







1、简介
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。是一种使用表达式的方式对字符串进行匹配的语法规则。
2、语法
使用元字符进行排列组合用来匹配字符串
3、在线测试
3.1 oschina
https://tool.oschina.net/regex
3.2 菜鸟编程
https://c.runoob.com/front-end/854/
4、元字符
元字符:具有固定含义的特殊字符
常用元字符:
| 符号 | 含义 | 符号 | 含义 | |
|---|---|---|---|---|
| . | 匹配除换行符以外的任意字符 | |||
| \w | 匹配字母或数字或下划线 | \W | 匹配非字母或数字或下划线 | |
| \d | 匹配数字 | \D | 匹配非数字 | |
| \s | 匹配任意的空白符 | \S | 匹配非空白符 | |
| \n | 匹配一个换行符 | \t | 匹配一个制表符 | |
| ^ | 匹配字符串的开始 | $ | 匹配字符串的结尾 | |
| a|b | 匹配字符a或字符b | ( ) | 匹配括号内的表达式,也表示一个组 | |
| […] | 匹配字符组中的字符 | [^…] | 匹配除了字符组中的字符之外的所有字符 |
5、量词
控制前面的元字符出现的次数
| 符号 | 含义 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
6、贪婪匹配和惰性匹配
| 符号 | 含义 |
|---|---|
| .* | 贪婪匹配 |
| .*? | 惰性匹配 |
| 在爬虫的编写过程中,我们使用最多的就是惰性匹配 |
某位大佬写的文章很详细
Python正则表达式指南
7、案例
7.1 匹配数字
s = '123abe123中国馆的'
re_pat = '\d' #模式,提取数字
re.findall(re_pat,s)

7.2 匹配英文
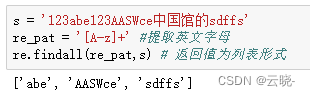
re_pat = '[A-z]+' #提取英文字母
re.findall(re_pat,s) # 返回值为列表形式
7.3 匹配中文
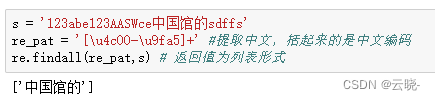
re_pat = '[\u4c00-\u9fa5]+' #提取中文,括起来的是中文编码
re.findall(re_pat,s) # 返回值为列表形式
7.4 点
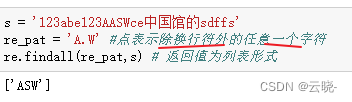
7.5 点+星
















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









