







引用
参考
即变量的别名
- 引用变量是另一个变量的别名,他没有自己的内存地址,只会 与它所引用的变量的内存地址相关联,因此不先声明后赋值(Ex: int &var1 ; var1 = var2),就像喊一个不实际存在的人的小名一样,是错误的,必须在声明时初始化它。
- 函数按引用传递,引用传值是传的实参列表中每个变量的引用,每次改变形参的值,都会改变实参的值,因为他俩指向同一块内存区域。
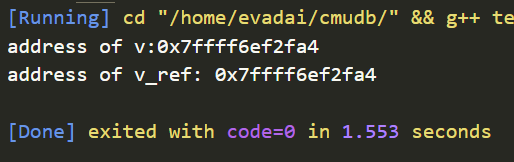
演示函数传的引用变量与实参的地址相同
#include <iostream>
#include <unordered_map>
using namespace std;
void show_ref(int& v){
cout <<"address of v_ref: "<< &v << endl;
}
int main(){
int var = 10;
cout << "address of v:" << &var << endl;
show_ref(var);
return 0;
}
- 引用不可改变??接近const指针

互斥锁
大致模板见leetcode多线程编程
std::mutex mu;//互斥量
std::condition_variable cv;//条件变量
bool var;//标志量
...
void f(){
//在作用域内,用RAII安全unlock的方式加锁,
//作用类似于在"{"处加锁,在"}"处解锁,但如果在加锁后出现运行错误仍然可以安全解锁
std::unique_lock<std::mutex> lock(mu);
//当满足1.lock阻塞; 2.var为false时(不满足某些条件,不能运行),
//先解锁unlock(mu)!!,再阻塞线程
//当运行cv.notify_all(),检查var是否为true,若成立则不阻塞线程,并加锁!!
cv.wait(lock, [&](){return var; });
...该线程运行的操作...
//操作结束后,考虑唤醒别的线程
cv.notify_all();
}
为什么要强调wait()是先解锁再阻塞呢,因为考虑运行逻辑时,在每个线程开头都会上锁(unique_lock),那么当有多个线程时,在第一个线程上锁以后,若不是正确顺序的那一个(wait不阻塞),会因状态量false,阻塞不前。导致:上锁的那个线程无法解锁,别的线程将永远得不到锁,这不就进入死锁的状态了吗!?
因此wait()函数在阻塞前,解锁这一步很关键,它能让自己线程不运行,也运行别的线程得到锁。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









