









0x00 正文
最近,在处理中文编码的数据的时候,遇到了一些还是令人头疼的问题。
乱码!
乱码!!
乱码!!!
稍微整理一下处理过程,顺带着记录一下解决方案啥的……
0x01 文本转码
最初,拿到很多GB2312(Simplify)编码的HTML文件,稍微有点头疼,因为在Shell里打开一看,都是下面这样奇怪的东西
<p><span style="font-family: ; font-size: 14px;"> </span><span style="font-fami˨λ[H
pan></p>
<p><span style="font-family: ; font-size: 14px;"> 6 ҩӦ[H
θƤĤ</span></p>
<p><span style="font-family: ; font-size: 14px;"> 7 ˨ʹ
�pan></p然后就encode/decode忙了半天都看不出来这到底是个啥……
于是就想方设法……把它们都变成UTF-8试试看
关键句: (需要import commands)
iconv -f gb18030 -t utf-8 FileA.html > FileB.html
将FileA.html由gb18030转换到UTF-8,输出至文件FileB.html
完整转换代码如下:
# -*- coding: gbk -*-
from bs4 import BeautifulSoup
from multiprocessing import Pool
import os
import re
import sys
import urllib2
import commands
import ConfigParser
def CheckTitle(soup) :
pos = 0
for p in soup.find_all('p'):
if pos == 1 :
curp = p
return curp.get_text().encode('utf-8')
else :
pos = pos + 1
def GetFileList() :
FileList = []
for root,dirs,files in os.walk("./html/"):
for filename in files:
FileList.append(filename)
# print filename
return FileList
if __name__ == '__main__' :
FileList = GetFileList()
for each in FileList:
infile = "./html/" + each
outfile = "./html-UTF/" + each
command = 'iconv -f gb18030 -t utf-8 ' + str(infile) + ' > ' + str(outfile)
# print command
(status, output) = commands.getstatusoutput(command)
l.Notice("Status: %s\nOutput: %s" % (str(status), str(output)))代码解释:遍历当前目录下的html文件夹,将其中所有的文件转换编码之后输出至html-UTF文件夹中,命名为与原先同名的文件
0x02 中文字符的split用法
获得了中文字符串之后,想要用split函数将其按逗号分号和句号等分割成小短句方便处理,然而,将中文字符中的逗号分号句号等为split函数传参的时候,会出现问题,一万个报错,大概意思都是编码问题:不能出现在position多少到多少之间blablabla……
那么,该怎么办呢
像我这样转成了UTF-8的html中提取的中文字符串,python文件头上如果加上#-*- coding: UTF-8 -*-,python在判断传参的中文字符的时候就可以编码正确了,顺手再写一个多字符匹配分割的demo备忘:
#-*- coding: UTF-8 -*-
import os
import re
import sys
import commands
import ConfigParser
def my_split(s, seps):
res = [s]
for sep in seps:
s, res = res, []
for seq in s:
res += seq.split(sep)
return res
if __name__ == '__main__' :
inputText = "今天天气不错。啥?下雨了!12345"
txt = inputText.strip()
mylist = my_split(txt,['\n','\r','\t',',',';',',','。',';'])0x03 正确获得中文字符串的len()
通常,我们需要知道某个中文字符串的长度,然而我们查看的时候,由于编码的问题,往往长度会变为需求值的整数倍(倍数与编码类型有关,刚刚在Python中测试了len(str)是中文字数的3倍,这个很有趣,到时候可以去查一查具体何种编码占多少个字符位置),如下为C++中的测试
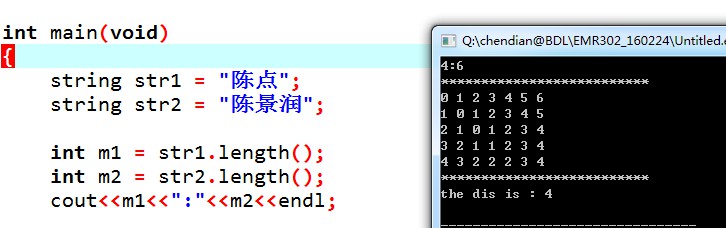
那么在Python中我们该如何获得正确的中文字符个数呢?
我们可以decode一下,将字符串变为当前python所用的编码方式,示例如下:
# s1,s2 请自主获取,本人是读的`UTF-8`编码文件中的字符串
str1,str2 = s1.decode('utf-8'),s2.decode('utf-8')
print len(s1,s2)
print len(str1,str2)
print s1,s2,'\n',str1,str20x04 Shell中的乱码现象
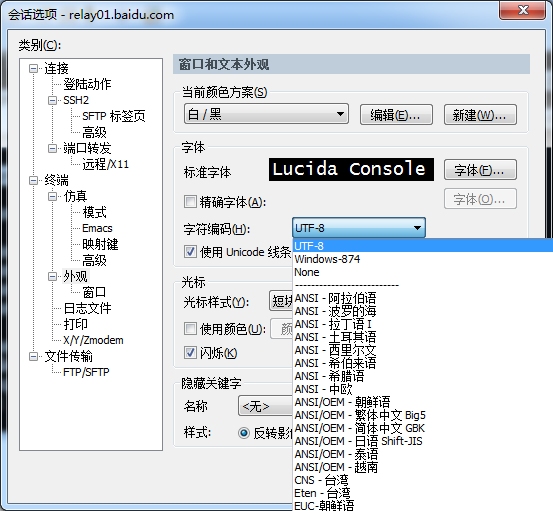
“我编码都是对的,直接打开也正常,为什么在Shell里看的就都是乱码呢?”
嘛,你可以试试更改一下会话选项中的字符编码哦,可能只是你的Shell会话的编码设置得不对应罢了~
0x05 等以后遇到新的问题再接着写吧~
编码真是博大精深,Python要是没有编码问题这个世界该多美好呀QwQ

















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











