







TensorFlow Fold is a library for creating TensorFlow models that consume structured data, where the structure of the computation graph depends on the structure of the input data. For example, this model implements TreeLSTMs for sentiment analysis on parse trees of arbitrary shape/size/depth.
Fold implements dynamic batching. Batches of arbitrarily shaped computation graphs are transformed to produce a static computation graph. This graph has the same structure regardless of what input it receives, and can be executed efficiently by TensorFlow.
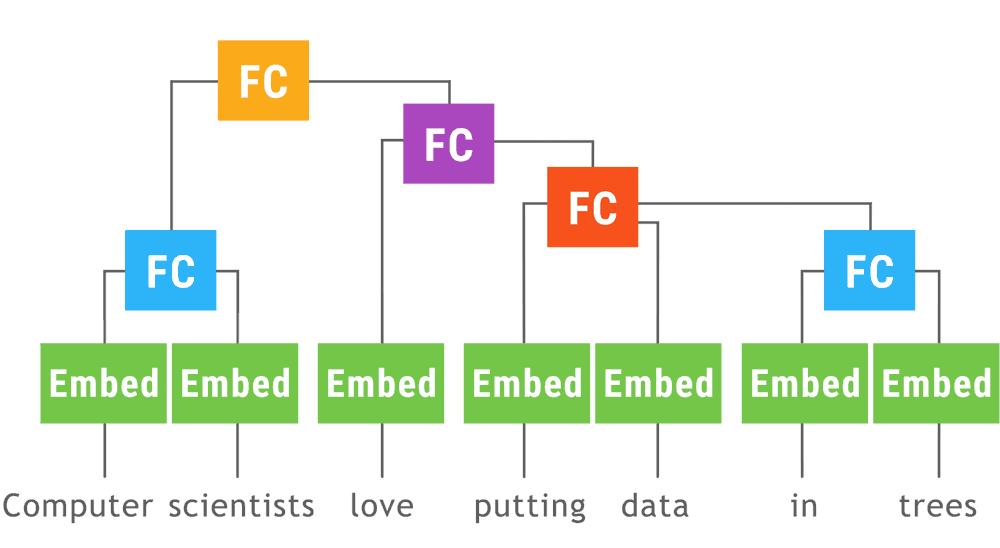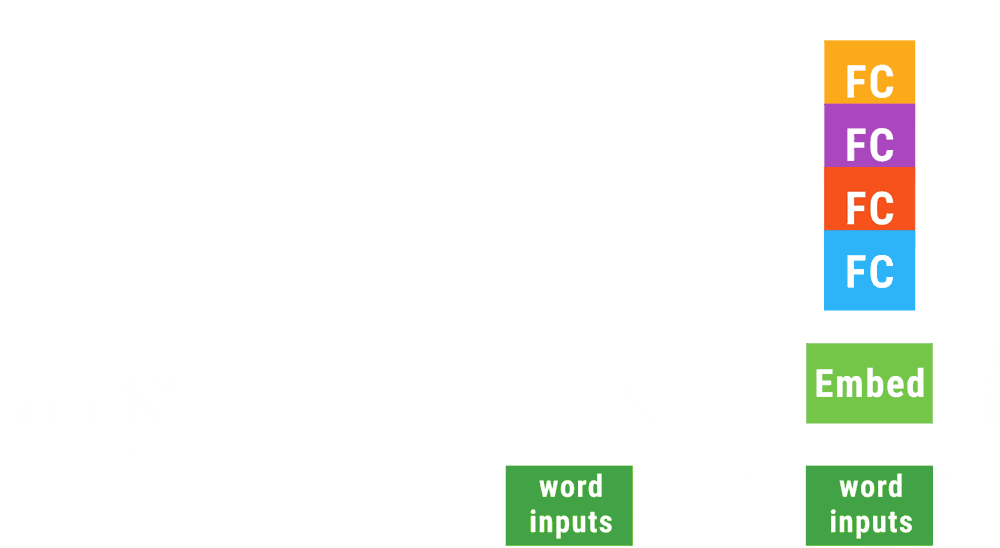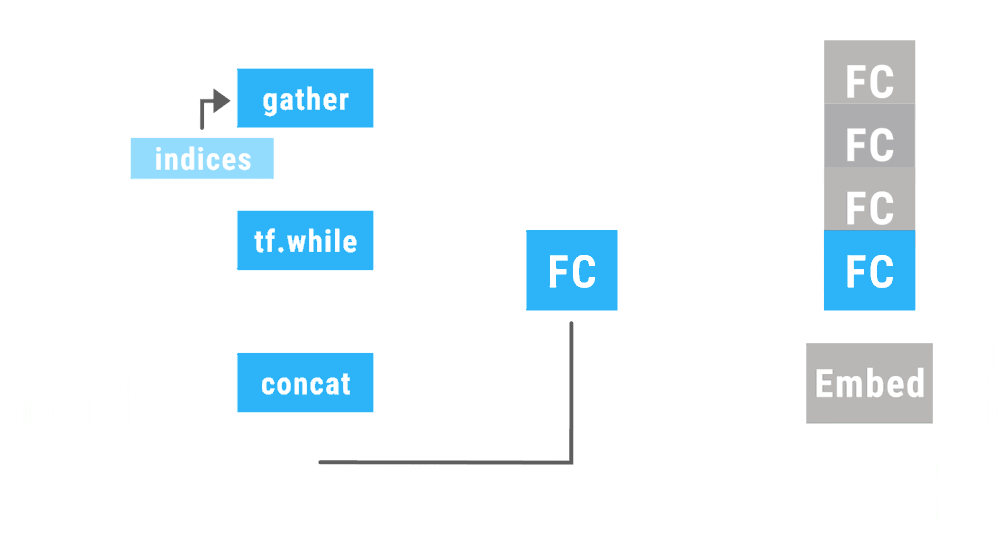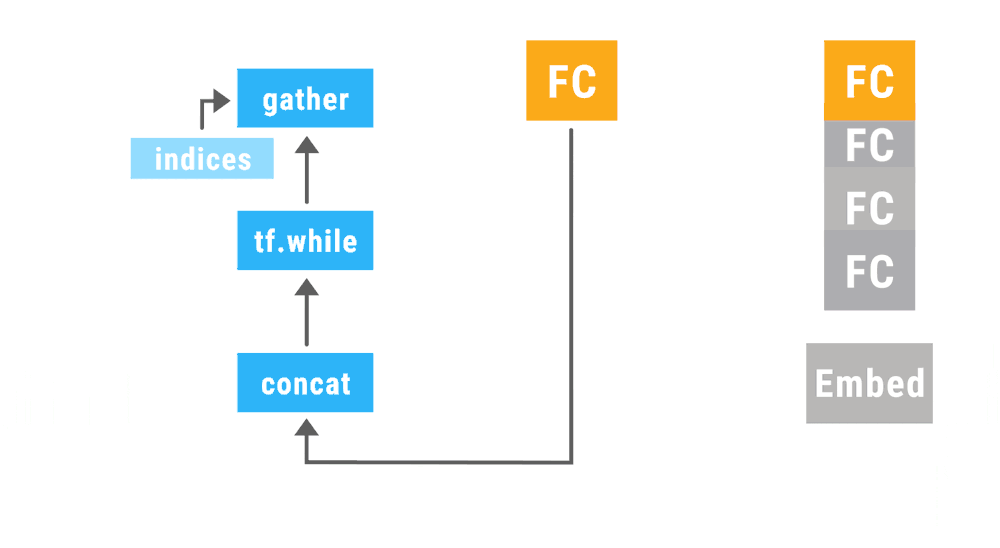
This animation shows a recursive neural network run with dynamic batching. Operations of the same type appearing at the same depth in the computation graph (indicated by color in the animiation) are batched together regardless of whether or not they appear in the same parse tree. The Embed operation converts words to vector representations. The fully connected (FC) operation combines word vectors to form vector representations of phrases. The output of the network is a vector representation of an entire sentence. Although only a single parse tree of a sentence is shown, the same network can run, and batch together operations, over multiple parse trees of arbitrary shapes and sizes. The TensorFlow concat, while_loop, and gather ops are created once, prior to variable initialization, by Loom, the low-level API for TensorFlow Fold.
If you'd like to contribute to TensorFlow Fold, please review the contribution guidelines.
TensorFlow Fold is not an official Google product.
————————————————————————————————————————————————————————————————————
TensorFlow_Fold 是在TensorFlow下的一个新的(分支?框架?)
其特点在于更加简化了TF的编码以及对于不定长输入处理的尝试。
虽说目前网络上教程啥的都挺少,但是既然要用到就得学学看,先大致整理了一些在ipynb里的输入输出,各类具体解释日后再写~
学习笔记如下,内含内容稍微整理了个ppt,不要你们积分,随意拿去看看吧:
http://download.csdn.net/download/okcd00/9791232
(偶然间看到自己突然多了很多C币,然后发现这篇文章的积分需求不知何时被改成5了……
我真的设置的是0,放在这里只是为了方便下载的,现在发现无法改回0了,对于之前下载的各位十分抱歉……)
# -*- encoding: utf8 -*-
# ========================================================
# Copyright (C) 2017 All rights reserved.
#
# filename : TFFTest.py
# author : chendian / okcd00@qq.com
# date : 2017-03-23
# desc : Tutorial Self-Learning
# ========================================================
# https://github.com/tensorflow/fold/blob/master/tensorflow_fold/g3doc/py/td.md
import tensorflow as tf
import tensorflow_fold as td
# Basic Form: Blocks
scalar_block = td.Scalar()
vector3_block = td.Vector(3)
# Function for describe blocks
def block_info(block):
print("%s: %s -> %s" % (block, block.input_type, block.output_type))
# Stucture of blocks
block_info(scalar_block)
block_info(vector3_block)
"""
<td.Scalar dtype='float32'>: PyObjectType() -> TensorType((), 'float32')
<td.Vector dtype='float32' size=3>: PyObjectType() -> TensorType((3,), 'float32')
"""
# eval: Function for testing with custom input
scalar_block.eval(10)
vector3_block.eval([1,2,3])
"""
array(10.0, dtype=float32)
array([ 1., 2., 3.], dtype=float32)
"""
# We can compose simple blocks together with Record
record_block = td.Record({'foo': scalar_block, 'bar': vector3_block})
block_info(record_block)
record_block.eval({'foo': 1, 'bar': [2, 3, 4]})
"""
<td.Record ordered=False>: PyObjectType() -> TupleType(TensorType((3,), 'float32'), TensorType((), 'float32'))
(array([ 2., 3., 4.], dtype=float32), array(1.0, dtype=float32))
"""
# wire them up to create pipelines using the >> operator
record2vec_block = record_block >> td.Concat()
record2vec_block.eval({'foo': 1, 'bar': [5, 7, 9]})
""" array([ 5., 7., 9., 1.], dtype=float32) """
# the Function block lets you convert a TITO (Tensors In, Tensors Out) function to a block
negative_block = record2vec_block >> td.Function(tf.negative)
negative_block.eval({'foo': 1, 'bar': [5, 7, 9]})
""" array([-5., -7., -9., -1.], dtype=float32) """
# when our inputs contain sequences of indeterminate length. The Map block comes in handy here
# There's no TF type for sequences of indeterminate length, but Fold has one
map_scalars_block = td.Map(td.Scalar())
jagged_block = td.Map(td.Map(td.Scalar()))
block_info(map_scalars_block)
""" <td.Map element_block=<td.Scalar dtype='float32'>>: None -> SequenceType(TensorType((), 'float32')) """
# with Map to create a sequence, or with Record to create a tuple
seq_of_tuples_block = td.Map(td.Record({'foo': td.Scalar(), 'bar': td.Scalar()}))
tuple_of_seqs_block = td.Record({'foo': td.Map(td.Scalar()), 'bar': td.Map(td.Scalar())})
seq_of_tuples_block.eval([{'foo': 1, 'bar': 2}, {'foo': 3, 'bar': 4}])
tuple_of_seqs_block.eval({'foo': range(3), 'bar': range(7)})
"""
[(array(2.0, dtype=float32), array(1.0, dtype=float32)),
(array(4.0, dtype=float32), array(3.0, dtype=float32))]
([array(0.0, dtype=float32),
array(1.0, dtype=float32),
array(2.0, dtype=float32),
array(3.0, dtype=float32),
array(4.0, dtype=float32),
array(5.0, dtype=float32),
array(6.0, dtype=float32)],
[array(0.0, dtype=float32),
array(1.0, dtype=float32),
array(2.0, dtype=float32)])
"""
# The general form of such functions is Reduce
((td.Map(td.Scalar()) >> td.Sum()).eval(range(10)),
(td.Map(td.Scalar()) >> td.Min()).eval(range(10)),
(td.Map(td.Scalar()) >> td.Max()).eval(range(10)))
(td.Map(td.Scalar()) >> td.Reduce(td.Function(tf.multiply))).eval(range(1,10))
"""
(array(45.0, dtype=float32),
array(0.0, dtype=float32),
array(9.0, dtype=float32))
array(362880.0, dtype=float32)
"""
# If the order of operations is important, you should use Fold instead of Reduce
((td.Map(td.Scalar()) >> td.Fold(td.Function(tf.divide), tf.ones([]))).eval(range(1,5)),
(td.Map(td.Scalar()) >> td.Reduce(td.Function(tf.divide), tf.ones([]))).eval(range(1,5)))
"""
(array(0.0416666679084301, dtype=float32),
array(0.6666666865348816, dtype=float32))
"""
# Try some learning.
def reduce_net_block():
net_block = td.Concat() >> td.FC(20) >> td.FC(1, activation=None) >> td.Function(lambda xs: tf.squeeze(xs, axis=1))
return td.Map(td.Scalar()) >> td.Reduce(net_block)
# About FC(Fully-Connected) / Example with MNIST
mnist_model = (td.InputTransform(lambda s: [ord(c) / 255.0 for c in s]) >>
td.Vector(784) >> # convert python list to tensor
td.Function(td.FC(100)) >> # layer 1, 100 hidden units
td.Function(td.FC(100))) # layer 2, 100 hidden units
# About squeeze
"""
The tf.squeeze() function returns a tensor with the same value as its first argument, but a different shape. It removes dimensions whose size is one. For example, if t is a tensor with shape [batch_num, 1, elem_num] (as in your question), tf.squeeze(t, [1]) will return a tensor with the same contents but size [batch_num, elem_num]
"""
# A Function for Generating Data
def random_example(fn):
length = random.randrange(1, 10)
data = [random.uniform(0,1) for _ in range(length)]
result = fn(data)
return data, result
random_example(sum)
random_example(min)
"""
([0.787305870095568,
0.22965378372211998,
0.37373230100201726,
0.5763790512875622,
0.8213490322728823,
0.8670031890415114],
3.655423227421661)
([0.6092255329819952, 0.3401567642529808, 0.20512903038956665],
0.20512903038956665)
"""
# train a neural network to approximate a reduction function of our choosing
sess = tf.InteractiveSession()
def train(fn, batch_size=100):
net_block = reduce_net_block()
# eval() repeatedly is super-slow and cannot exploit batch-wise parallelism,
# so we create a Compiler
# https://github.com/tensorflow/fold/blob/master/tensorflow_fold/g3doc/running.md
compiler = td.Compiler.create((net_block, td.Scalar()))
y, y_ = compiler.output_tensors
loss = tf.nn.l2_loss(y - y_)
train = tf.train.AdamOptimizer().minimize(loss)
sess.run(tf.global_variables_initializer())
validation_fd = compiler.build_feed_dict(random_example(fn) for _ in range(1000))
for i in range(2000):
sess.run(train, compiler.build_feed_dict(random_example(fn) for _ in range(batch_size)))
if i % 100 == 0:
print(i, sess.run(loss, validation_fd))
return net_block
sum_block = train(sum)
sum_block.eval([1, 1])
"""
(0, 3709.2959),(100, 117.03122),(200, 75.517761),(300, 39.155235),(400, 10.953562)
(500, 4.590332),(600, 2.8660746),(700, 2.0546255),(800, 1.573489),(900, 1.2537044)
(1000, 1.0065227),(1100, 0.82658422),(1200, 0.67432761),(1300, 0.55223799),(1400, 0.46296757)
(1500, 0.38158983),(1600, 0.316338),(1700, 0.26881805),(1800, 0.22481206),(1900, 0.20074199)
array(2.006655216217041, dtype=float32)
"""
# The following example code implements a hierarchical LSTM,
# something that is easy to do in Fold, but hard to do in TensorFlow:
# Create RNN cells using the TensorFlow RNN library
char_cell = td.ScopedLayer(tf.contrib.rnn.BasicLSTMCell(num_units=16), 'char_cell')
word_cell = td.ScopedLayer(tf.contrib.rnn.BasicLSTMCell(num_units=32), 'word_cell')
# character LSTM converts a string to a word vector
char_lstm = (td.InputTransform(lambda s: [ord(c) for c in s]) >>
td.Map(td.Scalar('int32') >>
td.Function(td.Embedding(128, 8))) >>
td.RNN(char_cell))
# word LSTM converts a sequence of word vectors to a sentence vector.
word_lstm = td.Map(char_lstm >> td.GetItem(1)) >> td.RNN(word_cell)















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











