






DM8优化之收集统计信息
一、统计信息介绍
达梦数据库的统计数据对象分三种:表统计信息、列统计信息和索引统计信息。统计信
息生成过程分三个步骤:
- 确定采样的对象:根据数据对象,确定需要分析哪些数据。
1) 表:计算表的行数、所占的页数目、平均记录长度。
2) 列:统计列数据的分布特征。
3) 索引:统计索引列的数据分布特征。 - 确定采样率。用户根据统计数据对象的大小,确定采样率。如缺省,则默认通过内
部算法确定数据的采样率。 - 生成统计信息。根据不同的数据对象生成不同的统计信息。
1)表:表的行数、所占的页数目、平均记录长度等汇总数据。
2)列和索引:将采样的数据按照不同的分布特征生成相应的直方图。有两种类型的直
方图:频率直方图和等高直方图。根据算法分析表的数据分布特征(以不同值的数据量 1 万
个为分界线),确定直方图的类型。频率直方图的每个桶(保存统计信息的对象)的高度不
同,等高直方图每个桶的高度相同。生成直方图时,如果不同值少于 1 万个则用频率直方图,否则用等高直方图。
二、统计信息作用
统计信息是优化器的代价计算的依据,可以帮助优化器较精确地估算成本,对执行计划的选择起着至关重要的作用
收集统计信息时机
收集统计信息的时机有两种:一是在查询之前进行静态收集;二是在查询的同时进行动态收集。
静态收集是在查询之前完成。和查询操作互不干涉,因此不影响查询性能。
动态收集是在查询的过程中完成。具体为在构造查询计划阶段进行,统计信息收集完成之后再继续构造计划,因此会影响计划阶段性能,特别是在高并发场景中。从性能角度考虑,推荐用户使用静态收集。
三、手动收集统计信息
3.1收集shema统计信息
DBMS_STATS.GATHER_SCHEMA_STATS(‘DMLOG’, 100,FALSE,‘FOR ALL COLUMNS SIZE AUTO’);-DMLOG是模式名

这种收集方式,并不是100%收集,所以有一定的弊端。
3.2收集表的统计信息
单表收集:
使用DBMS_STATS包中GATHER_TABLE_STATS方法手动收集用户表的统计信息
的完整过程。使用包内的过程和函数之前,如果还未创建过系统包。请先调用系统过程创建系统包。
SP_CREATE_SYSTEM_PACKAGES (1,‘DBMS_STATS’);
SET SERVEROUTPUT ON; //PRINT 需要设置这条语句,才能打印出消息
收集模式 DMLOG下表 EMPLOYEE的统计信息,并打印收集的表信息。
方式一:
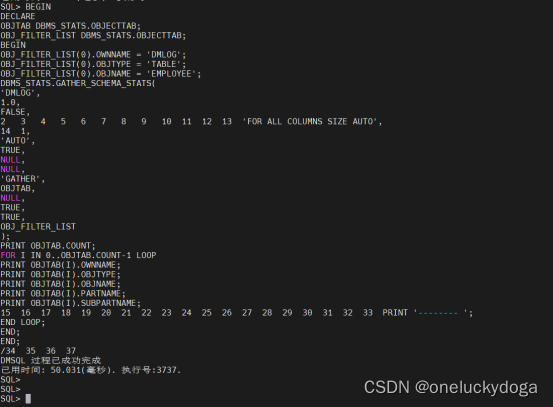
BEGIN
DECLARE
OBJTAB DBMS_STATS.OBJECTTAB;
OBJ_FILTER_LIST DBMS_STATS.OBJECTTAB;
BEGIN
OBJ_FILTER_LIST(0).OWNNAME = ‘DMLOG’;
OBJ_FILTER_LIST(0).OBJTYPE = ‘TABLE’;
OBJ_FILTER_LIST(0).OBJNAME = ‘EMPLOYEE’;
DBMS_STATS.GATHER_SCHEMA_STATS(
‘DMLOG’,
1.0,
FALSE,
‘FOR ALL COLUMNS SIZE AUTO’,
1,
‘AUTO’,
TRUE,
NULL,
NULL,
‘GATHER’,
OBJTAB,
NULL,
TRUE,
TRUE,
OBJ_FILTER_LIST
);
PRINT OBJTAB.COUNT;
FOR I IN 0…OBJTAB.COUNT-1 LOOP
PRINT OBJTAB(I).OWNNAME;
PRINT OBJTAB(I).OBJTYPE;
PRINT OBJTAB(I).OBJNAME;
PRINT OBJTAB(I).PARTNAME;
PRINT OBJTAB(I).SUBPARTNAME;
PRINT '-------- ';
END LOOP;
END;
END;
/
查看表统计信息:
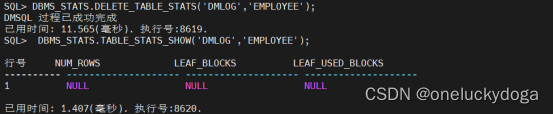
DBMS_STATS.TABLE_STATS_SHOW(‘DMLOG’,‘EMPLOYEE’);

删除表统计信息:
DBMS_STATS.DELETE_TABLE_STATS(‘DMLOG’,‘EMPLOYEE’);
方式二:
使用STAT方式生成统计信息:
语法为:
STAT ON [<模式名>.]<表名> [GLOBAL];
参数
- <模式名> 指定生成统计信息的表的模式。缺省为当前会话的模式名;
- <表名> 指定生成统计信息的表;
- GLOBAL 用于MPP环境下各节点数据收集后统一生成统计信息。
STAT ON DMLOG.EMPLOYEE;
查看统计信息:
DBMS_STATS.TABLE_STATS_SHOW(‘DMLOG’,‘EMPLOYEE’);注意不能使用和列、索引等方式用STAT使用采样率百分比的方式收集。
STAT 30 ON DMLOG.EMPLOYEE;


分区表收集:
创建表并插入数据:
CREATE TABLE DMLOG.PARTITIONED_TABLE (
COLUMN1 VARCHAR2(50),
COLUMN2 NUMBER,
PARTITION_KEY DATE
)
PARTITION BY RANGE (PARTITION_KEY) (
PARTITION part1 VALUES LESS THAN (TO_DATE(‘2022-01-01’, ‘YYYY-MM-DD’)),
PARTITION part2 VALUES LESS THAN (TO_DATE(‘2023-01-01’, ‘YYYY-MM-DD’)),
PARTITION part3 VALUES LESS THAN (MAXVALUE)
);

INSERT INTO DMLOG.PARTITIONED_TABLE (COLUMN1, COLUMN2, PARTITION_KEY)
VALUES (‘Data1’, 100, TO_DATE(‘2021-05-15’, ‘YYYY-MM-DD’));
INSERT INTO DMLOG.PARTITIONED_TABLE (COLUMN1, COLUMN2, PARTITION_KEY)
VALUES (‘Data2’, 200, TO_DATE(‘2022-06-20’, ‘YYYY-MM-DD’));
收集分区表DMLOG.PARTITIONED_TABLE统计信息:
DBMS_STATS.GATHER_TABLE_STATS(‘DMLOG’,‘PARTITIONED_TABLE’,null,100,TRUE,‘FOR COLUMNS PARTITION_KEY SIZE AUTO’,1,‘GLOBAL’);

查看分区表DMLOG.PARTITIONED_TABLE统计信息:
DBMS_STATS.TABLE_STATS_SHOW(‘DMLOG’,‘PARTITIONED_TABLE’);

3.3收集列统计信息
例 对 EMPLOYEE表上 EMPLOYEE_ID 列生成统计信息,采样率的百分比为 30%。使用按新比例
收集的列统计信息覆盖之前老的统计信息。
STAT 30 ON DMLOG.EMPLOYEE (EMPLOYEE_ID);

查询列统计信息:
DBMS_STATS.COLUMN_STATS_SHOW(‘DMLOG’,‘EMPLOYEE’,‘EMPLOYEE_ID’);

3.4收集索引统计信息
例对EMPLOYEE 表上所有的索引生成统计信息。
CALL SP_TAB_INDEX_STAT_INIT (‘DMLOG’, ‘EMPLOYEE’);

例对EMPLOYEE 表上的IDX_SALARY索引生成统计信息。
DBMS_STATS.GATHER_INDEX_STATS(‘DMLOG’,‘IDX_SALARY’);

查询EMPLOYEE 表上的IDX_SALARY索引生成的统计信息
DBMS_STATS.INDEX_STATS_SHOW(‘DMLOG’,‘IDX_SALARY’);

四、自动收集统计信息
在 打 开 INI 监 控 参 数 AUTO_STAT_OBJ ( 为 1 或 2 ) 的 前 提 下 , 可 使 用
SP_CREATE_AUTO_STAT_TRIGGER 过程对表的监控信息进行自动收集。
下面详细介绍使用 SP_CREATE_AUTO_STAT_TRIGGER 过程自动收集用户表的统计
信息的完整过程。
第一步,打开监控。
设置 INI 参数 AUTO_STAT_OBJ 为 1 或 2。1:对所有表进行监控;2:只对用户通过
DBMS_STATS.SET_TABLE_PREFS 设置过 STALE_PERCENT 属性的表对象进行监控。如果
AUTO_STAT_OBJ=2 , 需 进 一 步 使 用 DBMS_STATS.SET_TABLE_PREFS 设 置
STALE_PERCENT 属性。
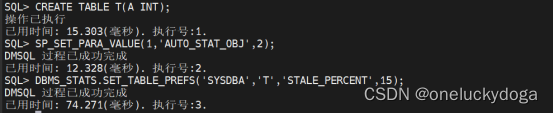
//用 AUTO_STAT_OBJ=1 打开对 T 表的监控。
CREATE TABLE T(A INT);
SP_SET_PARA_VALUE(1,‘AUTO_STAT_OBJ’,1);
//用 AUTO_STAT_OBJ=2 打开对 T 表的监控。
CREATE TABLE T(A INT);
SP_SET_PARA_VALUE(1,‘AUTO_STAT_OBJ’,2);
DBMS_STATS.SET_TABLE_PREFS(‘SYSDBA’,‘T’,‘STALE_PERCENT’,15);//对修改行数占总行数的比达到
STALE_PERCENT 要求的对象和总行数为 0 的对象收集统计信息
下面以 AUTO_STAT_OBJ=2 为例。
第 二 步 , 执 行 统 计 信 息 收 集 操 作 。 自 动 收 集 统 计 信 息 使 用
SP_CREATE_AUTO_STAT_TRIGGER 设置触发器。
SP_CREATE_AUTO_STAT_TRIGGER(1, 1, 1, 1,‘11:20’, ‘2021/1/11’,0,1);

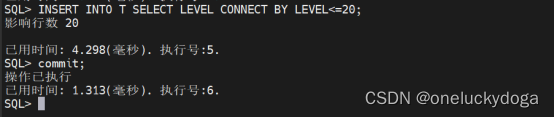
第三步,对用户表 T 进行增删改操作。
INSERT INTO T SELECT LEVEL CONNECT BY LEVEL<=20;
COMMIT;
第四步,通过系统表 SYSSTATTABLEIDU 和动态视图 V
A
U
T
O
S
T
A
T
T
A
B
L
E
I
D
U
查看监控信息,通过系统表
S
Y
S
S
T
A
T
S
查看统计信息。只有打开监控(设置
A
U
T
O
S
T
A
T
O
B
J
为
1
或
2
)后并执行统计信息收集操作之后才能查看到
S
Y
S
S
T
A
T
T
A
B
L
E
I
D
U
和
S
Y
S
S
T
A
T
S
的变化。
S
Y
S
S
T
A
T
T
A
B
L
E
I
D
U
为
A
U
T
O
S
T
A
T
O
B
J
等于
1
或
2
时对上一次的统计信息的监控。
V
AUTO_STAT_TABLE_IDU 查 看监控信息,通过系统表 SYSSTATS 查看统计信息。 只有打开监控(设置 AUTO_STAT_OBJ 为 1 或 2)后并执行统计信息收集操作之后才 能 查 看 到 SYSSTATTABLEIDU 和 SYSSTATS 的 变 化 。 SYSSTATTABLEIDU 为 AUTO_STAT_OBJ等于1或2时对上一次的统计信息的监控。V
AUTOSTATTABLEIDU查看监控信息,通过系统表SYSSTATS查看统计信息。只有打开监控(设置AUTOSTATOBJ为1或2)后并执行统计信息收集操作之后才能查看到SYSSTATTABLEIDU和SYSSTATS的变化。SYSSTATTABLEIDU为AUTOSTATOBJ等于1或2时对上一次的统计信息的监控。VAUTO_STAT_TABLE_IDU
为 AUTO_STAT_OBJ 等于 1 时的统计信息实时监控,不需要执行收集统计信息操作也能查
看。
本例中 AUTO_STAT_OBJ=2。查看监控信息:
//在触发器触发之后查看
SQL> SELECT * FROM SYSSTATTABLEIDU;

查看统计信息:
SELECT * FROM SYSSTATS WHERE ID=1059;
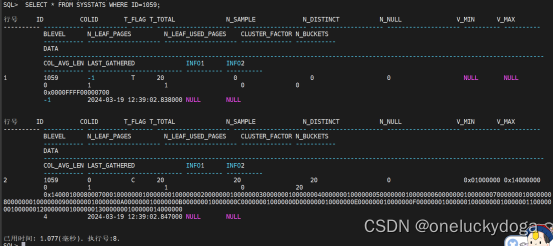
第五步,监控统计信息收集过程。接着上一步的例子,展示监控的完整过程。
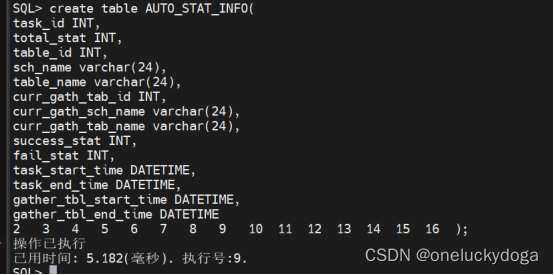
首先,创建一个用户表 AUTO_STAT_INFO,用以保存自动收集过程的相关信息。
create table AUTO_STAT_INFO(
task_id INT,
total_stat INT,
table_id INT,
sch_name varchar(24),
table_name varchar(24),
curr_gath_tab_id INT,
curr_gath_sch_name varchar(24),
curr_gath_tab_name varchar(24),
success_stat INT,
fail_stat INT,
task_start_time DATETIME,
task_end_time DATETIME,
gather_tbl_start_time DATETIME,
gather_tbl_end_time DATETIME
);
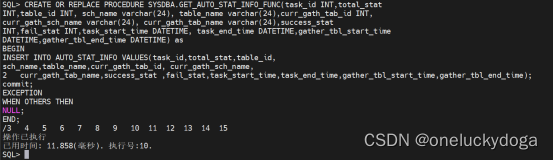
其次,创建过程 SYSDBA.GET_AUTO_STAT_INFO_FUNC,接收服务器在自动收集统
计信息时的过程信息。并在模块体编写用户代码,将过程收集的统计信息写入
AUTO_STAT_INFO 中。
CREATE OR REPLACE PROCEDURE SYSDBA.GET_AUTO_STAT_INFO_FUNC(task_id INT,total_stat
INT,table_id INT, sch_name varchar(24), table_name varchar(24),curr_gath_tab_id INT,
curr_gath_sch_name varchar(24), curr_gath_tab_name varchar(24),success_stat
INT,fail_stat INT,task_start_time DATETIME, task_end_time DATETIME,gather_tbl_start_time
DATETIME,gather_tbl_end_time DATETIME) as
BEGIN
INSERT INTO AUTO_STAT_INFO VALUES(task_id,total_stat,table_id,
sch_name,table_name,curr_gath_tab_id, curr_gath_sch_name,
curr_gath_tab_name,success_stat ,fail_stat,task_start_time,task_end_time,gather_tbl_start_time,gather_tbl_end_time);
commit;
EXCEPTION
WHEN OTHERS THEN
NULL;
END;
/
最后,解读表 AUTO_STAT_INFO,介绍一次自动收集统计信息任务的相关过程信息。
如果 SP_CREATE_AUTO_STAT_TRIGGER 触发一次自动收集统计信息,在任务开始时,
会先记录当前任务的开始时间,当前任务的待收集表的总个数,以及接下来待收集的表的id。
之后每收集完成一个表的统计信息,就会记录该表 table 的 id 及收集该表的开始和结束时
间,和截至目前收集成功失败的表个数情况,以及接下来待收集的表的 id。其中“接下来待
收集的表的 id”即 current_gather_tab_id,为当前服务器正在收集的表 id。
五、收集统计信息前后对比
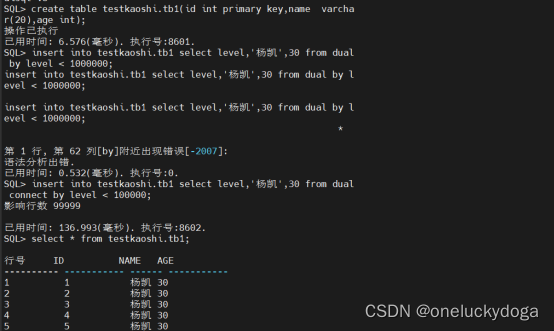
测试数据准备
create table testkaoshi.tb1(id int primary key,name varcha r(20),age int);
insert into testkaoshi.tb1 select level,‘杨凯’,30 from dual connect by level < 100000;
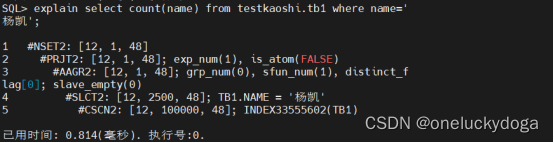
创建索引
create index index_name on tb1(name);

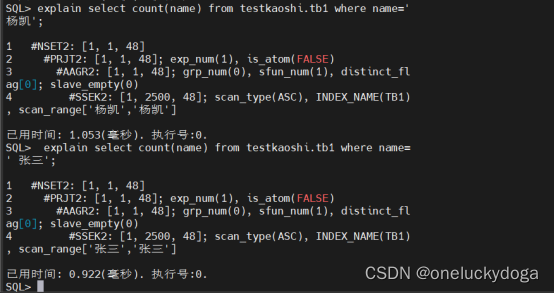
结论:未收集统计信息之前,当name=‘杨凯’,是走二级索引扫描的,说明执行计划是错误的。 因为当查询结果返回的是超过表中5%的数据时,应该走全表扫描。
收集统计信息之前:

收集统计信息之后:

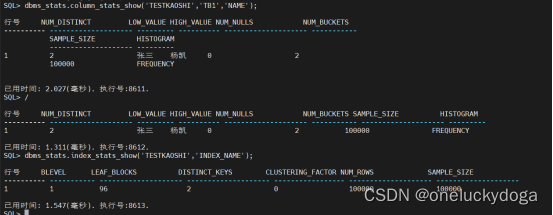
结论:当收集表统计信息时,列和索引的统计信息也自动收集。
再次查询:
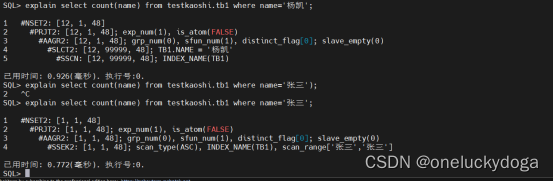
结论:
这次执行计划是完全正确的,符合CBO优化器的规则,
当name=‘杨凯’,走全表扫描;
当name=‘张三’,走二级索引扫描。
有任何疑问请访问达梦官方网站:https://eco.dameng.com














 2065
2065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









