







一、简介
Spark主要包含Transformation和Action两种算子。
- Transformation算子
Transformation类算子一般都是懒操作的,即该过程并不提交Job作业,而是等到Action算子才会提交作业。主要包括:map、filter、flatMap、mapPartitions、mapPartitionsWithIndex、sample、union、intersection、distinct、groupByKey、reduceByKey、aggregateByKey、sortByKey、join、cogroup、cartesian、pipe、coalesce、repartition、repartitionAndSortWithinPartitions。 - Actions算子
Actions类算子主要包括:reduce、collect、count、first、take、takeSample、takeOrdered、saveAsTextFile、saveAsSequenceFile、saveAsObjectFile、countByKey、foreach等。
二、Transformation常用算子介绍
1. map
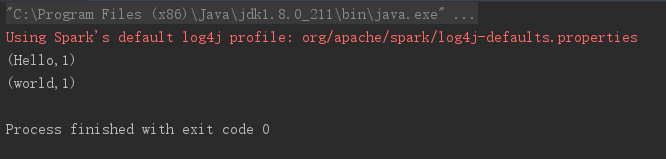
将原来的RDD中的每个数据项映射成新的数据项,代码如下所示:
// map
val data1 = Array("Hello", "world")
val data_map = sc.parallelize(data1)
data_map.map( x => {
(x, 1)
}).foreach(println(_))
结果如下图所示
2. flatmap
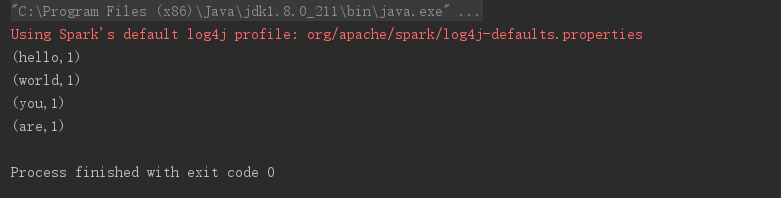
将RDD中每个数据项进行映射,然后进行扁平化处理,代码如下所示:
// flatmap
val data2 = Array(Array("hello", "world"), Array("you", "are"))
val data_flatmap = sc.parallelize(data2)
data_flatmap.map( x => {
x.map( y => {
(y, 1)
})
}).foreach(println(_))
结果如下图所示:
3. mapPartitions
与map算子类似,但传入的参数是一个迭代器,通过迭代器可以访问各数据项,效率要比map更高,代码如下所示:
// mapPartitions
val data3 = Array("Hello", "world", "blue", "music", "window")
val data_partition = sc.parallelize(data3)
data_partition.mapPartitions(iter => {
iter.map((_, 1))
}).foreach(println(_))
结果如下所示:

4. filter
filter是对数据项中的数据依据相关条件进行过滤,filter的输出分区是输入分区的子集,与此相似的还有distinct、sample等,代码如下所示:
// filter
val data4 = Array(2, 8, 10, 21, 9, 10, 22)
val data_partition = sc.parallelize(data4)
data_partition.filter(_>10).foreach(println(_))
结果如下图所示:

5. distinct
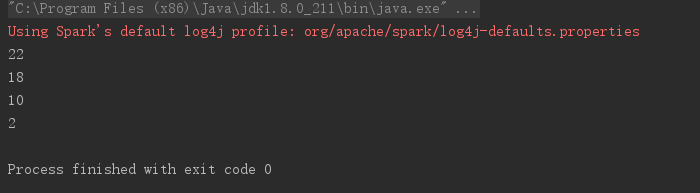
distinct算子主要用于去重,相关代码如下所示:
// distinct
val data = Array(2, 2, 10, 18, 22, 10, 22)
val rdd = sc.parallelize(data)
rdd.distinct().foreach(println(_))
结果如下图所示:
6. groupBy
将数据项通过函数生成key,然后将key相同的元素分为同一组,与groupByKey类似,代码如下:
// groupBy
val data = Array("Hello", "world", "Hello", "music", "world")
val rdd = sc.parallelize(data)
rdd.mapPartitions(iter =>
iter.map((_, 1))
).groupByKey().foreach(println(_))
结果如下图所示:

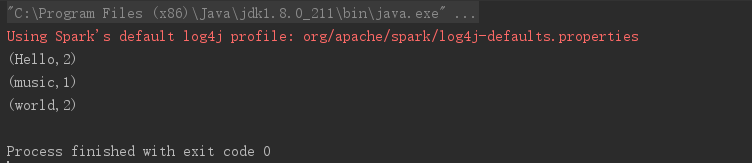
7、reduceByKey
reduceByKey会寻找相同的key的数据项,找到两条记录会将他们的value做(x, y) => (x + y)即(_ + _),将求得的value数据之和作为value,反复执行该操作,直到只剩下一条key的记录,代码如下所示:
// reduceByKey
val data = Array("Hello", "world", "Hello", "music", "world")
val rdd = sc.parallelize(data)
rdd.mapPartitions(iter =>
iter.map((_, 1))
).reduceByKey(_+_).foreach(println(_))
上述的代码中reduceByKey(+)可以写成reduceByKey((x, y) => (x + y))
运行结果为:
8. join三种方式
根据两个RDD对象的key进行关联,代码如下所示:
// join
val data1 = Array(Tuple2("tom", 2), Tuple2("tony", 1), Tuple2("marry", 5), Tuple2("jack", 3))
val data2 = Array(Tuple2("tony", 2), Tuple2("john", 3), Tuple2("rose", 10), Tuple2("stephen", 8))
val rdd1 = sc.parallelize(data1)
val rdd2 = sc.parallelize(data2)
println("内关联")
rdd1.join(rdd2).foreach(println(_))
println("左关联")
rdd1.leftOuterJoin(rdd2).foreach(println(_))
println("右关联")
rdd1.rightOuterJoin(rdd2).foreach(println(_))
运行结果如下图所示:

我们可以看到,join只会保留key相同的数据项,而左关联则会保留左侧全部数据项,如果而右侧不存在value则以None代替,右关联亦是如此。
三、Action常用算子介绍
1. collect
collect算子用于将一个分布式的RDD对象转换为单机的数组对象,然后可以使用scala语言来操作数组,代码略。
2. collectAsMap
collectAsMap孙子用于讲一个分布式的key-value RDD对象转换成一个单机的HashMap,对于重复key的数据项后面的数据自动覆盖前一个数据,代码略。
3. count
count算子主要用于计算当前RDD对象的数据元素个数,代码略
4. reduce
reduce()与fold()方法是对同种元素类型数据的RDD进行操作,即必须同构,其返回值返回一个同样类型的新元素,代码如下所示。
// reduce
val data1 = Array(2, 2, 10, 18, 22, 10, 22)
// 第二个参数代表分区个数
val rdd = sc.parallelize(data1, 2)
val res = rdd.reduce(_+_)
print(res)
结果:

5. aggregate
aggregate() 方法可以对两个不同类型的元素进行聚合,即支持异构。
它先聚合每一个分区里的元素,然后将所有结果返回回来,再用一个给定的conbine方法以及给定的初始值zero value进行聚合
def aggregate [U: ClassTag] (zeroValue: U) (seqOp: (U,T)=>U,combOp: (U,U)=>U):U
四、小结
仅初步整理了算子,供学习使用。















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









