







备注:不是AI训练师的活,但是自己得知道。
数据标注分为:文本标注,图像标注,语音标注。
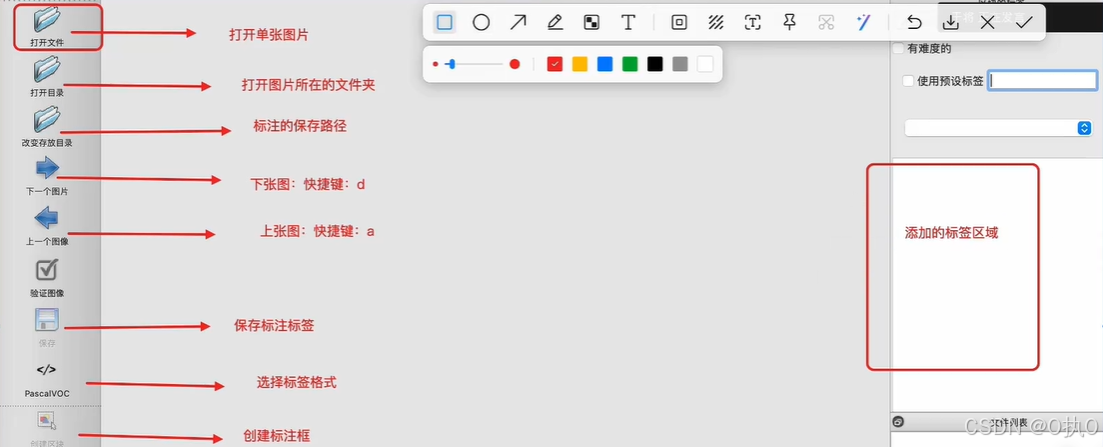
1.1工具,操作介绍labelimg
w为开始标注键
1.2关于标注的目录结构
外层文件夹:dianpu
image:数据集
label:标注1.3标注生成的格式
voc==>生成xml格式,
import xml.etree.ElementTree as ET
import os
def convert_xml_to_txt(xml_file, class_mapping):
# 解析 XML 文件
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像的宽度和高度
size = root.find('size')
img_width = int(size.find('width').text)
img_height = int(size.find('height').text)
txt_lines = []
# 遍历所有的对象
for obj in root.findall('object'):
# 获取类别名称
class_name = obj.find('name').text
if class_name not in class_mapping:
continue
class_id = class_mapping[class_name]
# 获取边界框坐标
bbox = obj.find('bndbox')
xmin = float(bbox.find('xmin').text)
ymin = float(bbox.find('ymin').text)
xmax = float(bbox.find('xmax').text)
ymax = float(bbox.find('ymax').text)
# 计算 YOLO 格式的坐标
x_center = ((xmin + xmax) / 2) / img_width
y_center = ((ymin + ymax) / 2) / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
# 添加到 TXT 文件的行中
txt_lines.append(f"{class_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
return txt_lines
def convert_folder(xml_folder, txt_folder, class_mapping):
# 创建 TXT 文件保存的文件夹
if not os.path.exists(txt_folder):
os.makedirs(txt_folder)
# 遍历 XML 文件夹中的所有文件
for xml_file in os.listdir(xml_folder):
if xml_file.endswith('.xml'):
xml_path = os.path.join(xml_folder, xml_file)
# 生成对应的 TXT 文件路径
txt_file = os.path.splitext(xml_file)[0] + '.txt'
txt_path = os.path.join(txt_folder, txt_file)
# 转换 XML 文件
txt_lines = convert_xml_to_txt(xml_path, class_mapping)
# 写入 TXT 文件
with open(txt_path, 'w') as f:
for line in txt_lines:
f.write(line + '\n')
if __name__ == "__main__":
# 定义类别映射,根据实际情况修改
class_mapping = {
"cat": 0,
"dog": 1
}
# 这里修改为实际存放 XML 文件的文件夹路径
xml_folder = "newdemo/img"
# 这里修改为实际要存放转换后 TXT 文件的文件夹路径
txt_folder = "demo"
convert_folder(xml_folder, txt_folder, class_mapping)yolo==>生成txt格式
crateML==>生成json格式
问题点:因为某种不可抗拒的因素,导致要把某种格式转换成另外一种格式,该怎么办
2.数据源问题
问题点:当数据集中的某些图片不符合要求,比如添加到labelimg之中无效,文件后缀名不符合要求,我们要统一文件名和后缀名怎么办?
a)xml转成txt
主python文件
import os
import os.path as osp
import numpy as np
import cv2
def cv_imread_chinese(file_path):
cv_img = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), cv2.IMREAD_COLOR)
return cv_img
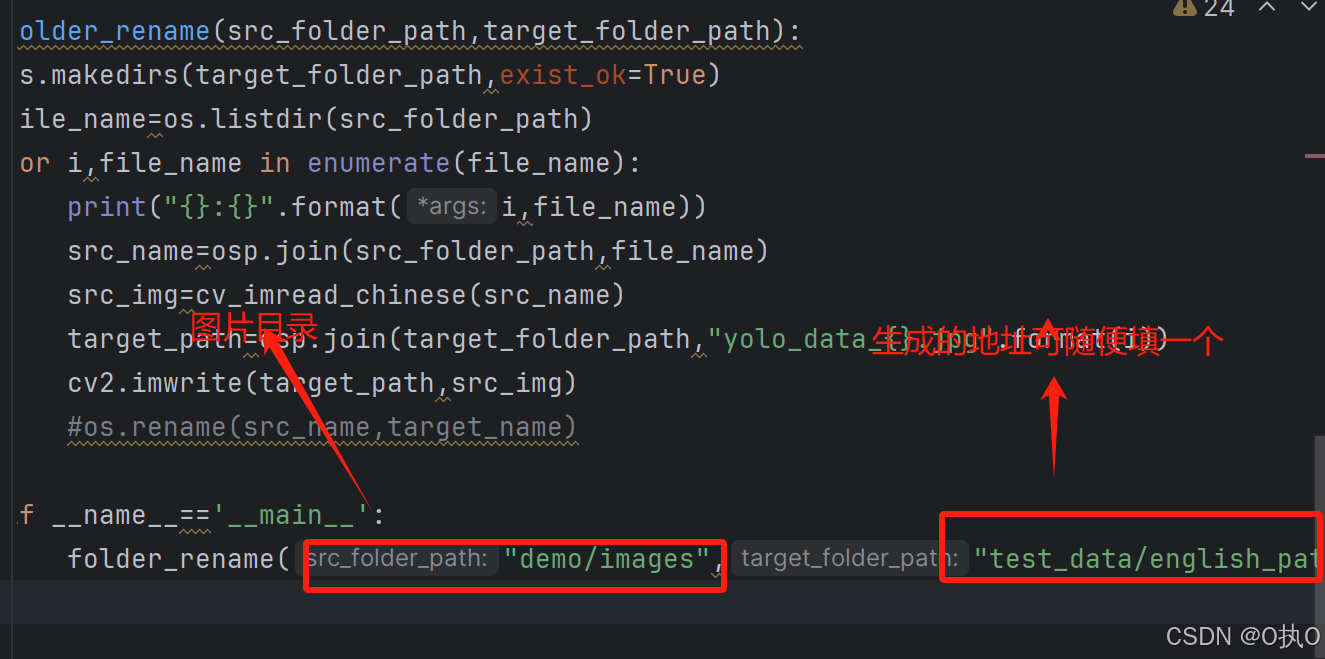
def folder_rename(src_folder_path, target_folder_path):
os.makedirs(target_folder_path, exist_ok=True)
file_names = os.listdir(src_folder_path)
for i, name in enumerate(file_names):
try:
print("{}:{}".format(i, name))
src_name = osp.join(src_folder_path, name)
src_img = cv_imread_chinese(src_name)
target_path = osp.join(target_folder_path, "yolo_data_{}.jpg".format(i))
cv2.imwrite(target_path, src_img)
except Exception as e:
print(f"处理文件 {name} 时出错: {e}")
if __name__ == '__main__':
folder_rename("demo/images/test", "newdemo/img")若提示没有CV2,那么就运行:
安装cv2:pip install opencv-python
定义文件名称和后缀名
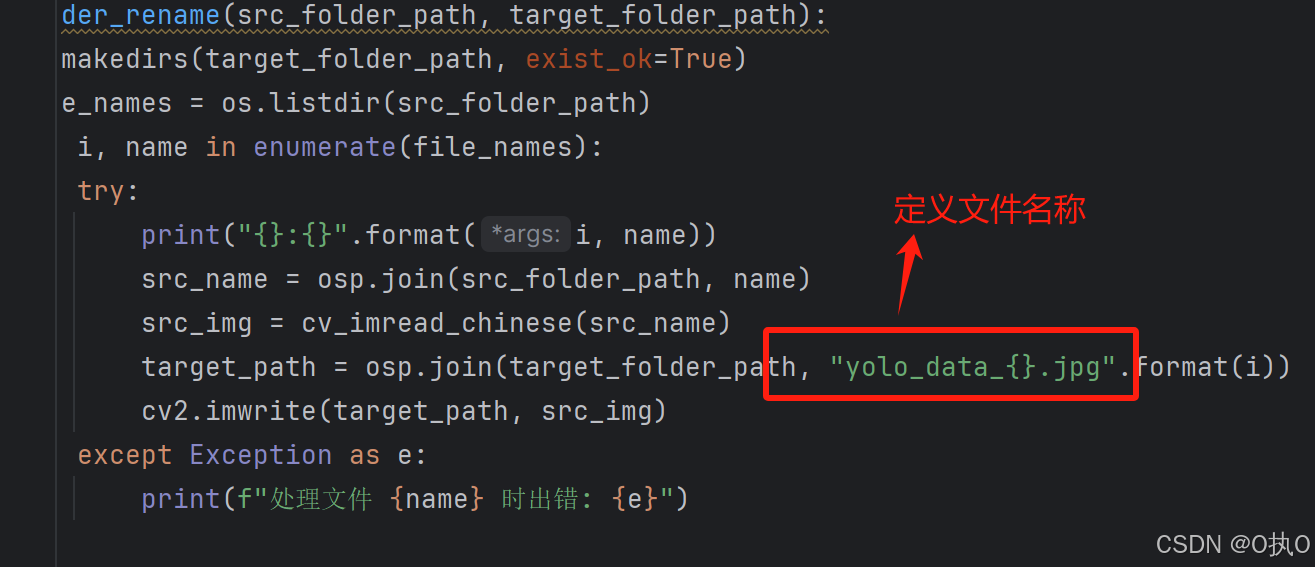
图片目录
3.环境搭建
Anaconda==>安装环境
pip==>安装依赖
Pycharm==>编辑工具
通过python脚本让文件后缀名统一化
3.质检和验收
3.1抽样检查==>单个验收
有验收代码,公司会直接给出,自己要会用
3.2抽样检查==>全部可视化检查
有验收代码,公司会直接给出,自己要会用
备注:可视化检查和labelimg工具检查的区别:
1.如果有覆盖的情况,labelimg很难直接观察到
2.可视化工具会让有更加直观的标注标签显示,labelimg没有
总结:可视化工具质检销量超过labelimg工具质检


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









