






代码优化方式
锁表延迟
锁表延迟是在数据库系统中常见的性能问题之一。它指的是由于锁定资源(例如行、表等)而导致其他事务或查询需要等待的延迟。当一个事务持有锁并且其他事务需要访问同一资源时,它们将被阻塞,直到持有锁的事务释放锁为止。
锁表延迟通常会导致以下问题:
性能下降: 锁表延迟会导致系统中的并发性能下降,因为其他事务需要等待锁释放才能执行。
死锁: 如果多个事务互相持有对方需要的资源,就会发生死锁,这会导致所有相关事务被阻塞,并最终导致系统崩溃或超时。
长时间等待: 如果事务需要等待锁释放,可能会导致长时间的等待,影响用户体验和系统的响应时间。
资源浪费: 长时间等待锁释放会浪费系统资源,包括数据库连接、内存和CPU等。
因此,有效地处理锁表延迟对于数据库系统的性能和稳定性至关重要。常见的解决方案包括优化数据库设计、调整事务隔离级别、合理使用索引、采用分布式数据库、引入缓存机制以及利用多线程和分段等技术来提高并发性。
解决锁表延迟
在处理锁表延迟时,引入多线程和分段解决可以提高并发性和性能。具体实现步骤如下:
分段划分数据: 将要进行操作的数据按照一定的规则(例如哈希函数)划分成多个段(Segment)。每个段可以看作是一个小的数据集合,可以独立地进行操作。
多线程处理: 对每个段启动一个独立的线程来处理。每个线程负责操作对应的段,这样可以并行处理不同的数据段,提高处理效率。
加锁机制: 对于每个数据段,需要使用适当的锁机制来保证线程安全。常见的方式有读写锁(ReadWriteLock)或者分段锁(Segment Lock),确保在多线程环境下对数据段的操作是安全的。
请求分发与协调: 当有请求到来时,根据请求涉及的数据段,将请求分发给对应的线程处理。可以使用线程池来管理线程的创建和销毁,以及请求的分发。
处理结果合并: 如果需要将处理结果合并,确保在所有线程完成任务后进行合并操作。(通过减法计数器确定所有线程执行完成)可以使用线程同步机制来实现等待所有线程完成任务再进行结果合并。
优化与监控: 针对具体应用场景进行性能优化,例如调整线程池大小、合理划分数据段数量等。同时需要监控系统运行情况,及时发现并解决可能存在的问题。
异常处理: 在多线程环境下,异常处理尤为重要。确保对异常情况进行捕获和处理,保证系统的稳定性和可靠性。
这样的实现可以有效地减少锁表延迟,提高系统的并发性和性能。
设计幂等性的接口
“一锁二判三更新”方式
“一锁二判三更新” 是一种常用的设计思路,用于保证接口的幂等性。这种方式通常用于在高并发环境下,避免出现重复操作导致的数据错误或者异常。具体实现可以分为以下步骤:
-
加锁:在进行操作之前,首先需要加锁,以确保在并发情况下只有一个线程能够执行后续的操作。常用的方式有数据库的行级锁或者分布式锁。
-
判断操作状态:在加锁之后,需要对操作状态进行判断,确定当前操作是否已经被执行过。这可以通过查询数据库或者其他存储介质来实现。如果操作已经被执行过,则可以直接返回成功,不再执行后续操作;如果操作未被执行过,则继续执行后续操作。
-
更新数据:如果判断操作未被执行过,则执行实际的数据更新操作。这可能涉及数据库的插入、更新或者删除等操作,具体根据业务需求而定。
-
释放锁:在更新数据完成之后,需要释放之前加的锁,以允许其他线程继续执行相同的操作。
以下是用Java代码实现"一锁二判三更新"的接口幂等性的示例:
import java.util.HashSet;
import java.util.Set;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class IdempotentApiExample {
private static Set<Integer> processedRequests = new HashSet<>();
private static Lock lock = new ReentrantLock();
public static void main(String[] args) {
int[] requests = {1, 2, 3, 1, 4, 2, 5, 6};
for (int requestId : requests) {
new Thread(() -> processRequest(requestId)).start();
}
}
public static void processRequest(int requestId) {
// 加锁
lock.lock();
try {
// 判断操作状态
if (!checkRequestProcessed(requestId)) {
// 更新数据
updateData(requestId);
System.out.println("Request " + requestId + " processed successfully.");
} else {
System.out.println("Request " + requestId + " already processed.");
}
} finally {
// 释放锁
lock.unlock();
}
}
public static boolean checkRequestProcessed(int requestId) {
// 模拟查询操作状态,这里使用内存中的集合来保存已处理的请求ID
return processedRequests.contains(requestId);
}
public static void updateData(int requestId) {
// 模拟更新数据操作,这里将请求ID加入集合中表示该请求已被处理
processedRequests.add(requestId);
}
}
在这个示例中,使用了Java的 Lock 接口及其实现类 ReentrantLock 来实现加锁和解锁操作。processedRequests 集合用于保存已经处理过的请求ID。processRequest 方法用于处理请求,其中包含了加锁、判断操作状态和更新数据的逻辑。
分布式事务
分布式事务是指涉及多个分布式系统参与的事务操作。在分布式系统中,事务涉及到多个节点、多个资源,可能跨越多个计算机或者网络,因此需要跨越多个资源管理器(如数据库、消息队列等)进行协调和控制。分布式事务的目标是保证跨越多个节点的事务操作的一致性和可靠性,即保证事务的ACID属性(原子性、一致性、隔离性和持久性)。
分布式事务的特点包括:
-
多个参与者:分布式事务通常涉及到多个参与者,这些参与者可能位于不同的物理节点上,包括数据库、消息队列、缓存等。
-
分布式协调:由于参与者分布在不同的节点上,因此需要一个分布式协调者来协调各个参与者的操作,确保事务的一致性。
-
网络通信:分布式事务涉及到网络通信,因此需要考虑网络延迟、故障恢复等因素对事务操作的影响。
-
数据一致性:分布式事务要求跨越多个资源管理器的操作保持数据一致性,即事务要么全部提交,要么全部回滚,不能出现部分提交的情况。
分布式事务的实现方式有多种,包括两阶段提交(2PC)、三阶段提交(3PC)、基于消息队列的分布式事务方案(如RocketMQ和Spring Cloud Stream的集成)、基于分布式事务框架的解决方案(如Seata)、以及基于本地事务和幂等性设计的解决方案等。选择合适的分布式事务解决方案需要根据具体的业务需求、系统架构和性能要求来决定。
基于RocketMQ事务消息解决分布式场景下的数据一致性问题
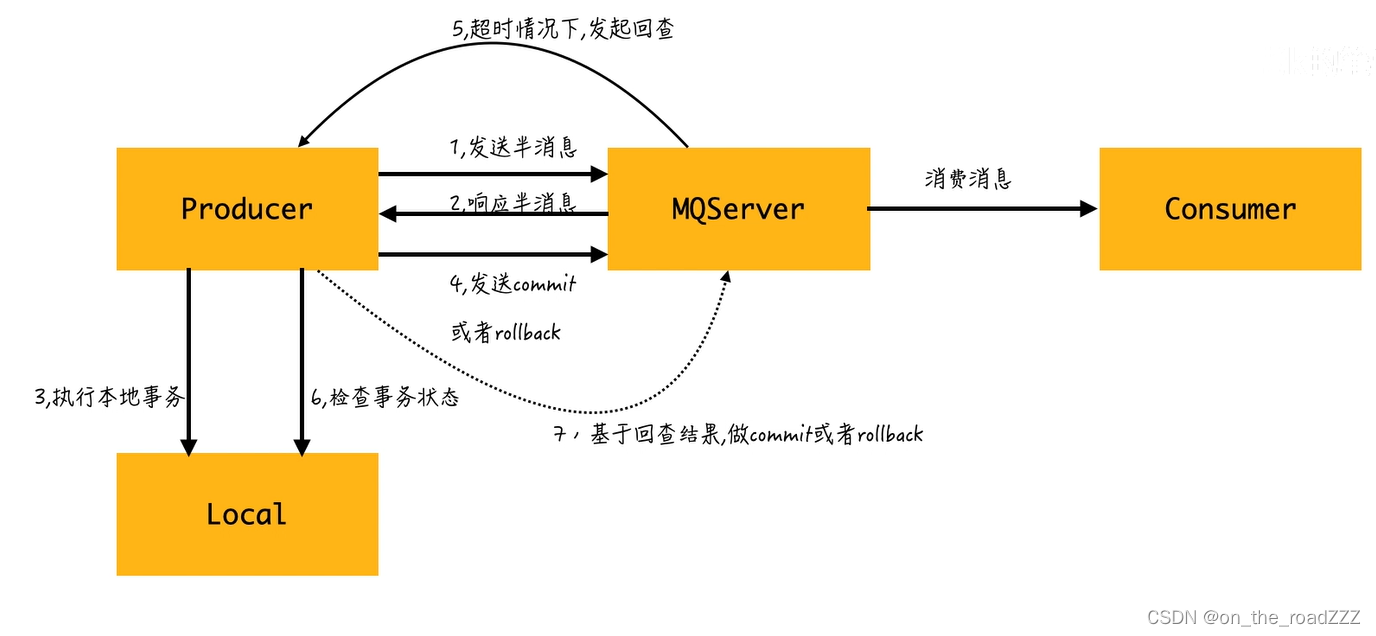
基于 RocketMQ 的事务消息可以有效解决分布式场景下的数据一致性问题。RocketMQ 提供了事务消息功能,通过这个功能,可以确保在发送端和接收端之间的数据一致性。下面是基于 RocketMQ 事务消息解决分布式场景下的数据一致性问题的基本思路:
在RocketMQ中,事务消息是一种特殊的消息类型,它们与本地事务绑定在一起。具体来说,当生产者发送事务消息时,RocketMQ不会立即将消息投递给消费者,而是会先发送 (prepare)半消息,然后MQ会响应给生产者收到半消息,生产者再执行本地事务。在生产者本地事务成功执行后,会发送给MQ commit ;如果生产者本地事务执行失败,会发送给MQ rollback 。MQ收到commit 后,会投递消息给消费者消费;收到 rollback 后,MQ将消息标记为“回滚”,不会投递消息给消费者,之后删除(prepare)半消息。
虽然RocketMQ提供了这种机制,但它并不涵盖所有分布式事务的应用场景。在复杂的分布式事务场景中,可能需要借助其他技术或工具来实现更强大的事务管理和控制。常见的选择包括使用分布式事务框架(如Seata)、基于消息队列的分布式事务方案(如RocketMQ和Spring Cloud Stream的集成)、以及在业务逻辑层面设计幂等性和补偿机制等。
RocketMQ并没有提供原生的分布式事务支持。RocketMQ提供的事务消息机制仅在某些场景下可以实现分布式事务的最终一致性,但它并不是一个原生的、全面的分布式事务解决方案。
热门数据接口耗时长解决
处理热门数据接口耗时长的问题需要一些系统性的方法来识别瓶颈并解决它们。以下是一些可能的解决方法:
-
性能监控与分析:使用性能监控工具来跟踪热门数据接口的性能指标,如响应时间、吞吐量等。分析监控数据,找出性能瓶颈所在。
-
数据库优化:优化数据库查询和索引,以减少数据检索时间。使用数据库缓存技术,如缓存查询结果或使用缓存层来减轻数据库负载。
-
并发处理:通过增加服务器资源或优化并发处理能力来提高接口的响应速度。采用异步处理、多线程或分布式计算等技术来提高并发处理能力。
-
缓存机制:对热门数据接口的结果进行缓存,减少重复计算和数据查询的开销。选择合适的缓存策略,如基于时间、基于内容的缓存等。
-
分布式架构:将系统设计为分布式架构,通过水平扩展来提高系统的容量和性能。采用负载均衡、分布式缓存等技术来分担压力。
-
代码优化:优化接口代码,减少不必要的计算和数据处理操作。避免在请求处理过程中阻塞线程或产生死锁等性能问题。
-
请求限流与熔断:对热门接口进行请求限流,防止过多的请求同时涌入。采用熔断机制来防止接口过载导致系统崩溃。
-
故障排除与优化迭代:定期对系统进行故障排除和性能优化,不断改进系统架构和代码实现,以适应不断变化的需求和负载。
综合考虑以上方法,并根据具体情况选择合适的解决方案,可以有效地提高热门数据接口的性能和稳定性。
数据库优化
数据库优化可以在很大程度上改善接口耗时问题,因为数据库通常是许多应用程序的关键组成部分之一。下面是一些可以采取的数据库优化策略,以解决接口耗时的问题:
-
查询优化:
- 优化查询语句:确保查询语句是有效且高效的,避免不必要的连接和子查询。可以通过分析执行计划(Explain Plan)来确定查询的性能瓶颈,并进行相应的优化。
- 使用索引:根据查询的条件和排序方式选择合适的索引,以加速数据检索。避免全表扫描,尽量利用索引来提高查询性能。
-
缓存机制:
- 结果缓存:对于频繁查询但数据变化不频繁的接口,可以将查询结果缓存起来,避免重复查询数据库。缓存可以使用内存缓存(如 Redis、Memcached)或分布式缓存(如 Redis Cluster)来实现。
- 查询缓存:某些数据库(如 MySQL)支持查询缓存,可以缓存查询结果以加速相同查询的执行。但需要注意的是,查询缓存可能会因为数据更新频繁而导致缓存失效,需要谨慎使用。
-
数据库结构优化:
- 正规化与反规范化:合理设计数据库表结构,确保数据结构的正规化程度符合实际需求。在性能要求高的场景下,可以考虑使用反规范化来减少连接操作,提高查询性能。
- 分区表:对于大型数据表,可以根据数据的特性进行分区,以减少单个表的数据量,提高查询和维护的效率。
-
数据库连接池:
- 合理配置数据库连接池的参数,包括最大连接数、最小空闲连接数、连接超时时间等。确保数据库连接池能够有效地管理数据库连接,避免连接过多或过少的情况发生。
-
索引优化:
- 定期检查和优化索引,确保索引的更新频率与查询需求相匹配。避免创建过多、过大或不必要的索引,以减少索引维护的开销。
-
批量操作与异步处理:
- 对于需要批量处理的数据操作,尽量使用批量操作接口或批量 SQL 语句来提高效率。
- 将耗时的数据操作异步化处理,通过消息队列等技术实现异步数据处理,避免阻塞接口的响应。
-
垂直和水平扩展:
- 如果数据库服务器的负载过重,可以考虑垂直扩展(Vertical Scaling)通过升级硬件来提升性能,或者水平扩展(Horizontal Scaling)通过添加更多的数据库实例来分担负载。
综上所述,数据库优化是解决接口耗时问题的重要手段之一。通过合理的数据库设计、查询优化、缓存机制、连接池配置等措施,可以显著提高接口的响应速度和性能表现。
并发处理
并发处理是解决接口耗时问题的重要策略之一,特别是在处理大量请求时,有效地利用并发处理能够显著提高系统的性能和吞吐量。以下是一些可以采取的并发处理策略:
-
多线程处理:
- 使用多线程技术来同时处理多个请求,将请求分配给不同的线程进行处理。这样可以利用多核处理器的优势,并发地执行请求处理逻辑,缩短单个请求的处理时间。
- 需要注意线程安全和资源竞争的问题,确保线程之间的数据共享和同步是安全的。
-
线程池:
- 使用线程池来管理和复用线程资源,避免频繁地创建和销毁线程带来的开销。
- 通过合理配置线程池的大小、队列容量和线程超时时间等参数,可以有效地控制并发度和资源消耗。
-
异步处理:
- 将耗时的操作(如数据库查询、网络请求等)改为异步执行,通过回调函数或事件驱动的方式处理异步结果。
- 对于支持非阻塞 I/O 的操作系统和框架,可以使用非阻塞 I/O 技术来实现异步处理,提高系统的并发能力和响应速度。
-
并行计算:
- 对于需要大量计算的任务,可以采用并行计算技术来同时处理多个计算任务,提高计算效率和速度。
- 可以利用多核 CPU、GPU 等硬件加速器来进行并行计算,或者使用分布式计算框架来将任务分发到多台计算节点进行并行处理。
-
流水线处理:
- 将请求处理过程分解为多个阶段,并将每个阶段的处理结果传递给下一个阶段,形成一个处理流水线。这样可以并发地执行不同阶段的处理逻辑,提高处理效率。
- 通过合理设计流水线的阶段和任务分配方式,可以最大程度地利用系统资源和提高处理性能。
-
负载均衡:
- 使用负载均衡器来将请求分发到多个服务器节点进行处理,以提高系统的吞吐量和可伸缩性。
- 可以采用基于轮询、权重、最少连接数等策略来进行负载均衡,根据服务器的负载情况动态调整请求的分发策略。
通过合理地利用并发处理技术,可以显著提高系统的并发能力和处理性能,从而缩短接口的响应时间,提高用户体验。但需要注意避免过度并发导致资源竞争、阻塞或性能下降的问题,需根据实际情况进行合理的并发控制和调优。
缓存机制
缓存机制是一种常用的优化手段,用于解决接口耗时的问题。通过缓存机制,可以将接口的结果缓存起来,在下次请求时直接返回缓存结果,避免重复计算和数据查询,从而提高接口的响应速度和性能。以下是一些常见的缓存机制以及它们如何解决接口耗时的问题:
-
结果缓存:
- 将接口的结果缓存起来,下次请求时直接返回缓存结果,而不需要重新计算或查询数据库。
- 结果缓存适用于那些计算开销较大或查询频率较低但结果不经常变化的接口。
-
查询缓存:
- 缓存查询语句及其结果,对于相同的查询请求直接返回缓存结果,而不需要执行实际的数据库查询操作。
- 查询缓存适用于那些查询频率较高但数据变化频率较低的接口,可以有效减少数据库查询的开销。
-
数据缓存:
- 缓存接口所需的数据,而不是缓存接口的结果。这种方式可以避免数据的重复计算和查询,提高接口的性能和响应速度。
- 数据缓存适用于那些需要频繁访问的数据,如用户信息、配置信息等,可以将这些数据缓存到内存或分布式缓存中,以加速数据访问。
-
页面缓存:
- 将接口返回的页面内容缓存起来,下次请求时直接返回缓存页面,而不需要重新生成页面内容。
- 页面缓存适用于静态页面或动态页面中内容变化不频繁的部分,可以减少页面生成和渲染的时间,提高页面的加载速度。
-
缓存失效策略:
- 对于缓存中的数据,需要制定合适的失效策略,以确保缓存数据与实际数据的一致性。
- 可以根据数据的更新频率、重要性和缓存容量等因素来选择合适的失效策略,如基于时间、基于事件或基于LRU(Least Recently Used)等策略。
综上所述,通过合理使用缓存机制,可以显著提高接口的响应速度和性能,降低系统的负载和数据库压力,从而改善用户体验和系统的可扩展性。但需要注意缓存数据的一致性和有效性,及时更新缓存数据以保证数据的准确性和可靠性。
OOM的原因及解决方法
原因
Java 中的 OutOfMemoryError (OOM) 是一种常见的运行时异常,通常由以下几个原因导致:
-
内存泄漏:
- 最常见的原因之一是内存泄漏。当程序中的对象无法被垃圾回收器回收时,就会造成内存泄漏。这可能是因为代码中持有了不再需要的对象引用,导致这些对象无法被释放。
-
对象生命周期过长:
- 在某些情况下,对象的生命周期过长也会导致内存占用过高。例如,长时间运行的应用程序中,可能会创建大量临时对象,但这些对象没有及时被释放,导致内存使用量不断增加。
-
内存资源不足:
- Java 程序运行在 JVM(Java 虚拟机)中,如果 JVM 分配给程序的堆内存不足,就会导致 OutOfMemoryError。这可能是因为程序运行的数据量过大,超出了 JVM 的内存限制。
-
不当的递归调用:
- 如果程序中存在深度递归调用,可能会导致栈溢出(StackOverflowError)。这通常发生在递归调用没有正确终止或终止条件不当的情况下。
-
大对象创建:
- 在创建大对象时,如果内存空间不足以容纳这些对象,就会发生 OutOfMemoryError。例如,大数组、大集合或大文件的创建可能会耗尽内存资源。
-
过多的线程:
- 每个线程都会占用一定的内存空间,如果创建了过多的线程,就会消耗大量的内存资源。当线程数超出 JVM 能够分配的内存限制时,就会发生 OutOfMemoryError。
-
不合理的内存使用:
- 如果程序中存在大量的不合理的内存使用,比如大量的字符串拼接、不必要的对象复制等,都会增加内存消耗,可能导致内存耗尽。
在面对 OutOfMemoryError 时,通常需要通过内存分析工具(如VisualVM、MAT)来分析内存使用情况,找出内存泄漏或者内存占用过高的原因,并对代码进行优化或者增加内存配置以解决问题。
哪些错误编码可以导致OOM
OutOfMemoryError(OOM)通常是由于程序运行时无法再分配足够的内存空间,导致无法继续执行而触发的。以下是一些常见的代码错误或情况,可能导致 OutOfMemoryError 的发生:
-
创建大量对象:
- 在循环或递归中创建大量对象,尤其是大对象(如大数组、大集合),可能会耗尽堆内存,导致 OutOfMemoryError。
-
内存泄漏:
- 当程序中持有对对象的引用但不再需要这些对象时,这些对象就无法被垃圾回收器回收,从而导致内存泄漏。长时间运行的应用程序中,如果频繁创建对象而不释放,可能会最终耗尽内存。
-
缓存溢出:
- 缓存是一种常见的优化手段,但如果没有合理的缓存管理策略,可能会导致缓存中的对象不断增加,最终耗尽内存。
-
线程过多:
- 每个线程都会占用一定的内存空间,如果创建了过多的线程,可能会耗尽 JVM 的内存资源,导致 OutOfMemoryError。
-
大量字符串操作:
- 在字符串拼接、字符串格式化等操作中,如果频繁创建大量的字符串对象,可能会消耗大量的内存资源,导致内存溢出。
-
不当的递归调用:
- 如果递归调用没有正确终止或终止条件不当,可能会导致栈溢出(StackOverflowError),进而影响到堆内存的分配。
-
大对象创建:
- 创建过大的对象,如大数组、大集合或大文件等,可能会导致内存空间不足,从而触发 OutOfMemoryError。
-
类加载器泄漏:
- 如果自定义的类加载器没有正确释放对已加载类的引用,可能会导致类加载器泄漏,最终耗尽永久代内存(如果是使用永久代进行类加载的情况),进而触发 OutOfMemoryError。
这些错误代码可能导致 OutOfMemoryError 的发生,程序员应该在开发和测试阶段注意这些问题,并通过适当的代码优化、内存管理和调优措施来避免内存耗尽的情况发生。
如何排查解决OOM
排查和解决 OutOfMemoryError(OOM)通常需要以下步骤和方法:
-
查看错误信息:
- 当程序抛出 OutOfMemoryError 时,通常会包含一些异常堆栈信息,其中可能包含有用的线索,例如出现问题的代码行号或者涉及到的对象类型。
-
内存分析工具:
- 使用内存分析工具(如VisualVM、MAT、YourKit等)来检查内存使用情况。这些工具可以帮助你查看堆内存中的对象分布、对象引用关系等信息,帮助定位内存泄漏或内存占用过高的原因。
-
检查代码:
- 仔细检查代码,寻找可能导致内存泄漏或内存占用过高的地方。特别注意可能存在的以下情况:
- 是否有大量对象的创建而未被释放?
- 是否有不必要的对象引用持有导致无法被垃圾回收?
- 是否有大对象或大数组的创建导致内存耗尽?
- 是否有大量字符串操作或缓存操作导致内存占用过高?
- 仔细检查代码,寻找可能导致内存泄漏或内存占用过高的地方。特别注意可能存在的以下情况:
-
检查堆内存配置:
- 检查 JVM 的堆内存配置,包括最大堆内存(-Xmx)、初始堆内存(-Xms)等参数是否合理。如果堆内存设置过小,可能会导致内存不足而触发 OutOfMemoryError。
-
分析内存溢出原因:
- 根据错误信息和内存分析工具的输出,尝试确定内存溢出的具体原因。是因为堆内存耗尽导致的 OutOfMemoryError,还是由于其他原因导致的内存溢出?
-
优化代码和资源管理:
- 根据排查结果,对可能存在的问题进行代码优化和资源管理。例如,释放不再使用的对象引用、减少不必要的对象创建、优化缓存机制、增加内存资源等。
-
重启服务:
- 如果在排查过程中无法找到明显的问题或解决方案,可以尝试重启服务来释放所有资源,并监控服务重新运行后的内存使用情况。
-
持续监控:
- 对于长时间运行的服务,建议定期进行内存监控和性能分析,及时发现和解决潜在的内存问题,确保系统的稳定性和可靠性。
通过以上排查和解决步骤,通常可以找到并解决导致 OutOfMemoryError 的根本原因,从而提高系统的稳定性和性能。
GC问题和解决方法
GC问题
在 JVM(Java 虚拟机)中,垃圾收集(GC)问题可能会导致应用程序的性能下降、内存泄漏、应用程序暂停等一系列问题。以下是一些常见的与 GC 相关的问题:
-
频繁的 Full GC:
- Full GC 是一种耗时较长的垃圾收集,会导致应用程序的暂停时间较长。如果 Full GC 发生频繁,会影响应用程序的性能和响应速度。
-
内存泄漏:
- 内存泄漏是指程序中存在持续引用但不再需要的对象,导致这些对象无法被垃圾回收器回收。随着时间的推移,泄漏的对象会越来越多,最终导致内存耗尽或 OutOfMemoryError。
-
对象生命周期过长:
- 如果应用程序中的对象生命周期过长,可能会导致垃圾收集器无法及时释放这些对象,从而造成堆内存的持续增长和内存占用过高。
-
堆内存配置不合理:
- 如果 JVM 的堆内存配置过小,可能会导致频繁的垃圾收集和内存回收,从而影响应用程序的性能。而如果堆内存配置过大,会增加垃圾收集器的停顿时间,影响应用程序的响应速度。
-
对象创建速度过快:
- 如果应用程序中频繁创建大量的对象,垃圾收集器可能无法及时回收这些对象,导致内存占用过高和 GC 暂停时间过长。
-
GC 线程过多:
- 如果 JVM 中的 GC 线程过多,可能会导致竞争和调度开销增加,影响 GC 的效率和性能。
-
大对象分配:
- 如果应用程序中频繁创建大对象,可能会导致堆内存碎片化和分配失败,从而触发 Full GC 或者导致内存分配失败。
-
GC 日志分析:
- 通过分析 GC 日志,可以发现垃圾收集器的运行情况和效率,从而找出 GC 问题的根本原因,进行相应的优化和调整。
以上是一些常见的与 GC 相关的问题,解决这些问题通常需要进行内存分析、性能优化和堆内存调优等工作。
解决方式
针对与 GC 相关的问题,可以采取以下一些解决方法:
-
内存泄漏排查:
- 使用内存分析工具(如VisualVM、MAT)来检查内存使用情况,查找可能存在的内存泄漏。定位到内存泄漏的代码,逐步分析并修复,确保不再持有不必要的对象引用。
-
优化对象生命周期:
- 确保对象的生命周期尽可能短,避免长时间持有对象引用。对于临时性的对象,及时释放引用以便垃圾回收器回收。
-
合理配置堆内存:
- 根据应用程序的内存需求和性能要求,合理配置 JVM 的堆内存大小。通过调整 -Xmx 和 -Xms 参数,避免堆内存过小或过大导致的性能问题。
-
优化 GC 参数:
- 根据应用程序的特性和负载情况,调整 GC 相关的参数,以优化 GC 的效率和性能。例如,选择合适的垃圾收集器(Serial GC、Parallel GC、CMS GC、G1 GC等)和相应的参数配置。
-
避免大对象分配:
- 尽量避免创建过大的对象,尤其是大数组和大集合。可以通过优化数据结构和算法,分批处理大数据,或者使用对象池等技术来避免频繁分配和释放大对象。
-
优化代码和资源管理:
- 对存在性能问题的代码进行优化,避免不必要的对象创建、拷贝和持有。合理使用缓存机制,避免缓存溢出或内存泄漏的问题。
-
GC 日志分析和监控:
- 分析 GC 日志,了解垃圾收集器的运行情况和性能瓶颈。根据分析结果,针对性地调整参数和优化代码,以提高 GC 的效率和性能。
-
内存压力测试:
- 运行内存压力测试,模拟不同负载情况下的内存使用情况,观察系统的稳定性和性能表现。根据测试结果,及时调整配置和优化代码,保障系统的稳定性和可靠性。
综上所述,解决与 GC 相关的问题需要综合考虑内存分析、性能优化和配置调优等多方面因素,根据具体情况采取合适的解决方案和措施。
死锁的原因和解决方法
死锁出现的原因
死锁是多线程编程中常见的一种并发问题,通常发生在多个线程之间,彼此互相等待对方释放资源而无法继续执行的情况。死锁的主要原因包括以下几个方面:
-
互斥锁:
- 多个线程之间竞争对共享资源的访问权限,如果一个线程已经获取了某个资源的锁,其他线程就无法同时获取该资源的锁。如果多个线程相互等待对方释放锁,就可能导致死锁。
-
资源竞争:
- 多个线程同时竞争多个资源的访问权限,并且每个线程都持有一部分资源的锁,但需要其他线程持有的资源才能继续执行。如果多个线程之间形成了循环等待对方持有的资源,就可能导致死锁。
-
嵌套锁:
- 当一个线程在持有一个锁的同时,尝试获取另一个锁,而另一个线程持有另一个锁并试图获取第一个线程已持有的锁时,就可能出现嵌套锁导致的死锁。
-
锁的顺序问题:
- 如果多个线程获取锁的顺序不一致,并且在等待对方释放锁时出现了交叉等待的情况,就可能导致死锁。比如线程A先获取锁1再获取锁2,线程B先获取锁2再获取锁1,就可能导致死锁。
-
线程调度问题:
- 如果多个线程之间的执行顺序和线程调度策略不确定,就可能导致死锁。例如,如果线程A和线程B同时尝试获取锁,并且在同一时刻都处于等待状态,但线程调度器又没有足够的策略来保证其中一个线程能够先获取锁,就可能导致死锁。
综上所述,死锁的原因主要包括互斥锁、资源竞争、嵌套锁、锁的顺序问题和线程调度问题等多个方面。在编写多线程程序时,需要注意避免这些情况的发生,以减少死锁的可能性。常见的解决死锁的方法包括合理设计锁的粒度、按顺序获取锁、避免嵌套锁、使用超时机制和死锁检测等。
如何预防和解决
预防和解决死锁是多线程编程中的重要问题,以下是一些常见的预防和解决死锁的方法:
预防死锁:
-
避免嵌套锁:
- 尽量避免在持有一个锁的同时去获取另一个锁,以减少死锁的可能性。
-
按顺序获取锁:
- 统一约定锁的获取顺序,所有线程都按照相同的顺序获取锁,避免出现交叉等待的情况。
-
锁粒度设计:
- 设计合理的锁粒度,尽量将锁定的范围缩小到最小,减少多个线程之间的竞争,从而减少死锁的可能性。
-
避免长时间持有锁:
- 尽量避免在持有锁的同时执行耗时较长的操作,及时释放锁以让其他线程获取资源。
-
使用线程安全的并发工具:
- 使用 Java 并发包中提供的线程安全的数据结构和工具类,避免手动管理锁造成的潜在问题。
-
死锁检测:
- 使用死锁检测工具或者编写代码进行周期性的死锁检测,及时发现并解决潜在的死锁问题。
解决死锁:
-
终止并重试:
- 当检测到死锁时,可以尝试中断其中一个或多个线程,并重新尝试获取资源或执行操作。
-
超时等待:
- 在获取锁的过程中添加超时等待机制,当超过一定时间仍无法获取到锁时,放弃当前操作并进行重试或者其他处理。
-
资源预分配:
- 提前分配所需的资源,避免在程序运行过程中动态申请资源导致死锁。
-
避免饥饿:
- 确保每个线程都有机会获取所需资源,避免出现某个线程永远无法获取资源而处于饥饿状态。
-
合理设计算法:
- 设计合理的算法和数据结构,避免出现不必要的竞争和等待,减少死锁的发生。
-
使用专业工具:
- 使用专业的性能分析工具和调试工具,如VisualVM、MAT等,帮助定位和解决死锁问题。
通过以上预防和解决死锁的方法,可以有效地降低多线程编程中出现死锁的概率,提高系统的稳定性和可靠性。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









