









flowable工作流
某位龙场悟道的带佬说过:知行合一
但是我没有人家那么高的境界,而且互联网中很多东西的知很无聊
所以本文注重行,主要展示如何在项目中使用flowable
尤其是在原本使用status字段进行流程控制的项目中对应的操作如何使用flowable进行替代
为什么要有工作流flowable
项目中的流程控制(提案的流转)使用的是status字段进行不同状态的区分和转换,其实有更好的方案可以使用
使用工作流可以更好的完成这个过程:
- Flowable提供了一种可视化的方式来设计和管理业务流程(
BPMN图和对应的.BPMN20.xml流程文件),通过流程设计器(可以通过ui画出BPMN图,然后自动生成.BPMN20.xml文件)可以直观地创建、编辑和维护流程模型。这使得非技术人员(如业务分析师)也能参与到流程设计中,提高了流程设计的效率和准确性。 - Flowable支持复杂的流程逻辑,包括并行分支、条件路由、子流程、多实例任务、事件监听等。这些特性使得流程能够适应复杂的业务规则和变动,能够灵活应对业务流程的扩展和变更。
- Flowable内置了对任务的分配、候选人/组管理、权限控制等功能,能够根据业务流程需要自动分配任务给合适的参与者,并确保只有授权的用户能够访问和操作相关任务。
- 使用
status字段时,角色与权限管理通常需要在应用程序中额外实现,增加了开发复杂度,且可能无法实现与流程紧密结合的细粒度权限控制。
- 使用
- Flowable在处理流程实例时,能够确保流程状态变更与相关数据操作(如更新数据库记录、调用外部服务等)在同一个事务中完成,保证了数据的一致性和完整性。
- Flowable提供了丰富的历史数据查询、审计追踪、报表生成等功能,便于监控和分析流程执行情况,快速定位问题,支持决策支持和持续优化。
- 使用
status字段时,需要自行编写查询和报表逻辑,且难以获取完整的流程执行历史和详细的执行细节。
- 使用
总之这篇文章讲flowable,管你什么理由,少废话看下去(bushi
工作流概念
不用官方的描述,我用我自己的理解
工作流就是将一个工作的流程给形象化的表示出来
在软件工程中我们可能会学习过BPMN图,类似于下面这样子
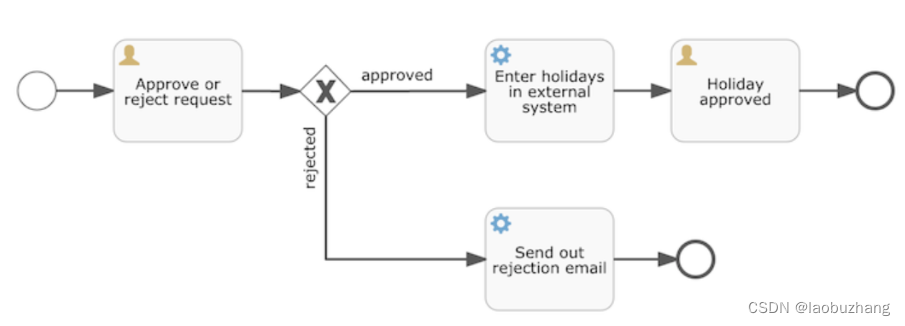
在写c++算法时也应该有类似的代码流程图,都是一样的
BPMN2.0
flowable的作用就是把BPMN图转换为配置文件,后缀名为.bpmn20.xml
对于上边这个图,他的.bpmn20.xml文件长这样子(有点长,你可以先看后边的解释在回来逐个理解):
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:flowable="http://flowable.org/bpmn"
typeLanguage="http://www.w3.org/2001/XMLSchema"
expressionLanguage="http://www.w3.org/1999/XPath"
targetNamespace="http://www.flowable.org/processdef">
<!-- 流程定义的编写-->
<!--id为holidayRequest,isExecutable为true表示该流程可以被执行-->
<process id="holidayRequest" name="Holiday Request" isExecutable="true">
<!--startEvent为开始节点,流程的开始-->
<startEvent id="startEvent"/>
<!--sequenceFlow为连线,sourceRef为开始节点的id,targetRef为下一个节点的id-->
<sequenceFlow sourceRef="startEvent" targetRef="approveTask"/>
<!--userTask为用户任务,即需要用户来完成的任务,需要指定id和name-->
<!--我们希望第一个任务转到“经理”组,加上flowable:candidateGroups="managers"-->
<userTask id="approveTask" name="Approve or reject request" flowable:candidateGroups="managers"/>
<sequenceFlow sourceRef="approveTask" targetRef="decision"/>
<!--exclusiveGateway为排他网关,即判断条件,需要指定id-->
<exclusiveGateway id="decision"/>
<!--sequenceFlow为连线,sourceRef为排他网关的id,targetRef为下一个节点的id,conditionExpression为条件表达式,即判断条件-->
<sequenceFlow sourceRef="decision" targetRef="externalSystemCall">
<!-- 这里是判断条件,${approved}表示流程变量approved的值,如果approved为true,则流程走向externalSystemCall,否则走向sendRejectionMail,此处作为表达式编写的条件是${approved}形式,是${approved==true}的简写-->
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[
${approved}
]]>
</conditionExpression>
</sequenceFlow>
<sequenceFlow sourceRef="decision" targetRef="sendRejectionMail">
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[
${!approved}
]]>
</conditionExpression>
</sequenceFlow>
<!--serviceTask为服务任务,这里是==true时的步骤即需要调用服务来完成的任务,需要指定id,name和class,这里的class为自定义的类-->
<serviceTask id="externalSystemCall" name="Enter holidays in external system"
flowable:class="cn.learning.flowable.quickstart.CallExternalSystemDelegate"/>
<sequenceFlow sourceRef="externalSystemCall" targetRef="holidayApprovedTask"/>
<!--userTask为用户任务,即需要用户来完成的任务,这里表达管理人员统一审核,需要指定id和name-->
<!--我们希望第二个任务转到“假期申请人”,加上flowable:candidateGroups="${employee}",基于在启动流程实例是传递的流程变量的动态赋值-->
<userTask id="holidayApprovedTask" name="Holiday approved" flowable:assignee="${employee}"/>
<sequenceFlow sourceRef="holidayApprovedTask" targetRef="approveEnd"/>
<!--serviceTask为服务任务,这里是==false时的步骤即需要调用服务来完成的任务,需要指定id,name和class,这里的class为自定义的类-->
<serviceTask id="sendRejectionMail" name="Send out rejection email"
flowable:class="org.flowable.SendRejectionMail"/>
<sequenceFlow sourceRef="sendRejectionMail" targetRef="rejectEnd"/>
<!--endEvent为结束节点,流程的结束-->
<endEvent id="approveEnd"/>
<endEvent id="rejectEnd"/>
</process>
</definitions>
BPMN2.0节点
BPMN中的一个一个节点,其实就相当于原本的方案中status字段的一个一个值
一个BPMN节点表示流程的一个状态
可以一个一个看BPMN配置文件中的变量
流程
顾名思义,一个流程标签就表示一个完整的流程,所有的东西都写在流程标签中
<!--id为holidayRequest,isExecutable为true表示该流程可以被执行-->
<process id="holidayRequest" name="Holiday Request" isExecutable="true">
......
</process>
开始节点
就是bpmn做左边的圆圈,就是开始节点
<!--startEvent为开始节点,流程的开始-->
<startEvent id="startEvent"/>
结束节点
就是bpmn右边的两个圆圈(结束节点能有好多个,可以有一个,也可以有更多个),就是结束节点
<!--endEvent为结束节点,流程的结束-->
<endEvent id="rejectEnd"/>
连线
就是bpmn图中的箭头连线,表示流转的方向
<!--sequenceFlow为连线,sourceRef为开始节点的id,targetRef为下一个节点的id-->
<sequenceFlow sourceRef="startEvent" targetRef="approveTask"/>
用户任务
就是bpmn中的圆角矩形人头节点,表示需要用户进行的操作(比如经理同意/拒绝请假)
当流程走到这一步时,如果指定的用户没有执行操作,则流程就会在这里停住,直到用户操作
<userTask id="approveTask" name="Approve or reject request" flowable:candidateGroups="managers"/>
服务任务
就是bpmn中的圆角矩形齿轮节点,表示系统自动进行的操作,当流程执行到该任务时,会自动执行对应的任务,然后直接进入到下一个节点
(说实话,这些任务应该也可以在java代码在前一个节点执行完毕后执行,但是既然有这个节点,肯定这样更规范)
<!--serviceTask为服务任务,这里是==true时的步骤即需要调用服务来完成的任务,需要指定id,name和class,这里的class为自定义的类,写出要执行的操作-->
<serviceTask id="externalSystemCall" name="Enter holidays in external system"
flowable:class="cn.learning.flowable.quickstart.CallExternalSystemDelegate"/>
服务任务指定的class有一定的格式,下面是一个例子:
- 实现JavaDelegate接口
- 重写execute方法
满足上述两个条件,就会执行execute方法中的操作
package cn.learning.flowable.quickstart;
import org.flowable.engine.delegate.DelegateExecution;
import org.flowable.engine.delegate.JavaDelegate;
public class CallExternalSystemDelegate implements JavaDelegate {
@Override
public void execute(DelegateExecution execution) {
System.out.println("laobuzhang666");
}
}
网关节点
就是bpmn图中的菱形带X节点,根据条件判断流程要走的分支
<!--exclusiveGateway为排他网关,即判断条件,需要指定id-->
<exclusiveGateway id="decision"/>
网关节点的连线
其实就是连线,只不过在网关后需要加上判断条件
approved是流程运行中的变量,后边会说到
<!--sequenceFlow为连线,sourceRef为排他网关的id,targetRef为下一个节点的id,conditionExpression为条件表达式,即判断条件-->
<sequenceFlow sourceRef="decision" targetRef="externalSystemCall">
<!-- 这里是判断条件,${approved}表示流程变量approved的值,如果approved为true,则流程走向externalSystemCall,否则走向sendRejectionMail
此处作为表达式编写的条件是${approved}形式,是${approved==true}的简写-->
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[${approved}]]>
</conditionExpression>
</sequenceFlow>
BPMN-ui
知道了上边的配置节点的代码,你就根据bpmn图连线写配置吧,一连一个不吱声(其实我感觉这个过程还听有意思的多)
其实有对应的BPMN-ui,可以根据你画出的bpmn图自动生成xml文件,我就不深入了,感兴趣的可以自行查阅
springboot使用flowable
使用之前请确认mysql版本不宜过低,否则可能出现各种问题,例如字段名限制长度导致flowable创建表失败,mysql不支持6位精度小数等
我们可以直接在serviceImpl类中使用
可以通过@Autowired装配对应的类然后就能直接用
下面有5个函数,分别展示了:
- 流程的部署
- 开始一个流程
- 条件查询一个流程或者这个流程对应的状态
- 完成一个任务(相当于原本使用status时,status的变化,代表转变为下一个状态)
- 查询流程中的所有信息
package cn.learning.flowable.springboot.service;
import cn.learning.flowable.springboot.pojo.ResponseBean;
import cn.learning.flowable.springboot.pojo.VacationApproveVo;
import cn.learning.flowable.springboot.pojo.VacationInfo;
import cn.learning.flowable.springboot.pojo.VacationRequestVo;
import org.flowable.engine.HistoryService;
import org.flowable.engine.RepositoryService;
import org.flowable.engine.RuntimeService;
import org.flowable.engine.TaskService;
import org.flowable.engine.history.HistoricProcessInstance;
import org.flowable.task.api.Task;
import org.flowable.variable.api.history.HistoricVariableInstance;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.PostConstruct;
import java.util.*;
@Service
public class VacationService {
@Autowired
RuntimeService runtimeService;
@Autowired
TaskService taskService;
@Autowired
HistoryService historyService;
@Autowired
private RepositoryService repositoryService;
// 部署流程,相当于把配置文件加载进来
@PostConstruct
public void init() {
// 部署流程
// addClasspathResource中填写对应的bpmn配置文件地址
repositoryService.createDeployment().addClasspathResource("processess/vacationRequest.bpmn20.xml").deploy();
}
// 下面这些方法方法展示flowable的使用,其中的代码完全可以用在其他service方法中
// 开始一个流程
// 主要是runtimeService.startProcessInstanceByKey("vacationRequest", vacationRequestVO.getName(), variables);
@Transactional
public void startFlow() {
// variables后边会解释
Map<String, Object> variables = new HashMap<>();
variables.put("name", vacationRequestVO.getName());
variables.put("days", vacationRequestVO.getDays());
variables.put("reason", vacationRequestVO.getReason());
try {
// 指定业务流程
// 第一个参数是在xml文件中定义流程的id,用于找到对应的流程(这么看来一个xml应该可以写多个流程)
// 第二个参数是设置这个流程实例的业务键(Business Key),在这里设置后,可以在后续根据业务键定位(查询)到这个流程实例
// 第三个参数就是传入流程的参数variables,variables后边会解释
runtimeService.startProcessInstanceByKey("vacationRequest", vacationRequestVO.getName(), variables);
} catch (Exception e) {
e.printStackTrace();
}
}
// 根据条件查询对应的信息
// 主要是taskService.createTaskQuery().查询条件
@Transactional
public void findFlow() {
// 这里的查询的是所有需要manager身份的人才能够进行操作的任务
String identity="manager";
List<Task> tasks = taskService.createTaskQuery().taskCandidateGroup(identity).list();
List<Map<String, Object>> list = new ArrayList<>();
for (int i = 0; i < tasks.size(); i++) {
Task task = tasks.get(i);
Map<String, Object> variables = taskService.getVariables(task.getId());
variables.put("id", task.getId());
list.add(variables);
}
//输出对应的信息
System.out.println(list);
}
// 完成流程中的任务
// 主要是taskService.complete(task.getId(), variables);
@Transactional
public void completeFlow() {
boolean approved = vacationVO.getApprove();
Map<String, Object> variables = new HashMap<String, Object>();
variables.put("approved", approved);
variables.put("employee", vacationVO.getName());
Task task = taskService.createTaskQuery().taskId(vacationVO.getTaskId()).singleResult();
taskService.complete(task.getId(), variables);
// 完成任务后,流程会进入到下一个节点
}
// 查询流程信息
@Transactional
public void checkFlow() {
// 先用查询条件查询到对应的流程
List<VacationInfo> vacationInfos = new ArrayList<>();
List<HistoricProcessInstance> historicProcessInstances = historyService
.createHistoricProcessInstanceQuery()
.processInstanceBusinessKey(name) // 创建流程时指定的业务键
.finished() // 只查询已经完成的流程,即进入到结束节点的任务
.orderByProcessInstanceEndTime()
.desc()
.list();
for (HistoricProcessInstance historicProcessInstance : historicProcessInstances) {
VacationInfo vacationInfo = new VacationInfo();
Date startTime = historicProcessInstance.getStartTime();
Date endTime = historicProcessInstance.getEndTime();
// 查询这个流程中的所有变量,即上边遇到过的variable,这些variable中存储了流程中的各种信息
List<HistoricVariableInstance> historicVariableInstances = historyService.createHistoricVariableInstanceQuery()
.processInstanceId(historicProcessInstance.getId())
.list();
// 使用实体类将信息拿出来
for (HistoricVariableInstance historicVariableInstance : historicVariableInstances) {
String variableName = historicVariableInstance.getVariableName();
Object value = historicVariableInstance.getValue();
if ("reason".equals(variableName)) {
vacationInfo.setReason((String) value);
} else if ("days".equals(variableName)) {
vacationInfo.setDays(Integer.parseInt(value.toString()));
} else if ("approved".equals(variableName)) {
vacationInfo.setStatus((Boolean) value);
} else if ("name".equals(variableName)) {
vacationInfo.setName((String) value);
}
}
vacationInfo.setStartTime(startTime);
vacationInfo.setEndTime(endTime);
vacationInfos.add(vacationInfo);
}
//输出对应的信息
System.out.println(vacationInfos);
}
// 一些正常的service方法
// ......
}
java flowable中一些概念
flowable变量:variables
在上边的代码中variables出现了很多次
variables其实就是整个流程的变量
在整个流程中:
-
可以随时查询或者更改这个流程中这些变量
-
可以随时新增变量(mysql馋哭了,想想使用mysql时新增字段,需要更改数据库,需改更改mapper,需要更改实体类,需要更改sql语句,部分业务代码可能也需要更改)
-
还可以把变量的值来当作查询条件
其实可以把variables看作mysql表中的一个一个字段
新增variables的方式
variables在java中都是map键值对的形式
- key(只能是String类型)相当于mysql的字段
- value(可以是任何 Java 对象,如果需要flowable会对值进行序列化)相当于这一行(一行表示一个流程)这个字段的值(这一点应该比mysql还要厉害,因为mysql的字段不能是数组类型)
有好几种方式(没有会新增,有会更新)
- 创建时直接加入:
runtimeService.startProcessInstanceByKey("vacationRequest", vacationRequestVO.getName(), variables) - 使用runtimeService:
runtimeService.setVariable(process.getId(),variables) - 使用taskService:
taskService.setVariable(process.getId(),variables) - 完成任务时加入:
taskService.complete(task.getId(), variables)
id和definitionKey
- process.getId()
- task.getId()
这些方法得到的都是他们的id,是在实例化时自动生成的一段字符串,用来唯一标识,可用来查询等
-
process.getDefinitionKey()
-
task.getDefinitionKey()
这些得到的时他们的识别key,就是在xml文件中写下的id字段的值(也就是说xml文件中的id和java代码中的id指的是不同的1东西)
数据存储
flowable中的数据不止存在于内存之中,而且会持久化到数据库中(默认开启),并且会自动建立表,自动添加字段等
例如上边的taskService.complete(task.getId(), variables)代码执行后
不仅记录流程的表会更新流程的变化,记录变量的表也会更新/新增variables中对应的变量
查询时也是从表中查询到的数据
相关配置文件:
server:
port: 8081
# mysql配置
spring:
datasource:
url: jdbc:mysql://localhost:3306/flowable?autoReconnect=true&useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
logging:
level:
org:
flowable: debug
flowable:
# 业务流程设计的表自动创建
database-schema-update: true
# 异步执行耗时操作,提升性能
async-executor-activate: false
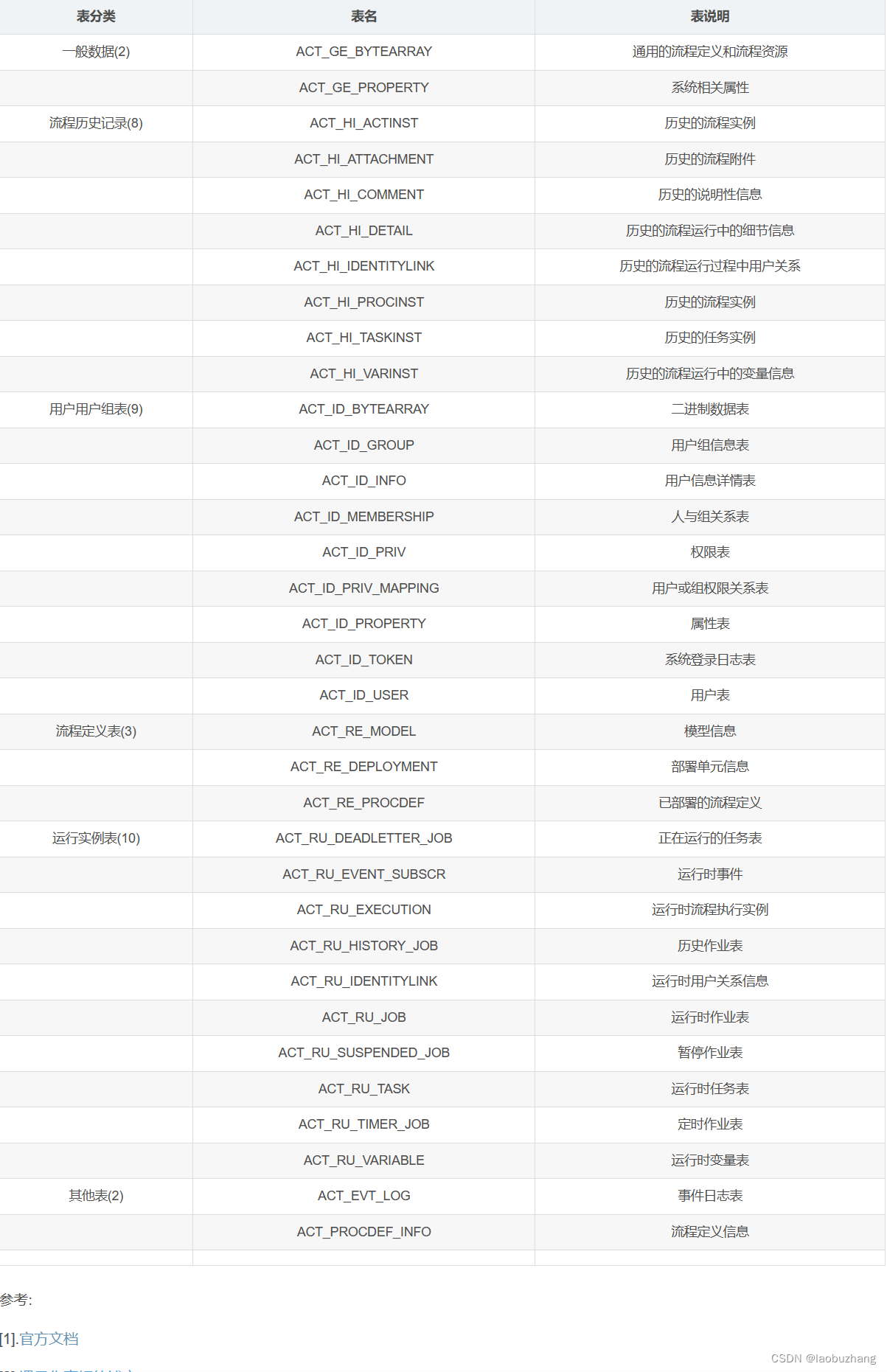
flowable对应的表如下
一共有34张表
finish和unfinish
task和process都有finish和unfinish
task:
- finish:任务已被用户或自动化过程完成(如通过API调用
taskService.complete(taskId))。完成的任务意味着其分配给用户的任务动作已经执行完毕,任务状态更新为已完成,流程将继续流向下一个节点。 - unfinished:任务尚未被用户或自动化过程完成,仍显示在待办列表中,等待被分配的用户执行相应的任务动作。
process:
- 流程实例已到达流程定义中的结束节点(如结束事件),或被显式地结束(如通过API调用
runtimeService.deleteProcessInstance()或runtimeService.terminateProcessInstance())。此时,流程实例被视为已完成(finished),不会再有任何进一步的活动发生。 - 流程实例尚未到达流程定义中的结束节点,还在运行中,有未完成的任务、子流程或其他活动节点等待处理。
flowable条件查询
这个是我认为flowable取代mysql中关键的一步
很多原本依赖于mapper进行查询的数据,都可以通过java代码实现,如果能够满足全部的查询,甚至可以让flowable完全代替原本的带status字段的表
下面用几个常见的条件查询情况来展示:
表结构:
这里表示用status字段时,表的结构
表名:article
主键:id
字段:status,userId,content,title
查询处于编辑状态的article:
String taskDefinitionKey = "editingTask"; // 与xml文件中的userTask的id属性相同
String candidateGroup = "managers"; // 目标用户组
// 查询到所有正处于editingTask任务(状态)(还没有完成)的task,相当于查询到所有status处于editingTask的行
List<Task> tasks = taskService.createTaskQuery()
.taskDefinitionKey("taskDefinitionKey")
.active()
.list();
for(Task task:tasks){
// 根据task获取到流程的id,相当于原方案中这一行的主键id
String processInstanceId = task.getProcessInstanceId()
HistoricVariableInstance contentVar = historyService.createHistoricVariableInstanceQuery()
.processInstanceId(processInstanceId)
.variableName("content") // 假设流程变量“content”用于存储文章内容
.singleResult();
HistoricVariableInstance analysisVar = historyService.createHistoricVariableInstanceQuery()
.processInstanceId(processInstanceId)
.variableName("userId") // 假设流程变量“userId”用于文章的作者id
.singleResult();
HistoricVariableInstance titleVar = historyService.createHistoricVariableInstanceQuery()
.processInstanceId(processInstanceId)
.variableName("title") // 假设流程变量“title”用于存储提案标题
.singleResult();
String content = (String) contentVar.getValue();
String analysis = (String) analysisVar.getValue();
String title = (String) titleVar.getValue();
}
查询某一个人的文章
String userId="123";
List<HistoricProcessInstance> pendingReviewProcesses = historyService.createHistoricProcessInstanceQuery()
.variableValueEquals("userId", "") // userId这个变量等于对应的用户
.variableValueLike("title", "%" + titleKeyword + "%") // 还可以支持like模糊查询
.list();
//后续操作如上
配置文件取值
这个小技巧能够让flowable更加解耦
.bpmn20.xml文件中可以使用配置文件直接写入值
这样一来task的id,process的id,java代码中使用key时,都可以直接使用配置文件中的值,想要修改时只需要修改配置文件即可
在xml文件中这样写
<userTask id="${approveTaskId}" name="${approveTaskName}" flowable:candidateGroups="${config.managerGroup}"/>
在java代码中这样写
@Value("${config.approveTaskId}")
String taskId;
@Value("${config.approveTaskName}")
String taskName;
Map<String, Object> configVars = new HashMap<>();
configVars.put("approveTaskName", taskId);
configVars.put("managerGroup", taskName);
runtimeService.startProcessInstanceByKey("processDefinitionKey", configVars);
相当于是在创建流程实例时,直接把配置文件中的值加入到flowable变量,然后xml文件中可以使用该变量
写在最后
虽然flowable提供了很多功能,有时候甚至能替代使用带status字段的表
但是我觉得他们两个联合在一起使用的时候应该会更加好用















 3204
3204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









