







做了11天,思路不难,就是小错误恶心人。建议以后所有lab快点写出来,然后花3~4倍时间debug…
主要说一下3个部分写点啥,directory与bucket在整体哈希表中作用是什么,还有一些坑点。
hash_table_directory_page
一个directory是一个Page
directory_page的key-to-bucket_page_id原理
directory的作用是根据key的hash找到对应的bucket_page对象,再进行其他serach or insert otr remove操作。hash value截取后global_depth位就是bukcet_index,对应一个存放bucket_page_id的数组的下标,就是说key->Hash->bucket_index通过数组下标到值的映射就能得到bucket_page_id,最后通过buffer_pool_manager_能Fetch到bucket_page。
global_depth与local_depth作用
global_depth是最大的local_depth,用桶的local_depth才能得到桶真正对应的Hash值,若仅用global_depth会造成多个Hash对应同一个桶的ambigous情况。因为不同桶装的数据量不一样,比如仅用一个桶就能装下结尾为0的key-value数据,但需要2个桶来装下结尾为1的数据,这时虽然有00,01,10,11这4个桶,global_depth = 2,但00和10都是指向同一个存放结尾为0的bucket_page,这个bucket_page的local_depth = 1,所以桶真正对应的hash值其实是0,通过local_depth取,而不是00或01。
实际用到local_depth的地方是在insert和merge,详细的后面讲。例如insert_split中,改变bucket_idx到bucket_page_id的映射。例如原先标识桶(bucket_page)的Hash是xxx,现在这个桶装满了,分成2个桶装:0xxx与1xxx,这个重新分装的过程为reHash。此时就要通过local_depth获得标识桶的真实Hash值,即xxx,在此基础上加一位0或1来获得新的bucket_idx。可能原本这两个bucket_idx:0xxx与1xxx都是对应一个page_id,现在要改变映射到不同page_id。
hash_table_bucket_page
一个桶是一个Page
bucket_page存取数据原理
对桶进行数据操作,主要是insert与remove,isEmpty(判断Merge)与isFull(判断Split)会被其他类使用,桶存放数据的数据类型是一个存放Mappingtype的数组,大小为BUCKET_ARRAY_SIZE = 496,怎么判断有没有读到非法的位置呢?需要readable_数组标志数组的每一项是不是有存放数据,比如insert操作中在数组的第i位存放数据时,就要将readable数组的第i位置1,remove操作则将对应位置0,就在逻辑上删除了数据,occupied_数组则是如果在某个位置插入过数据会置1,从未插入过则为0,所以置为1后永远不会置为0,在初期用于检索数据时提前结束。这2个标志数组是一个char类型数组,大小为496 / 8,也就说char元素的每一位标志了数组中的一个位置。
至于为什么是这个数字,头文件中有详细说明,主要是为了在Page的Data部分(Size = 4096)reinterpreter_cast成BUCKET_PAGE时不报错,两者大小要一致,所以计算得出了这个大小。
每条key-value在桶中的存放位置是随机的,找某条key-value只能遍历。
Insert
之前没注意,单线程测试过了以为这块没什么问题,但并发测试会出现bucket存了2条一样key-vlaue值的问题,两种写法有细微的区别,Wrong Version是找到一个空位就跳出来,对相同k-v检测只到空位之前,即使bucket后面出现了相同的k-v值也不会被检测出来,Correct Version是要确定桶中没有相同k-v才返回free_pos。

这种细节真的很重要,很搞笑的是CMU单纯关于insert的测试用例,无论是单线程还是多线程都没测出来这个问题,只有到与remove一起的并发测试用例才报错,这时候就很难找问题,有可能是加锁问题,或者remove问题,总之很难,,,我找了2天,在各种锁的地方打log,但其实并不是锁的问题。。。
另外,真的要仔细看报错信息,res.size()=2还是能说明问题的,之前心态崩了,一直在做无用的debug,就算很麻烦也要好好看报错信息才能找到问题。。。
// Wrong Insert
int free_pos = -1;
// LOG_INFO("full size %lld", static_cast<long long>(BUCKET_ARRAY_SIZE));
for (uint32_t i = 0; i < BUCKET_ARRAY_SIZE; i++) {
if (IsReadable(i) && cmp(array_[i].first, key) == 0 && array_[i].second == value) {
LOG_INFO("INSERT FASLE TYPE 1");
return false;
}
if (!IsReadable(i)) {
// LOG_INFO("%d is unReadable, can insert", i);
free_pos = i;
break;
}
}
if (free_pos == -1) {
LOG_INFO("INSERT FASLE TYPE 2");
return false;
}
array_[free_pos] = MappingType(key, value);
SetReadable(free_pos);
SetOccupied(free_pos);
return true;
// Correct Insert
int64_t free_slot = -1;
for (size_t i = 0; i < BUCKET_ARRAY_SIZE; i++) {
if (IsReadable(i)) {
if (cmp(key, array_[i].first) == 0 && value == array_[i].second) {
// already existed the same key & value
// LOG_DEBUG("Same kv");
return false;
}
} else if (free_slot == -1) {
free_slot = i;
}
}
if (free_slot == -1) {
// is full
LOG_DEBUG("Bucket is full");
return false;
}
// insert it and return true
SetOccupied(free_slot);
SetReadable(free_slot);
array_[free_slot] = MappingType(key, value);
return true;
extendible_hash
小函数,类似如何取page_id这种在directory_page中已经说过了。
坑的是小函数封装的没什么用,比如FetchBucketPage返回HASH_TABLE_BUCKET_TYPE类型,他是Page类型的GetData()返回的一块内存,经过reinterpreter_cast转成的类型,但是如果要对这个page加读写锁,还是要用Page类型的对象啊。。所以小函数返回的东西没啥用。。。最后决定不用小函数了呗,全集成在大函数里。
insert
插入前判断一下待插入的桶是不是满了。如果满了,先分裂页面再插入,否则直接插入就行。
坑点是SplitInsert中要注意NewPage是不是空的!如果新页面不是空的,可能的原因是Project1写错了,,
Split_insert流程

简单来说,是先更新global_depth,然后更新directory中key的Hash到bucket_page_id的映射,最后将原来bucket中的数据重新映射到新的bucket_page。
判断要不要增加GD
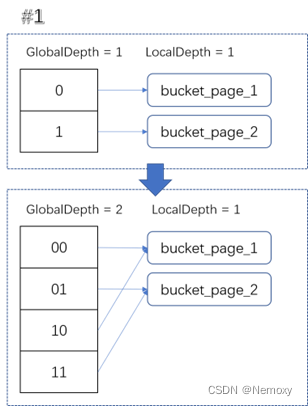
注意要设置新的bucket_index对应的local_depth与bucket_page_id
重新映射bucket_index到bucket_page_id
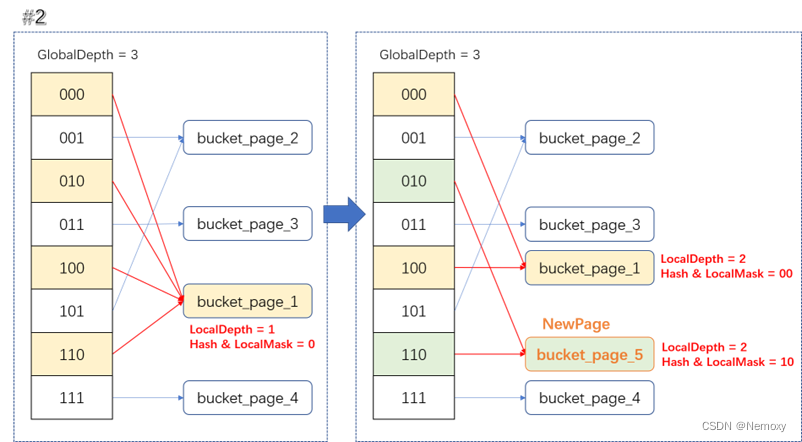 对bucket_idx前面加个1就是bucket_idx_split,偏移1<<local_depth设置相应的local_depth与bucekt_page_id
对bucket_idx前面加个1就是bucket_idx_split,偏移1<<local_depth设置相应的local_depth与bucekt_page_id
reHash
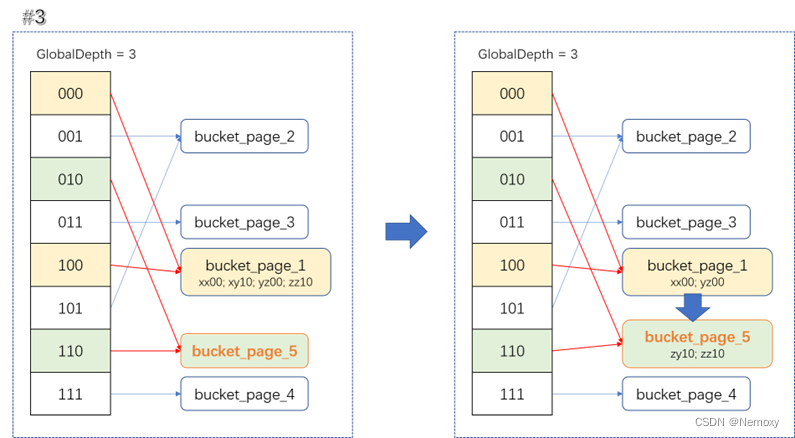 对被分裂桶中的数据重新映射一下,插入到对应的bucket_page中
对被分裂桶中的数据重新映射一下,插入到对应的bucket_page中
remove
先remove数据,删完后判断一下页面isEmpty() == true?是则merge,否则直接返回remove结果。
坑点是可能出现连续merge情况。

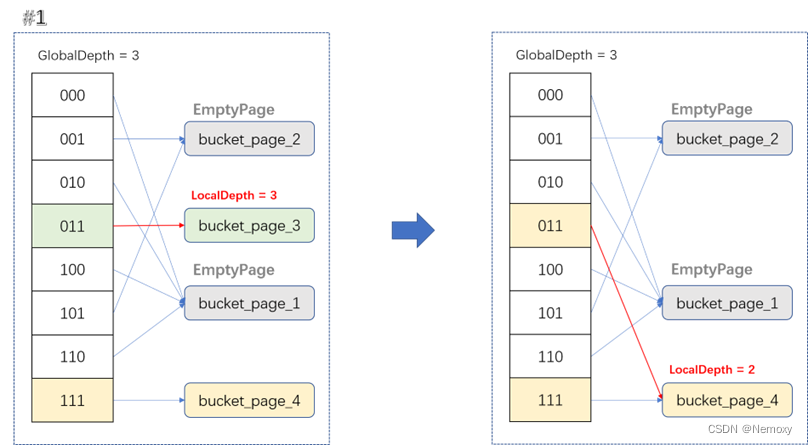
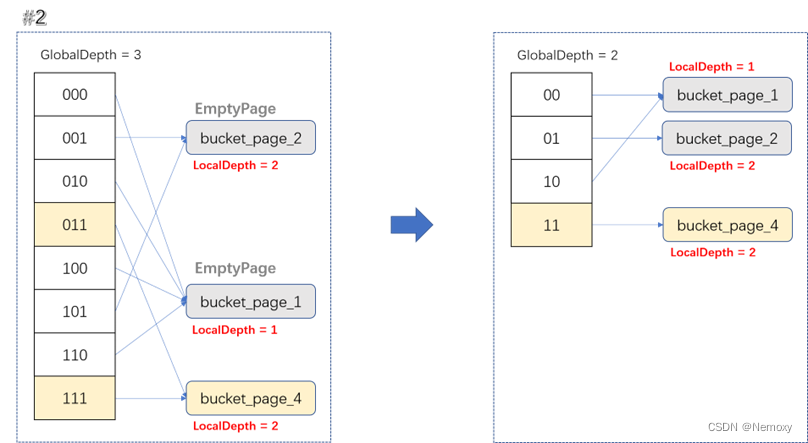
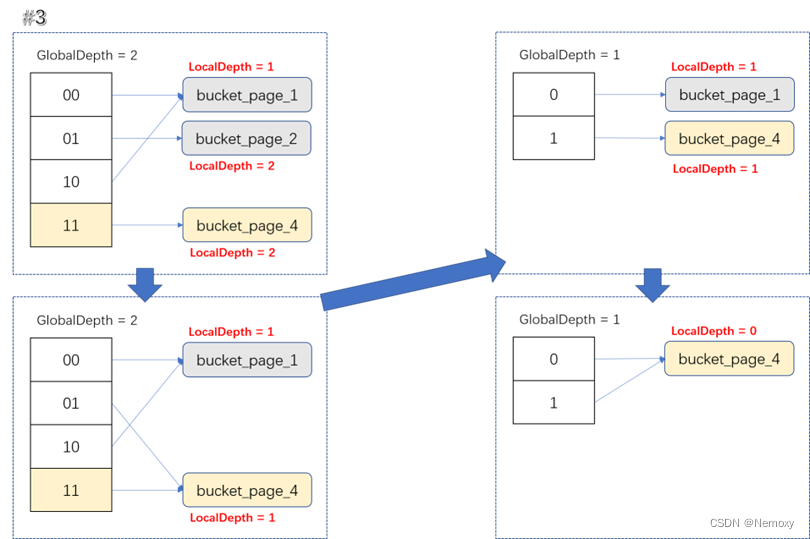 一次删除页面导致多次merge,如local_depth=2的页面为空时,他merge的页面local_depth=3就不能merge,要当merge_page的local_depth=2时才能merge,所以merge_page的local_depth变小的时候会发生2次shrink,会直接使local_depth=1
一次删除页面导致多次merge,如local_depth=2的页面为空时,他merge的页面local_depth=3就不能merge,要当merge_page的local_depth=2时才能merge,所以merge_page的local_depth变小的时候会发生2次shrink,会直接使local_depth=1
concurrent-control
这个好像别的博客都不怎么写,我的写法是在取到page对象后立刻上锁,然后函数返回前解锁,如果函数对这个对象的成员有改写,加WLock(),否则加RLock()。注意在insert时,得到新page以后加立刻对新page加写锁,而remove时,delete页面前要解锁。
一般形式为:
table_latch_.RLock();
Page *directory_page_all = buffer_pool_manager_->FetchPage(directory_page_id_, nullptr);
directory_page_all->RWLatch();
HashTableDirectoryPage *dir_page = reinterpret_cast<HashTableDirectoryPage *>(directory_page_all->GetData());
page_id_t bucket_page_id = KeyToPageId(key, dir_page);
Page *bucket_page_all = buffer_pool_manager_->FetchPage(bucket_page_id, nullptr);
bucket_page_all->RWLatch();
HASH_TABLE_BUCKET_TYPE *bucket_page =
reinterpret_cast<HashTableBucketPage<KeyType, ValueType, KeyComparator> *>(bucket_page_all->GetData());
...
bucket_page_all->RWUnlatch();
buffer_pool_manager_->UnpinPage(bucket_page_id, false);
directory_page_all->RWUnlatch();
buffer_pool_manager_->UnpinPage(directory_page_id_, false);
table_latch_.RUnlock();
return ;
坑点是函数跳转,一般会在函数跳转前把所有锁都解了,所有页面Unpin了,才进入另一个函数,那么进入另一个函数后,中间可能已经轮转到别的线程,因此,转移到新函数的条件可能不满足。例如,我假设满足x=1才进入NewFunc(),那么进入NewFunc()时,可能已经不满足x=1,因此要在新函数里开头处判断一下条件。
最后纪念一下啪~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









