







Abstract
YOLO已成为机器人、无人驾驶汽车和视频监控应用的核心实时目标检测系统。我们对YOLO的发展进行了全面的分析,研究了从最初的YOLO到YOLOv8的每次迭代中的创新和贡献。我们首先描述标准指标和后处理;然后,我们讨论了网络架构的主要变化和每个模型的训练技巧。最后,我们总结了YOLO发展的重要经验教训,并对其未来发展进行了展望,强调了增强实时目标检测系统的潜在研究方向。
1 Introduction
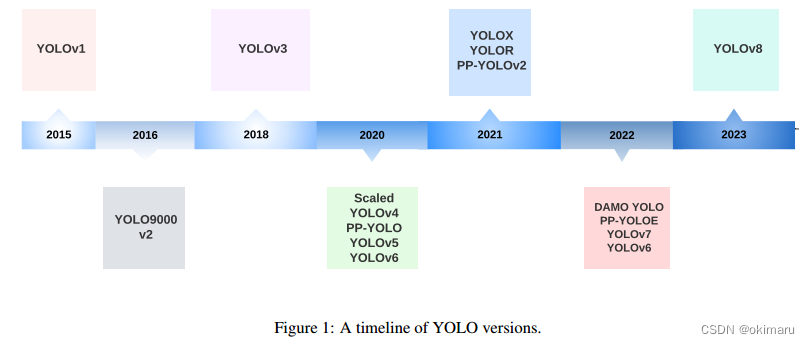
实时目标检测已成为众多应用中的关键组成部分,涵盖自动驾驶汽车、机器人、视频监控和增强现实等各个领域。在各种目标检测算法中,YOLO (You Only Look Once)框架以其出色的速度和准确性平衡而脱颖而出,能够快速可靠地识别图像中的目标。自成立以来,YOLO家族经历了多次迭代,每次迭代都建立在以前的版本之上,以解决局限性并提高性能(见图1)。本文旨在全面回顾YOLO框架的发展,从最初的YOLOv1到最新的YOLOv8,阐明每个版本的关键创新、差异和改进。
本文首先探讨了原始YOLO模型的基本概念和体系结构,为YOLO家族的后续发展奠定了基础。接下来,我们将深入研究从YOLOv2到YOLOv8的每个版本中引入的改进和增强。这些改进包括网络设计、损失函数修改、锚盒适应和输入分辨率缩放等各个方面。通过研究这些发展,我们的目标是全面了解YOLO框架的发展及其对目标检测的影响。
除了讨论每个YOLO版本的具体进步之外,本文还强调了在整个框架开发过程中出现的速度和准确性之间的权衡。这强调了在选择最合适的YOLO模型时考虑特定应用程序的上下文和需求的重要性。
最后,我们展望了YOLO框架的未来方向,触及了进一步研究和开发的潜在途径,这将影响实时目标检测系统的持续进展。
2 YOLO在不同领域的应用
YOLO的实时目标检测能力在自动驾驶车辆系统中非常宝贵,可以快速识别和跟踪各种物体,如车辆、行人[1,2]、自行车和其他障碍物[3,4,5,6]。
这些能力已经应用于许多领域,包括用于监控的视频序列中的动作识别[7][8]、运动分析[9]和人机交互[10]。
YOLO模型已在农业中用于农作物[11,12]、病虫害[13]的检测和分类,协助实现精准农业技术和农业流程自动化。它们也适用于生物识别、安全和面部识别系统中的面部检测任务[14,15]。
在医学领域,YOLO已被用于癌症检测[16,17]、皮肤分割[18]、药丸识别[19],提高了诊断的准确性,提高了治疗的效率。在遥感领域,它已被用于卫星和航空图像中的目标检测和分类,有助于土地利用制图、城市规划和环境监测[20,21,22,23]。
安防系统集成了YOLO模型,用于实时监控和分析视频馈送,从而可以快速发现可疑活动[24]、保持社交距离和检测口罩[25]。这些模型还被应用于表面检测,以检测缺陷和异常,加强制造和生产过程中的质量控制[26,27,28]。
在交通应用中,YOLO模型已被用于车牌检测[29]和交通标志识别[30]等任务,有助于智能交通系统和交通管理解决方案的发展。它们已被用于野生动物检测和监测,以识别濒危物种,用于生物多样性保护和生态系统管理[31]。最后,YOLO已广泛应用于机器人应用[32,33]和无人机目标检测[34,35]。
3目标检测指标与非最大抑制(NMS)
平均精度(AP),传统上称为平均平均精度(mAP),是评估目标检测模型性能的常用度量。它测量所有类别的平均精度,提供一个单一的值来比较不同的模型。COCO数据集没有区分AP和AP。在本文的其余部分,我们将把这个指标称为AP。
在YOLOv1和YOLOv2中,用于训练和基准测试的数据集是PASCAL VOC 2007和VOC 2012[36]。然而,从YOLOv3开始,使用的数据集是Microsoft COCO (Common Objects in Context)[37]。对于这些数据集,AP的计算方法不同。下面几节将讨论AP背后的基本原理,并解释如何计算AP。
3.1 How AP works?
3.2 Computing AP
3.3 Non-Maximum Suppression (NMS)
非最大抑制(NMS)是一种用于目标检测算法的后处理技术,目的是减少重叠边界框的数量,提高整体检测质量。目标检测算法通常会在同一目标周围生成多个具有不同置信度分数的边界框。NMS过滤掉冗余和不相关的边界框,只保留最准确的边界框。算法1描述了这个过程。图3显示了包含多个重叠边界框的对象检测模型的典型输出和NMS后的输出。

4 YOLO: You Only Look Once
Joseph Redmon等人的YOLO发表于CVPR 2016[38]。它首次提出了一种实时的端到端目标检测方法。YOLO的意思是“你只看一次”,指的是它能够通过一次网络来完成检测任务,而不是以前的方法,要么使用滑动窗口,然后使用分类器,每个图像需要运行数百或数千次,或者更先进的方法,将任务分为两步,其中第一步检测具有对象或区域建议的可能区域,第二步对建议运行分类器。此外,YOLO使用更直接的基于回归的输出来预测检测输出,而Fast R-CNN[39]使用两个单独的输出,概率分类和框坐标回归。
4.1 How YOLOv1 works?
YOLOv1统一了目标检测步骤,同时检测所有的边界框。为了实现这一点,YOLO将输入图像划分为S × S网格,并预测同一类的B个边界框,以及每个网格元素对C个不同类的置信度。每个边界框预测由5个值组成:P c;软;通过;黑洞;bw,其中pc是盒子的置信度分数,它反映了模型对盒子中包含一个对象的置信度以及盒子的准确性。bx和by坐标是相对于网格单元格的框的中心,bh和bw是相对于完整图像的框的高度和宽度。YOLO的输出是S × S × (B × 5 + C)张量,可选地跟随非最大抑制(NMS)来去除重复检测。
在最初的YOLO论文中,作者使用了包含20个类(C = 20)的PASCAL VOC数据集[36];一个7 × 7的网格(S = 7),每个网格元素最多2个类(B = 2),给出7 × 7 × 30的输出预测。
图4显示了一个简化的输出向量,考虑了一个3乘3的网格、3个类,每个网格一个类代表8个值。在这个简化的情况下,YOLO的输出将是3 × 3 × 8。
YOLOv1在PASCAL VOC2007数据集上的平均精度(AP)为63.4。
4.2 YOLOv1 Architecture
YOLOv1架构包括24个卷积层,然后是两个完全连接的层,用于预测边界框坐标和概率。除最后一层使用线性激活函数外,所有层都使用漏整流线性单元激活[40]。受GoogLeNet[41]和Network in Network[42]的启发,YOLO使用1 × 1卷积层来减少特征映射的数量,并保持相对较低的参数数量。作为激活层,表1描述了YOLOv1体系结构。作者还介绍了一个更轻的模型,称为Fast YOLO,由9个卷积层组成。
4.3 YOLOv1 Training
作者使用ImageNet数据集以224 × 224的分辨率预训练了YOLO的前20层[43]。然后,他们添加了随机初始化权重的最后四层,并使用PASCAL VOC 2007和VOC 2012数据集[36]以448 × 448的分辨率对模型进行了精细调整,以增加细节,从而更准确地检测目标。
对于增强,作者使用最多20%输入图像大小的随机缩放和平移,以及随机曝光和饱和度,在HSV色彩空间中,上限因子为1.5。
4.4 YOLOv1 Strengths and Limitations
YOLO的简单架构,以及其新颖的全图像单次回归,使其比现有的目标检测器更快,从而实现实时性能。
然而,尽管YOLO的执行速度比任何目标检测器都快,但与Fast R-CNN等最先进的方法相比,定位误差更大[39]。造成这种限制的主要原因有三个:1。它最多只能检测到网格单元中两个同类的物体,这限制了它预测附近物体的能力。
2. 它很难预测训练数据中没有出现的长宽比物体。
3. 由于下采样层,它从粗糙的目标特征中学习。
5 YOLOv2: Better, Faster, and Stronger
YOLOv2由Joseph Redmon和Ali Farhadi在CVPR 2017上发表[44]。它对原来的YOLO进行了一些改进,使其更好,保持相同的速度,也更强大-能够检测9000个类别!改进如下:
1.所有卷积层的批处理归一化提高了收敛性,并作为正则化器减少过拟合。
2. 高分辨率的分类器。与YOLOv1一样,他们使用ImageNet在224 × 224的分辨率下对模型进行预训练。然而,这一次,他们在ImageNet上调整了10个epoch的模型,分辨率为448 × 448,提高了网络在更高分辨率输入下的性能。
3. 完全卷积。他们去掉了密集的层,使用了一个完全卷积的架构。
4. 使用锚框来预测边界框。它们使用一组先验框或锚框,锚框是具有预定义形状的框,用于匹配对象的原型形状,如图6所示。为每个网格单元定义多个锚框,系统预测每个锚框的坐标和类。网络输出的大小与每个网格单元的锚盒数量成正比。
5. 维集群。选择好的先验框有助于网络学习预测更准确的边界框。作者在训练边界盒上运行k-means聚类来找到好的先验。他们选择了五个先前的盒子,在召回率和模型复杂性之间进行了很好的权衡。
6. 直接位置预测。与其他预测偏移量的方法[45]不同,YOLOv2遵循相同的原理,预测相对于网格单元的位置坐标。网络为每个单元格预测5个边界框,每个边界框有5个值tx、ty、tw、th和to,其中to相当于YOLOv1中的P c,最终得到边界框坐标,如图7所示。
7. Finner-grained特性。与YOLOv1相比,YOLOv2去掉一个池化层,得到416 × 416输入图像的13 × 13输出特征图或网格。YOLOv2还使用了一个通层,该通层采用26 × 26 × 512的特征映射,并通过将相邻的特征堆叠到不同的通道中来重新组织它,而不是通过空间子采样丢失它们。这将生成13 × 13 × 2048个通道维度的特征图,并与低分辨率的13 × 13 × 1024个特征图进行连接,得到13 × 13 × 3072个特征图。
8. 多尺度的训练。由于YOLOv2不使用完全连接的层,因此输入可以是不同的大小。
为了使YOLOv2对不同的输入大小具有鲁棒性,作者随机训练模型,每10批次改变输入大小——从320 × 320到608 × 608。
5.1 YOLOv2 Architecture
YOLOv2使用的骨干架构称为Darknet-19,包含19个卷积层和5个maxpooling层。与YOLOv1的架构类似,它的灵感来自于Network in Network[42],在3 × 3之间使用1 × 1的卷积来减少参数的数量。此外,如上所述,他们使用批归一化来正则化和帮助收敛。
表2显示了带有目标检测头的整个Darknet-19主干。使用PASCAL VOC数据集时,YOLOv2预测5个边界框,每个边界框有5个值和20个类。
对象分类头将最后四个卷积层替换为一个包含1000个过滤器的单个卷积层,然后是一个全局平均池化层和一个Softmax。
5.2 YOLO9000 is a stronger YOLOv2
作者在同一篇文章中介绍了一种训练联合分类和检测的方法。它使用COCO[37]中的检测标记数据学习边界框坐标和ImageNet中的分类数据,以增加可检测的类别数量。在训练过程中,他们将两个数据集结合起来,这样当使用检测训练图像时,它会反向传播检测网络,当使用分类训练图像时,它会反向传播体系结构的分类部分。结果是一个能够检测超过9000个类别的YOLO模型,因此名称为YOLO9000。
6 YOLOv3
YOLOv3[46]由Joseph Redmon和Ali Farhadi于2018年在ArXiv上发表。它包括重大变化和更大的架构,以与最先进的技术相媲美,同时保持实时性能。在下文中,我们描述了与YOLOv2相关的更改。
1. 边界框预测。与YOLOv2一样,该网络为每个边界框tx、ty、tw和th预测四个坐标;然而,这一次,YOLOv3使用逻辑回归预测每个边界框的对象得分。与地面真值重叠度最高的锚框得分为1,其余锚框得分为0。与Faster R-CNN[45]不同,YOLOv3只为每个ground truth对象分配一个锚框。同样,如果没有给对象分配锚盒,只会造成分类损失,不会造成定位损失和置信度损失。
2. 类的预测。他们没有使用softmax进行分类,而是使用二元交叉熵来训练独立的逻辑分类器,并将问题作为多标签分类。这种变化允许为同一个框分配多个标签,这可能发生在一些具有重叠标签的复杂数据集[47]上。例如,同一个对象可以是Person和Man。
3. 新的支柱。YOLOv3具有更大的特征提取器,由53个带有残差连接的卷积层组成。第6.1节更详细地描述了该体系结构。
4. 空间金字塔池(SPP)虽然在论文中没有提到,但作者还在主干中添加了一个修改后的SPP块[48],该块连接多个最大池化输出而不进行子采样(stride = 1),每个都具有不同的内核大小k × k,其中k = 1;5;9;允许更大的接受范围。这个版本被称为YOLOv3-spp,是性能最好的版本,AP50提高了2.7%。
5. 多尺度预测。与特征金字塔网络[49]类似,YOLOv3在三个不同的尺度上预测三个盒子。第6.2节详细描述了多尺度预测机制。
6. 边界框先验。与YOLOv2一样,作者也使用k-means来确定锚框的边界框先验。不同之处在于,在YOLOv2中,他们为每个单元格总共使用了五个先验框,而在YOLOv3中,他们为三个不同的尺度使用了三个先验框。
6.1 YOLOv3 Architecture
YOLOv3中呈现的架构主干称为Darknet-53。它用跨行卷积替换了所有的最大池化层,并添加了残差连接。总的来说,它包含53个卷积层。图8显示了体系结构的细节。
Darknet-53骨干网获得与ResNet-152相当的Top-1和Top-5精度,但几乎快了2倍。
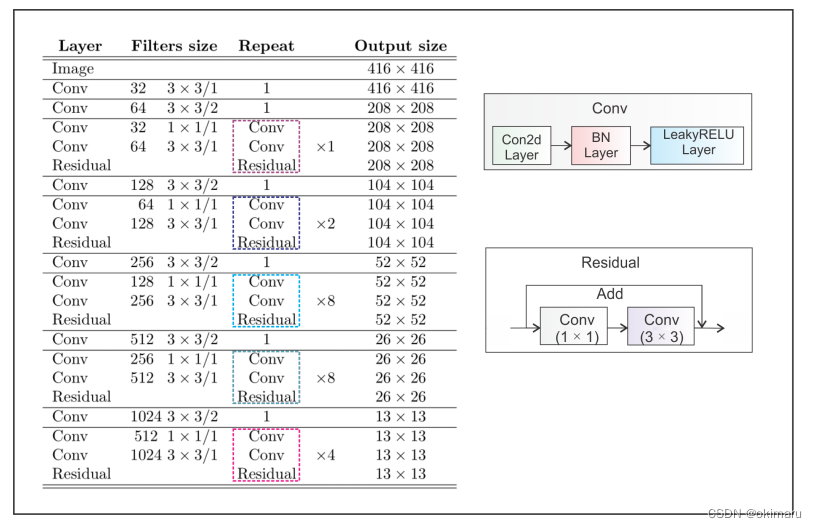
Figure 8: YOLOv3 Darknet-53 backbone. YOLOv3的体系结构由53个卷积层组成,每个卷积层都具有批处理归一化和Leaky ReLU激活。此外,残差连接将整个网络的1 × 1个卷积的输入与3 × 3个卷积的输出连接起来。这里展示的建筑只包括主干;它不包括由多尺度预测组成的探测头。
6.2 YOLOv3 Multi-Scale Predictions
除了更大的架构外,YOLOv3的一个基本特征是多尺度预测,即在多个网格大小下进行预测。这有助于获得更精细的细节框,并显着提高了对小物体的预测,这是以前版本的YOLO的主要弱点之一。
图9所示的多尺度检测架构的工作原理如下:标记为y1的第一个输出相当于YOLOv2的输出,其中一个13 × 13的网格定义了输出。第二个输出y2是将Darknet-53的(Res × 4)之后的输出与(Res × 8)之后的输出拼接而成。feature map的大小不同,分别是13 × 13和26 × 26,所以在拼接之前需要进行上采样操作。最后,使用上采样操作,第三个输出y3将26 × 26特征映射与52 × 52特征映射连接起来。
对于具有80个类别的COCO数据集,每个尺度提供一个形状为N ×N ×[3x(4+1+80)]的输出张量,其中N ×N为特征图(或网格单元)的大小,3表示每个单元的框数,4+1包括四个坐标和对象得分。
6.3 YOLOv3 Results
当YOLOv3发布时,目标检测的基准已经从PASCAL VOC改为Microsoft COCO[37]。因此,从这里开始,所有的yolo都在MS COCO数据集中进行评估。在20 FPS下,YOLOv3-spp的平均精度AP为36.2%,AP50为60.6%,达到了当时最先进的水平,速度提高了2倍。
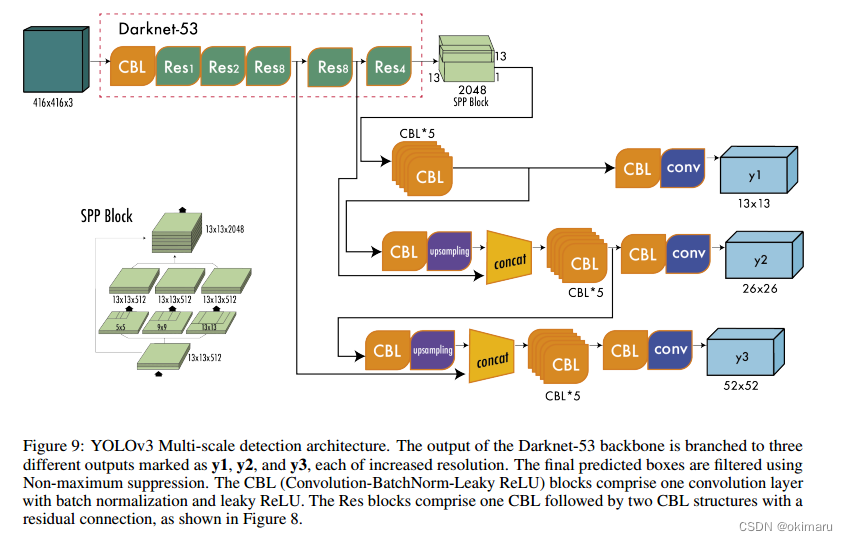
YOLOv3多尺度检测架构。Darknet-53主干网的输出分为三个不同的输出,分别标记为y1, y2和y3,每个输出都增加了分辨率。使用非最大抑制对最终的预测框进行过滤。CBL (convolutional - batchnorm - leaky ReLU)块由一个具有批处理归一化和leaky ReLU的卷积层组成。Res块包括一个CBL,后面跟着两个CBL结构和一个剩余连接,如图8所示。
7 Backbone, Neck, and Head
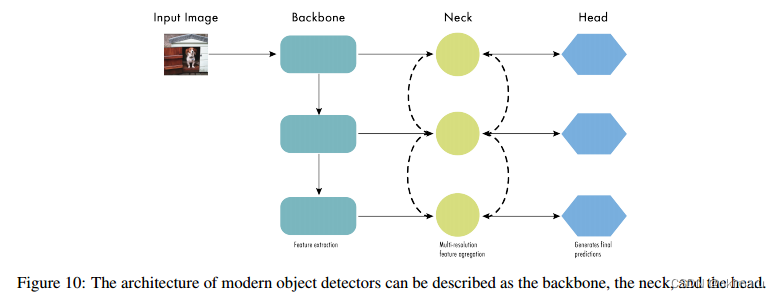
此时,目标探测器的结构开始被描述为三个部分:脊柱、颈部和头部。图10显示了一个高级的脊柱、颈部和头部图。
主干负责从输入图像中提取有用的特征。它通常是在大规模图像分类任务上训练的卷积神经网络(CNN),例如ImageNet。主干捕获不同尺度的分层特征,较低级的特征(如边缘和纹理)在较早的层中提取,较高级的特征(如对象部分和语义信息)在较深的层中提取。
颈部是连接脊柱和头部的中间部分。它对主干提取的特征进行聚合和细化,往往侧重于增强不同尺度的空间和语义信息。
颈部可能包括额外的卷积层、特征金字塔网络(FPN)[49]或其他机制来改善特征的表示。
头部是物体检测器的最终组成部分;它负责根据脊柱和颈部提供的特征做出预测。它通常由一个或多个特定于任务的子网组成,这些子网执行分类、定位以及最近的实例分割和姿态估计。头部处理颈部提供的特征,为每个候选对象生成预测。最后,一个后处理步骤,如非最大抑制(NMS),过滤掉重叠的预测,只保留最可靠的检测。
在YOLO模型的其余部分中,我们将使用脊柱、颈部和头来描述架构。
8 YOLOv4
9 YOLOv5
YOLOv5[72]于2020年由Glenn Jocher在YOLOv4发布几个月后发布。在撰写本文时,还没有关于YOLOv5的科学论文,但从代码中,我们知道它使用了YOLOv4部分中描述的许多改进,主要区别在于它是在Pytorch而不是Darknet中开发的。
YOLOv5是开源的,由Ultralytics积极维护,有250多个贡献者,并且经常有新的改进。YOLOv5易于使用、训练和部署。Ultralytics提供iOS和Android的移动版本,以及许多标签、培训和部署的集成。
YOLOv5提供5个缩放版本:YOLOv5n (nano)、YOLOv5s (small)、YOLOv5m (medium)、YOLOv5l (large)、YOLOv5x (extra large)。
撰写本文时发布的YOLOv5版本是v7.0,其中包括能够分类和实例分割的YOLOv5版本。
9.1 YOLOv5 Results
在MS COCO数据集test-dev 2017上进行评估,YOLOv5x在图像尺寸为640像素时实现了50.7%的AP。
使用32个批处理大小,它可以在NVIDIA V100上实现200 FPS的速度。使用1536像素的更大输入尺寸,YOLOv5实现了55.8%的AP。
10 Scaled-YOLOv4
11 YOLOR
12 YOLOX
13 YOLOv6
13.1 YOLOv6 Results
14 YOLOv7
14.1 Comparison with YOLOv4 and YOLOR
14.2 YOLOv7 Results
15 DAMO-YOLO
16 YOLOv8
17 PP-YOLO, PP-YOLOv2, and PP-YOLOE
18 Discussion
19 The future of YOLO
随着“千年发展目标”框架的不断发展,我们预计以下趋势和可能性将影响未来的发展:
结合最新技术。研究人员和开发人员将利用深度学习、数据增强和训练技术方面的最新方法,继续完善YOLO架构。这个持续的创新过程可能会提高模型的性能、健壮性和效率。
基准进化。目前用于评估目标检测模型的基准,COCO 2017,最终可能会被一个更先进、更具挑战性的基准所取代。这反映了前两个YOLO版本中使用的VOC 2007基准的转变,反映了随着模型变得更加复杂和准确,对更高要求的基准的需求。
YOLO模型及其应用的扩展。随着YOLO框架的发展,我们预计每年发布的YOLO模型数量将会增加,应用范围也会相应扩大。随着该框架变得更加通用和强大,它可能会被应用于更广泛的领域,从家用电器设备到自动驾驶汽车。
扩展到新的领域。YOLO模型有潜力将其功能扩展到物体检测和分割之外,扩展到视频中的物体跟踪和3D关键点估计等领域。随着这些模型的发展,它们可能成为解决更广泛的计算机视觉任务的新解决方案的基础。
对各种硬件的适应性。YOLO模型将进一步跨越硬件平台,从物联网设备到高性能计算集群。这种适应性将支持在各种上下文中部署YOLO模型,具体取决于应用程序的需求和约束。此外,通过定制模型以适应不同的硬件规格,YOLO可以为更多的用户和行业提供访问和有效的服务。














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









