









HANA一种内存数据库平台,数据存储在内存中,支持内存计算。
一、HANA支持行存储和列存储方式。
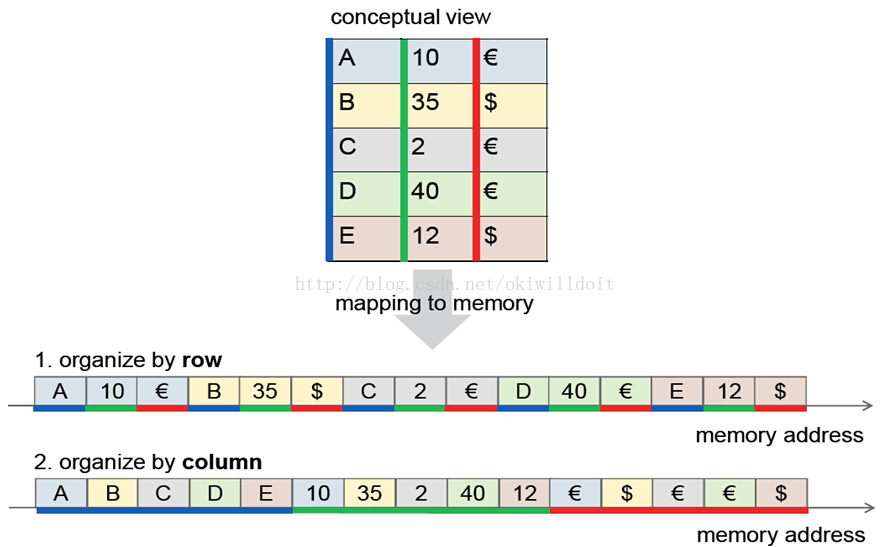
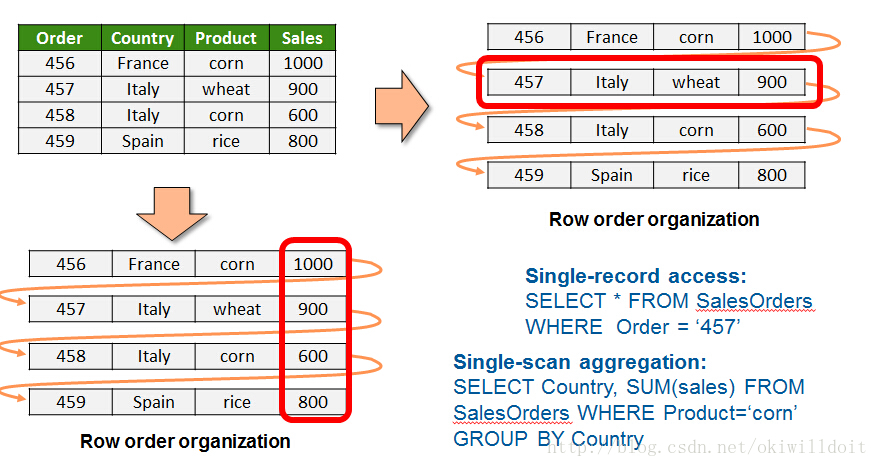
HANA支持行存储,但是在做某些操作时,用列存储的方式做了优化。例如:
执行一个简单的SQL语句:
SELECT * FROM SalesOrders WHERE Order = ‘457’,显然用行存储的方式更高效。
但是如果是比较复杂的SQL语句,用到聚合函数等:
SELECT Country, SUM(sales) FROM SalesOrdersWHERE Product=‘corn’ GROUP BY Country
这条语句用列存储的方式查询更加高效。
二、按列存储字典压缩
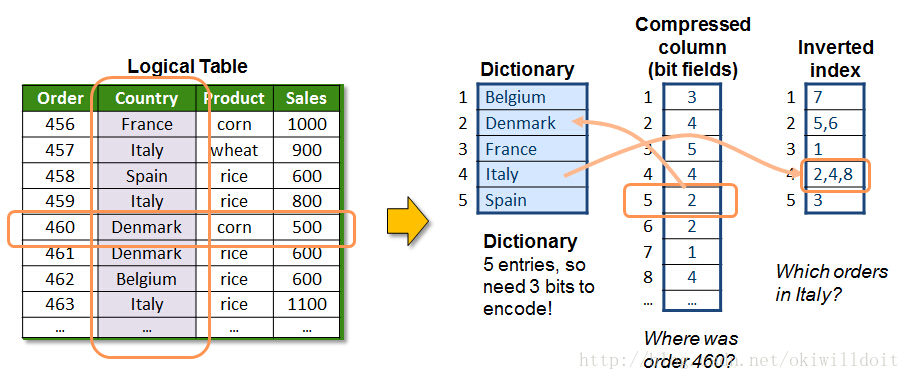
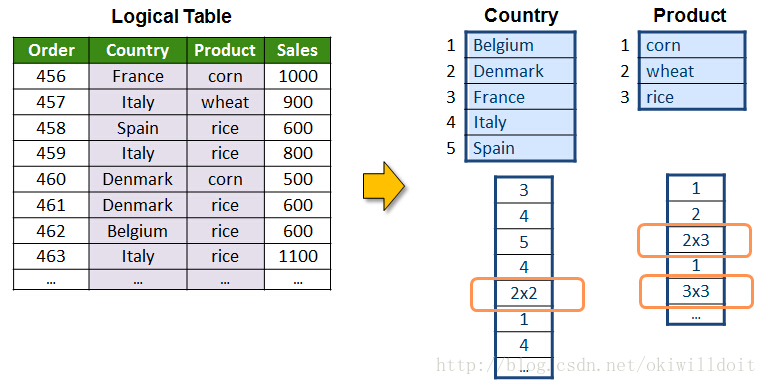
这个例子中,County列用了字典压缩,字典中包含了5个国家名,用3bit就可以表示这些国家,在压缩列中,每个单元用3bit的二进制位就可以表示了。然后根据字典里的key建立倒排索引,例如key=4的国家在第2,4,8条记录出现,在查询类似哪些order在Italy出现的记录时,这个倒排索引很高效。
第5,6条记录的国家都是2,所以有更高效的方式进行压缩:
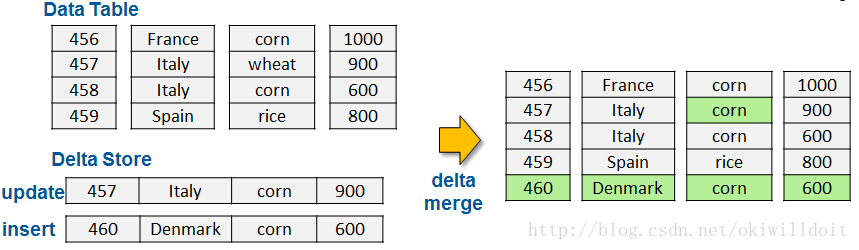
三、Delta Store
HANA中用Delta Store来进行insert和update操作,之后将原来的数据和Delta Store两者merge。
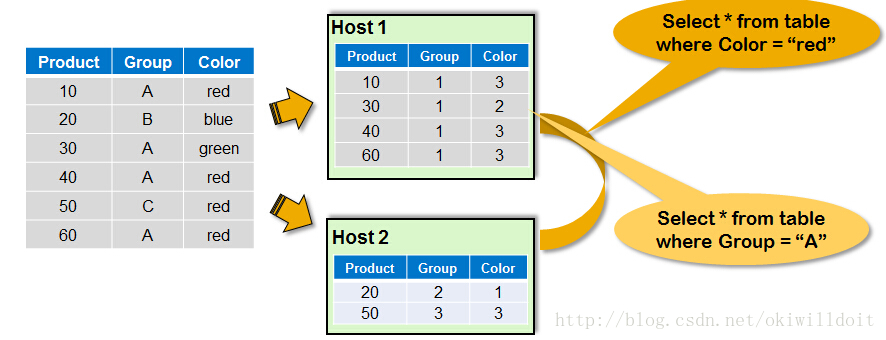
四、Data Partitioning
HANA可以将数据分割,进行分布式处理,并行处理等。
列存储的数据组织方式,有以下优点:
1.在许多情况下,消除了使用索引的必要。因为索引本身就是针对列的,列存储的方式,也就没有必要再建立索引,节省了物理空间。
2. 数据压缩和按列扫描的方式使得读性能很高。
3. 索引的消除,节省了内存空间,一定程度上提高了写性能。
相关资料:
Development Information -> SAP HANA Developer Guide

















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









