









1、yolo系列发展背景
在 CV (计算机视觉)领域,目标检测任务是实际应用项目的第一步,主要包括:人脸识别、多目标检测、REID、客流统计等内容。yolov5是目标检测一个非常成熟、经典的模型,它自从提出以来,在工业、军事、科研方面有着广泛的应用。
yolov1,v2,v3的作者是美国的Joseph Redmon,被人称为yolo之父,但是由于其反对将yolo用于军事和隐私窥探,2020年2月宣布停止更新yolo。

后来,俄罗斯的Alexey大神更新了yolov4,不久之后,yolov5也应运而生,2021年旷视科技又发布了yolox算法。
2、yolov3
目前,yolov3的论文是《Yolov3:An incremental improvement》,yolov4的论文是《yolov4:optimal speed and accuracy of object detection》,而yolov5并没有出什么官方的论文。
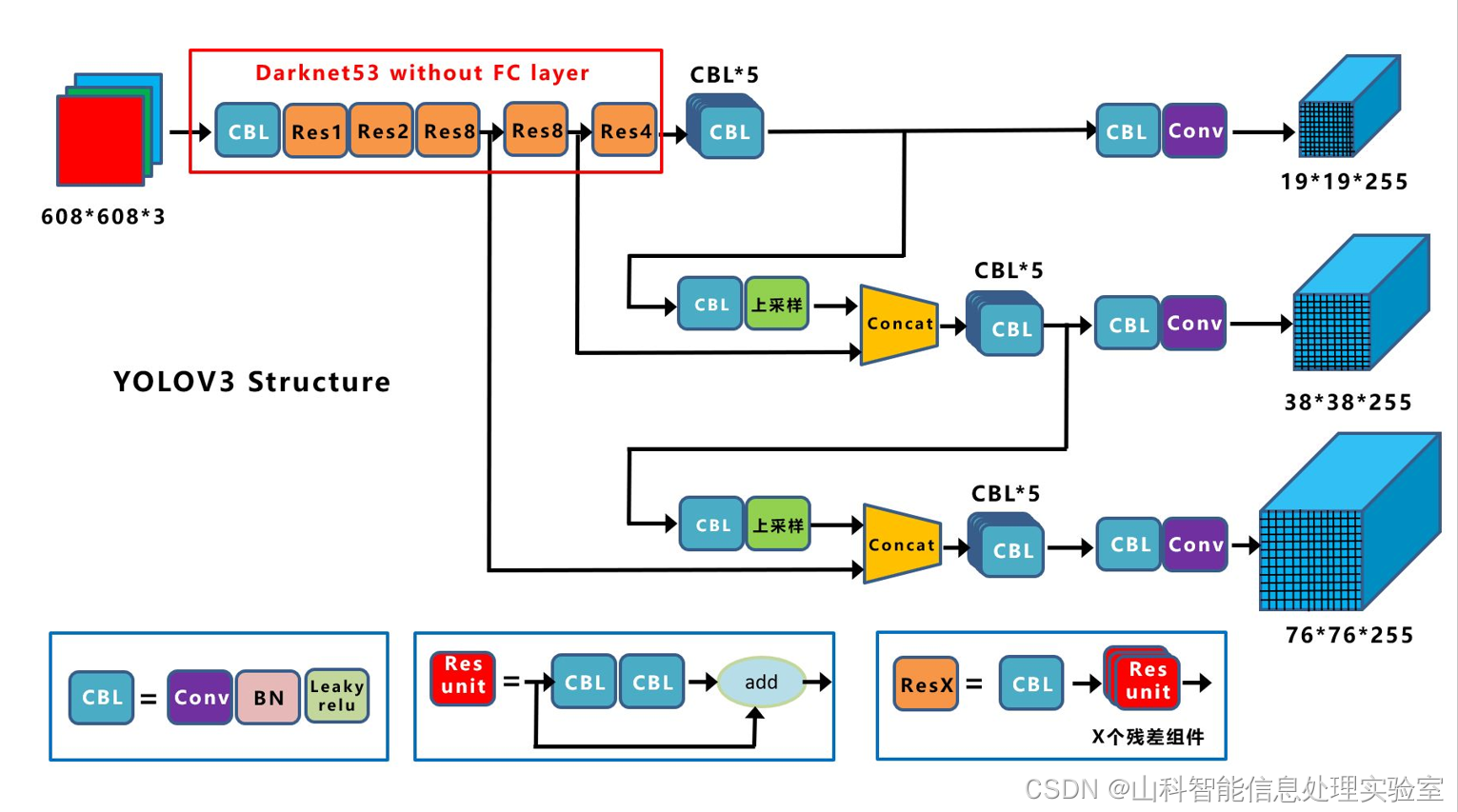
上图三个蓝色方框内表示Yolov3的三个基本组件:
CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
其他基础操作:
Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。Concat和cfg文件中的route功能一样。
add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。add和cfg文件中的shortcut功能一样。
Backbone中卷积层的数量:
每个ResX中包含1+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
Yolov3是2018年发明提出的,这成为了目标检测one-stage中非常经典的算法,包含Darknet-53网络结构、anchor锚框、FPN等非常优秀的结构
3、yolov4

Yolov4的结构图和Yolov3相比,因为多了CSP结构,PAN结构,如果单纯看可视化流程图,会觉得很绕,不过在绘制出上面的图形后,会觉得豁然开朗,其实整体架构和Yolov3是相同的,不过使用各种新的算法思想对各个子结构都进行了改进。
先整理下Yolov4的五个基本组件:
CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
其他基础操作:
Concat:张量拼接,维度会扩充,和Yolov3中的解释一样,对应于cfg文件中的route操作。
add:张量相加,不会扩充维度,对应于cfg文件中的shortcut操作。
Backbone中卷积层的数量:
和Yolov3一样,再来数一下Backbone里面的卷积层数量。
每个CSPX中包含5+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(5+2*1)+(5+2*2)+(5+2*8)+(5+2*8)+(5+2*4)=72。
Yolov4本质上和Yolov3相差不大,但算法创新大致分为三种方式:
第一种:面目一新的创新,比如Yolov1、Faster-RCNN、Centernet等,开创出新的算法领域,不过这种也是最难的
第二种:守正出奇的创新,比如将图像金字塔改进为特征金字塔
第三种:各种先进算法集成的创新,比如不同领域发表的最新论文的tricks,集成到自己的算法中,却发现有出乎意料的改进
Yolov4既有第二种也有第三种创新,组合尝试了大量深度学习领域最新论文的20多项研究成果,而且不得不佩服的是作者Alexey在github代码库维护的频繁程度。
目前Yolov4代码的star数量已经1万多,据我所了解,目前超过这个数量的,目标检测领域只有Facebook的Detectron(v1-v2)、和Yolo(v1-v3)官方代码库(已停止更新)。
输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
4、yolov5简介
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。下面先看一下yolov5的主体框架。

这四种结构分别对应着网络的深度不同。它们是通过depth_multiple和width_multiple两个参数,来进行控制网络的深度和宽度。其中depth_multiple控制网络的深度(BottleneckCSP数),width_multiple控制网络的宽度(卷积核数量)


接下来是四大网络结构的算法性能测试图:

Yolov5作者是在COCO数据集上进行的测试,COCO数据集的小目标占比,因此最终的四种网络结构,性能上来说各有千秋。Yolov5s网络最小,速度最少,AP精度也最低。但如果检测的以大目标为主,追求速度,倒也是个不错的选择。其他的三种网络,在此基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
yolov5的四大结构分别为:
输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
Backbone:Focus结构,CSP结构
Neck:FPN+PAN结构
Prediction:GIOU_Loss
5、yolov5技术详解
输入端
(1)数据增强
YOLOV5的数据增强处理方法有很多,主要的处理方式:随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果还是很不错的

(2)自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

(3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
BACKBONE
(1)focus

对于focus作用,作者在issues上做了具体的解答,都是从计算量和参数量出发,虽然不知道作者改进的思想,我理解为对一层普通下采样卷积的改进,然后并行的计算,所以经过改进后参数量其实还是变少了的,也确实达到了提速的效果。
(2)CSP

在yolov5的6.0版本作者将CSP换为C3(名字不重要,看结构),C3网络结构如下:

CSP和C3的区别就在于把红框部分去掉,CSP变C3。
NECK
neck是放在backbone和head之间的,是为了更好的利用backbone提取的特征。采用的是FPN+PAN(自底向上的特征金字塔)的结构。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合。FPN+PAN借鉴的是18年CVPR的PANet,PAN当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov5中,进一步提高特征提取的能力.

输出端
(1)yolov5的损失函数

(2)Bounding box的损失函数
Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数CIOU_LossBounding Box Regression的Loss的发展过程:SmoothL1−>IoULoss−>GIoULoss−>DIoULoss−>CIoULoss
各个Loss的不同点:
IOU Loss:主要考虑检测框和目标框重叠面积;
GIOU Loss:在IOU的基础上,解决边界框不重合时的问题;
DIOU Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息;
CIOU Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。


6、总结
yolo算法一经出世,就在计算机视觉领域受到了广泛的欢迎,其中最经典的就是yolov5,它的四种网络结构能够代表各个层面的资源要求和精度需要。而且它在处理时,可以选择照片和视频的数据形式,自带wandb可视化界面。














 4862
4862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









