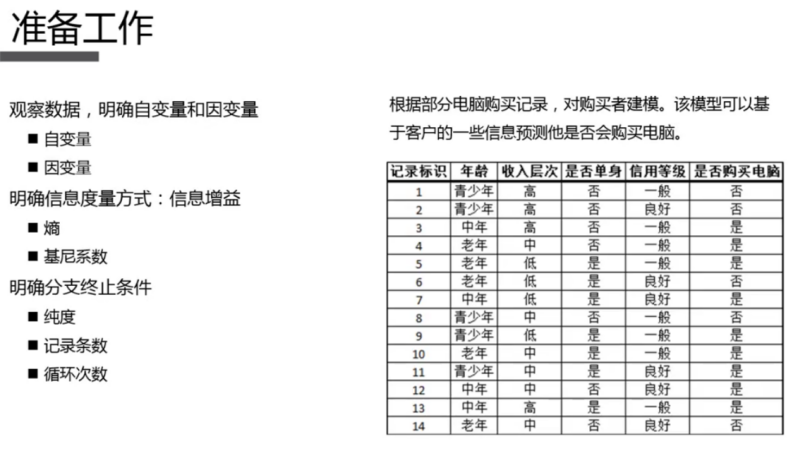
l 数据
字段说明:
是否见面, 年龄 是否帅 收入(2 高 1 中等 0 少) 是否是程序员
| label,age,handsome,salary,programmer不见面,32,1,2,0不见面,25,1,1,0见面,29,1,1,1见面,24,1,2,0不见面,31,1,2,0见面,35,1,1,1不见面,30,0,2,0不见面,31,1,2,0见面,30,1,1,1见面,21,1,2,0不见面,21,1,1,0见面,21,1,1,1不见面,29,0,1,1不见面,29,1,0,1不见面,29,0,1,1见面,30,1,2,0不见面,32,1,1,0见面,27,1,2,1见面,29,1,2,0见面,25,1,1,1不见面,23,0,1,1 |
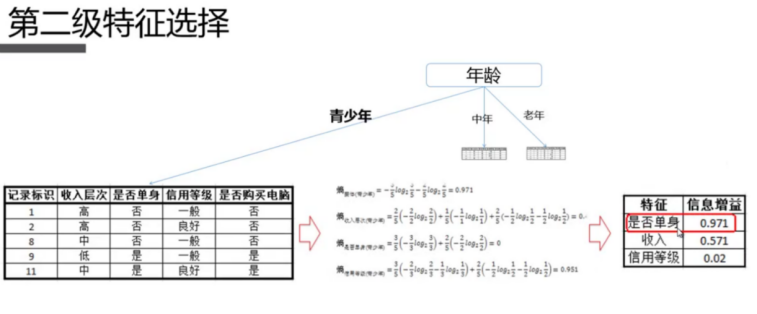
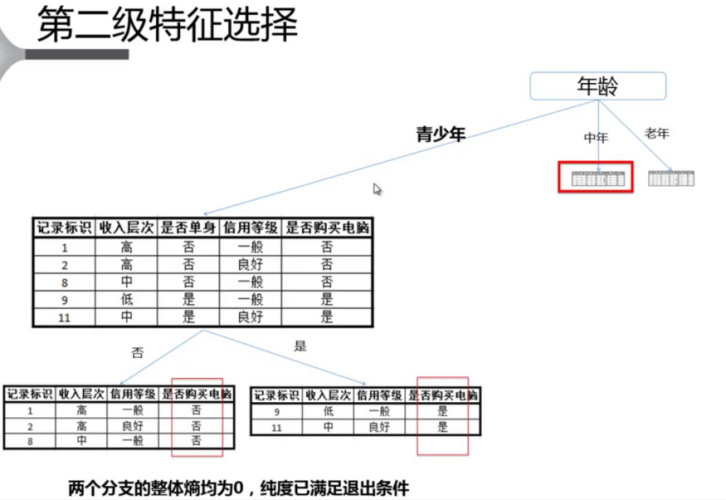
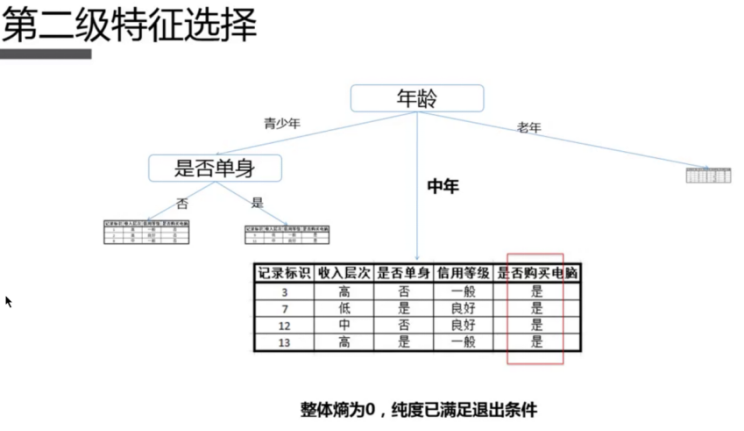
2.5.2 算法原理
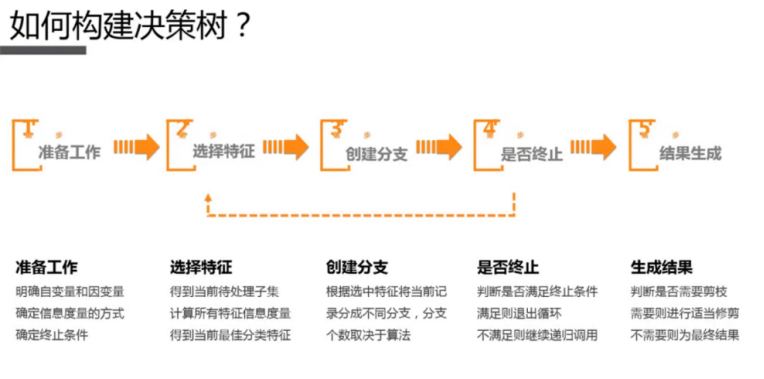


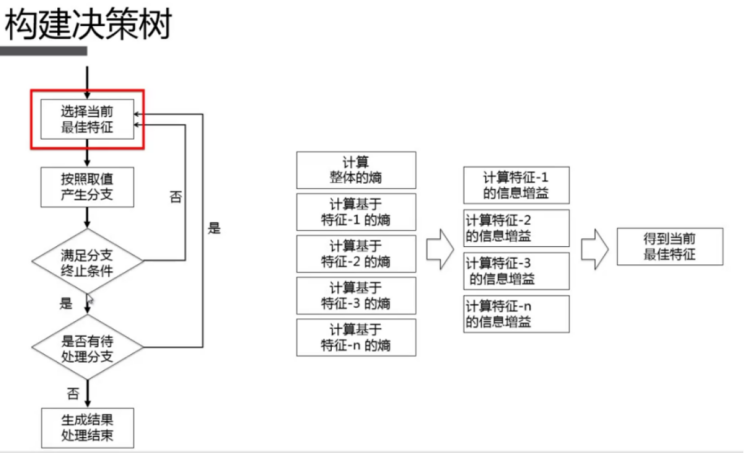
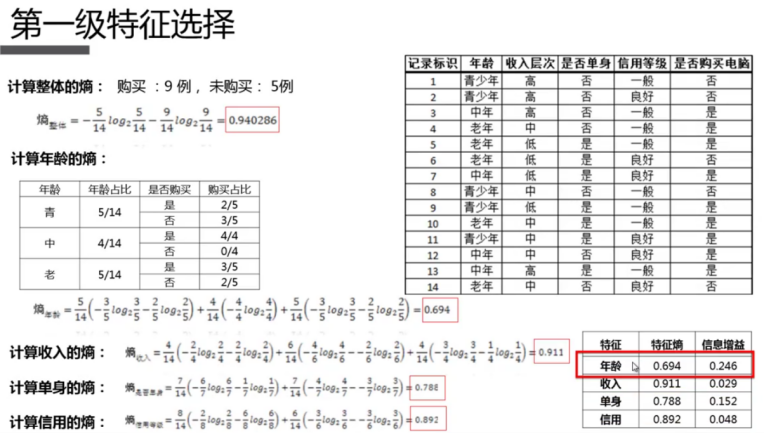

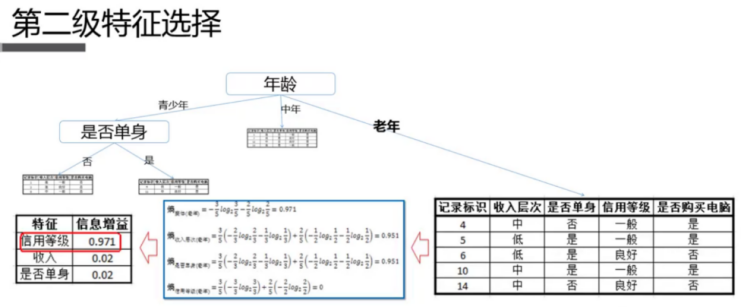
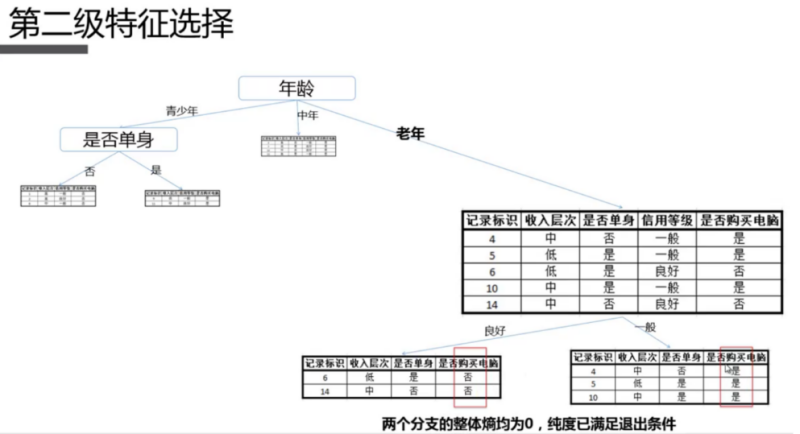
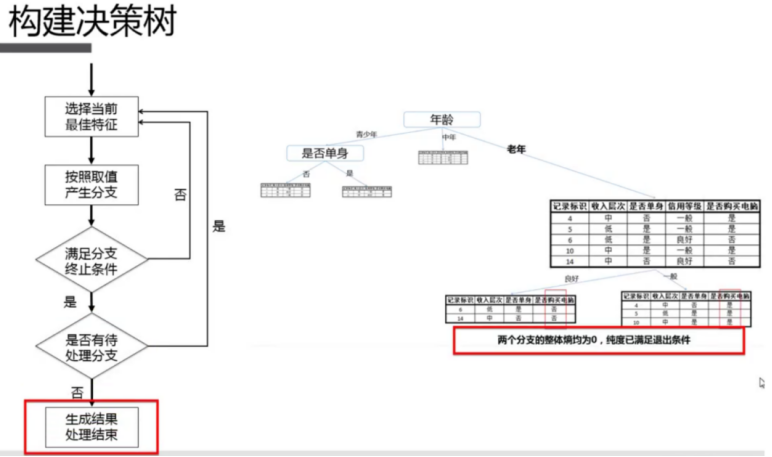
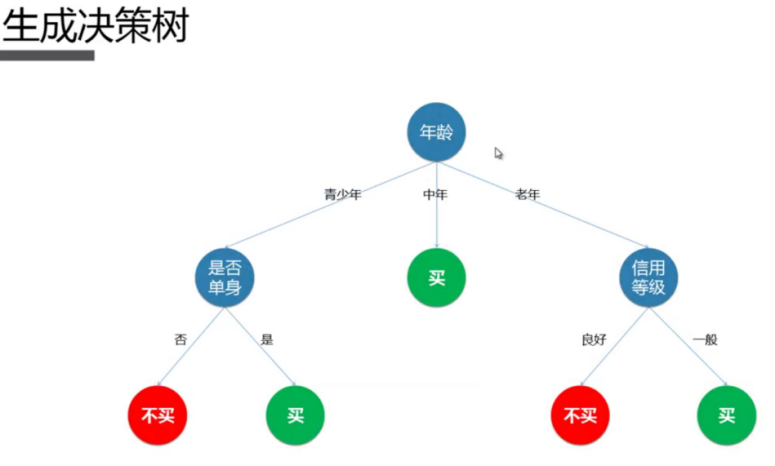
2.5.3 代码实现
| from pyspark.ml import Pipelinefrom pyspark.ml.classification import DecisionTreeClassifierfrom pyspark.ml.feature import StringIndexer, VectorAssembler, IndexToStringfrom pyspark.ml.evaluation import MulticlassClassificationEvaluatorfrom pyspark.sql import SparkSessionif __name__ == "__main__": spark = SparkSession \ .builder \ .appName("pyspark") \ .master("local[*]") \ .config("spark.sql.shuffle.partitions", "2") \ .getOrCreate() data = spark.read.format("csv") \ .option("sep", ",") \ .option("header", "true") \ .option("inferSchema", "true") \ .load("data/appointment.data") data.show() data.printSchema() # 标签数值化 stringIndexer = StringIndexer() \ .setInputCol("label") \ .setOutputCol("label_Indexer") stringIndexerModel = stringIndexer.fit(data) # 特征向量化 vectorAssembler = VectorAssembler() \ .setInputCols(["age", "handsome", "salary", "programmer"]) \ .setOutputCol("features") decisionTreeClassifier = DecisionTreeClassifier() \ .setFeaturesCol("features") \ .setLabelCol("label_Indexer") \ .setPredictionCol("predict_Indexer") \ .setImpurity("gini") \ .setMaxDepth(5) # 还原标签列(预测的是数字,要还原成字符串) indexToString = IndexToString()\ .setInputCol("predict_Indexer")\ .setOutputCol("predict_String")\ .setLabels(stringIndexerModel.labels) # 划分数据集 (trainSet, testSet) = data.randomSplit(weights=[0.8,0.2],seed=100) # 构建pipeline Pipeline = Pipeline().setStages([stringIndexerModel, vectorAssembler, decisionTreeClassifier, indexToString]) # 训练模型 model = Pipeline.fit(trainSet) # 进行预测 predictions = model.transform(testSet) predictions.show() # 模型评估 evaluator = MulticlassClassificationEvaluator(labelCol="label_Indexer", predictionCol="predict_Indexer", metricName="accuracy") accuracy = evaluator.evaluate(predictions) print("测试集错误率为: %f" % (1.0 - accuracy)) # 查看模型决策过程 print("模型决策过程为: \n %s" % model.stages[2].toDebugString) |















 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









