







1,概述
“ group by ” ,从字面意义理解,就是根据“BY” 指定规则进行分组,分组就是将一个 “数据集”划分成若干个“小区域”,针对这个若干“”小区域”进行处理。
Having短语与WHERE的区别!!!
WHERE子句作用于基表或视图,从中选择满足条件的元组。HAVING短语作用于组,从中选择满足条件的组。
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
8、Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
插入数据:
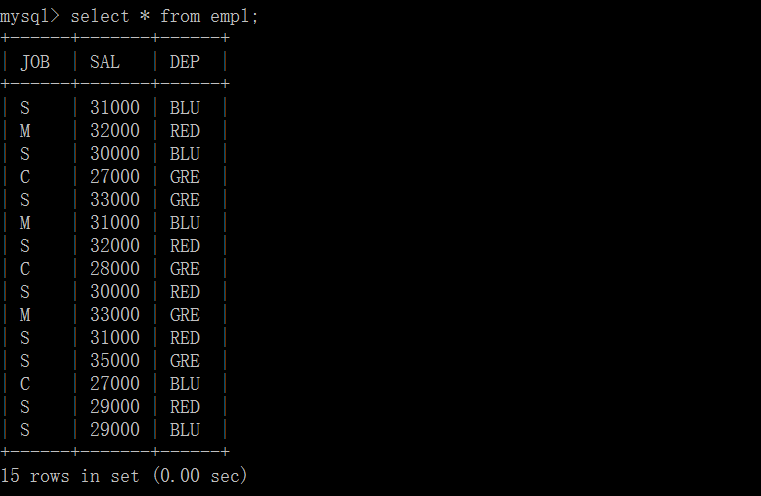
需求:从该表中筛选出工种不是“M” ,以部门来划分平均工资大于28000,按降序排列的记录。
代码:
去重sql语句
select user_name,count(*) as count from user_table group by user_name having count>1;














 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









