Data Member的内存布局:
前言知识:
C++ standard要求:同一个access section中,members的排列只需符合“较晚出现的members在class object中有较高的地址”,也就是members之间可能会出现边界调整的字节填充等。另外编译器还可能会合成内部一些使用的data members比如vptr,但是编译器会讲vptr放在什么位置呢?开头最后?不同的编译器有不同的摆放位置,C++ Standard对于布局所持的是放任的态度。
Vs2008 和g++编译器都是将vptr放在object的开头,验证代码:
class Base {
public:
virtual void f() {
cout << "Base::f" << endl;
}
};
typedef void(*Fun)(void);
int main()
{
Base base;
cout << "vptr:" << (int*)&base << endl; // vptr放在object前端
cout << "虚函数表中第一个函数地址:" << (int*)*((int*)&base) + 0<< endl;
Fun pfun = (Fun)*((int*)*((int*)&base) + 0);
pfun(); // Base::f
return 0;
}
本文从一下几个方面讲述C++的数据布局:(C++ Standard对于布局所持的是放任的态度,不同编译器之间会有差异,下面测试代码仅在vs2008和g++编译器,)
1) 单一继承而且没有多态时的数据布局
2) 单一继承加上多态时(virtual function)的数据布局
3) 多重继承
4) 虚拟继承
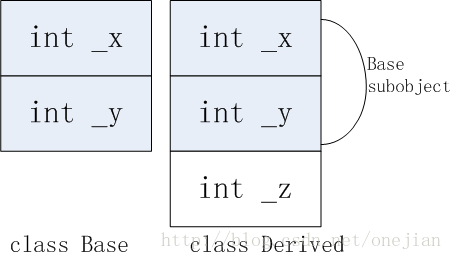
1. 单一继承而且没有多态时的数据布局
派生类从基类继承了数据,此时数据布局
class Base {
public:
Base(): _x(1), _y(2) {}
int _x;
int _y;
};
class Derived : public Base{
public:
Derived():_z(3){}
int _z;
};
int main()
{
Derived d;
cout << "派生类object中_x的地址:" << (int*)&d<<endl; // 0012FF58
cout << "派生类object中_y的地址:" << (int*)&d + 1 <<endl; // 0012FF5c
cout << "派生类object中_z的地址:" << (int*)&d + 2 <<endl; // 0012FF60
cout << "派生类object中_y的值" << *((int*)&d + 0) << endl; // 1
cout << "派生类object中_y的值" << *((int*)&d + 1) << endl; // 2
cout << "派生类object中_z的值" << *((int*)&d + 2) << endl; // 3
return 0;
}
注意考虑字节对齐问题:
class Concrete1 {
private:
}
class Concrete2: public Concrete1 {
private:
}
Concrete1 object大小8字节
Concrete2 object大小是12字节 // 8 + 4
2) 单一继承加上多态时(virtual function)的数据布局
class Base {
public:
Base(): _x(1), _y(2) {}
virtual void foo_1() { cout << "Base::foo_1" << endl; }
virtual void foo_2() { cout << "Base::foo_2" << endl; }
int _x;
int _y;
};
class Derived : public Base{
public:
Derived():_z(3){}
virtual void foo_2(){ cout << "Derived::foo_2" << endl; }
virtual void foo_3(){ cout << "Derived::foo_3" << endl; }
int _z;
};
typedef void(*Fun)(void);
int main()
{
Fun pfun;
Base b;
pfun = (Fun)*((int*)*((int*)&b) + 0);
pfun();
pfun = (Fun)*((int*)*((int*)&b) + 1);
pfun();
Derived d;
pfun = (Fun)*((int*)*((int*)&d) + 0);
pfun();
pfun = (Fun)*((int*)*((int*)&d) + 1);
pfun();
pfun = (Fun)*((int*)*((int*)&d) + 2);
pfun();
return 0;
}
输出结果:
Base::foo_1;
Base::foo_2;
Base::foo_1;
Derived::foo_2;
Derived::foo_3;
内存图如下:
3) 多重继承
class Base {
public:
Base(){}
virtual void foo_1() { cout << "Base::foo_1" << endl; }
virtual void foo_2() { cout << "Base::foo_2" << endl; }
};
class Derived : public Base{
public:
Derived():_z(3){}
virtual void foo_2(){ cout << "Derived::foo_2" << endl; }
virtual void foo_3(){ cout << "Derived::foo_3" << endl; }
int _z;
};
class BaseOther {
public:
BaseOther(): _val(4) {}
virtual void foo_other() { cout << "BaseOther::foo_other" << endl; }
int _val;
};
class DerivedDeep : public Derived, public BaseOther{
public:
DerivedDeep():_m(5){}
int _m;
};
typedef void(*Fun)(void);
int main()
{
Fun pfun;
DerivedDeep d;
int** ptr = (int**)&d;
cout << "1) Derived vptr->vtable:" << endl;
pfun = (Fun)ptr[0][0];
pfun();
pfun = (Fun)ptr[0][1];
pfun();
pfun = (Fun)ptr[0][2];
pfun();
cout << "2) Derived::_z == ";
cout << (int)ptr[1] << endl << endl;
cout << "3) BaseOther vptr->vtable:" << endl;
pfun = (Fun)ptr[2][0];
pfun();
cout << "4) BaseOther::_val == ";
cout << (int)ptr[3] << endl << endl;
cout << "5) DerivedDeep::_m == ";
cout << (int)ptr[4] << endl << endl;
return 0;
}
运行结果:
内存结构图:
可以看出:
1) 每个父类都有自己的虚表。
2) 子类的成员函数被放到了第一个父类的表中。
3) 内存布局中,其父类布局依次按声明顺序排列。(再次说明C++ standard并未明确规定顺序,不同编译器可以有不同的顺序实现,本文代码只在g++和vs2008编译器)
4) 每个父类的虚表中的foo_2()函数都被overwrite成了子类的foo_2()(关系见Derived和Base)。这样做就是为了解决不同的父类类型的指针指向同一个子类实例,而能够调用到实际的函数。
DerivedDeep pdd;
Derived* p_d = &pdd; // 只是简单的拷贝地址就好了,编译器不需要内部转换
BaseOther* p_bo = &pdd ; // 编译器在此处做内部转化 p_bo = ( BaseOther *)((char*)&pdd + sizeof(Derived));
如果是下面的情况:
DerivedDeep* pdd;
BaseOther* p_bo = pdd;
// p_bo = ( BaseOther *)((char*)pdd + sizeof(Derived));这样的转化是不够的,如果pdd为0,则p_bo将获得siezof(Derived)的大小
// 编译器转化的时候会加一个测试条件p_bo = pdd ? ( BaseOther *)((char*)pdd + sizeof(Derived)) : 0;
虚拟继承
Class 如果内含一个或多个virtual base class subobjects,讲被分割成两部分:一个不变区域和一个共享区域。不变区域中的数据,不管后继如何演化,总是拥有固定的offset(从object的开头算起),所以这一部分数据可以直接存取。至于共享区域,所表现的就是virtual base class subobject.这一部分的数据会因为每次的派生操作而有所变化,所以他们只能被间接存取,(各家编译器实现技术差异在间接存取上也表现不同)。
VS编译器采用virtual base class table strategy:使用虚基类表,每一个class object如有一个或多个virtual base classes,就会在编译器中安插一个指针指向virtual base class table,真正的virtual base class 指针放在此表中。
而GCC编译器使用virtual table offset strategy:将直接在派生类对象地址上加上一个常数,获得虚基类实例的地址,多重继承的时候

























 1327
1327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









