






1. 网站点击流数据分析项目业务背景
1.1 什么是点击流数据
1.1.1 WEB访问日志
即指用户访问网站时的所有访问、浏览、点击行为数据。比如点击了哪一个链接,在哪个网页停留时间最多,采用了哪个搜索项、总体浏览时间等。而所有这些信息都可被保存在网站日志中。通过分析这些数据,可以获知许多对网站运营至关重要的信息。采集的数据越全面,分析就能越精准。 日志的生成渠道: 1)是网站的web服务器所记录的web访问日志; 2)是通过在页面嵌入自定义的js代码来获取用户的所有访问行为(比如鼠标悬停的位置,点击的页面组件等),然后通过ajax请求到后台记录日志;这种方式所能采集的信息最全面; 3)通过在页面上埋点1像素的图片,将相关页面访问信息请求到后台记录日志; 日志数据内容详述: 在实际操作中,有以下几个方面的数据可以被采集: 1) 访客的系统属性特征。比如所采用的操作系统、浏览器、域名和访问速度等。 2) 访问特征。包括停留时间、点击的URL等。 3) 来源特征。包括网络内容信息类型、内容分类和来访URL等。 4) 产品特征。包括所访问的产品编号、产品类别、产品颜色、产品价格、产品利润、产品数量和特价等级等。
其点击日志格式如下:
GET /log.gif?t=item.010001&m=UA-J2011-1&pin=-&uid=1679790178&sid=1679790178|12&v=je=1$sc=24-bit$sr=1600x900$ul=zh-cn$cs=GBK$dt=【云南白药套装】云南白药 牙膏 180g×3 (留兰香型)【行情 报价 价格 评测】-京东$hn=item.jd.com$fl=16.0 r0$os=win$br=chrome$bv=39.0.2171.95$wb=1437269412$xb=1449548587$yb=1456186252$zb=12$cb=4$usc=direct$ucp=-$umd=none$uct=-$ct=1456186505411$lt=0$tad=-$sku=1326523$cid1=1316$cid2=1384$cid3=1405$brand=20583$pinid=-&ref=&rm=1456186505411 HTTP/1.1
1
2
1.1.2 点击流数据模型
点击流概念
点击流这个概念更注重用户浏览网站的整个流程,网站日志中记录的用户点击就像是图上的“点”,而点击流更像是将这些“点”串起来形成的“线”。也可以把“点”认为是网站的Page,而“线”则是访问网站的Session。所以点击流数据是由网站日志中整理得到的,它可以比网站日志包含更多的信息,从而使基于点击流数据统计得到的结果更加丰富和高效。

点击流模型生成
点击流数据在具体操作上是由散点状的点击日志数据梳理所得,从而,点击数据在数据建模时应该存在两张模型表(Pageviews和visits): 1、用于生成点击流的访问日志表(源数据) 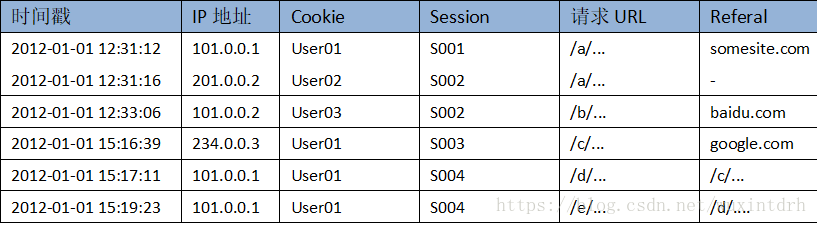 2、页面点击流模型Pageviews表(按session聚集的访问页面信息)(每个session中的每个url也即是访问页面,的记录信息, 想差半个小时了就认为是下一个session了)  3、点击流模型Visits表 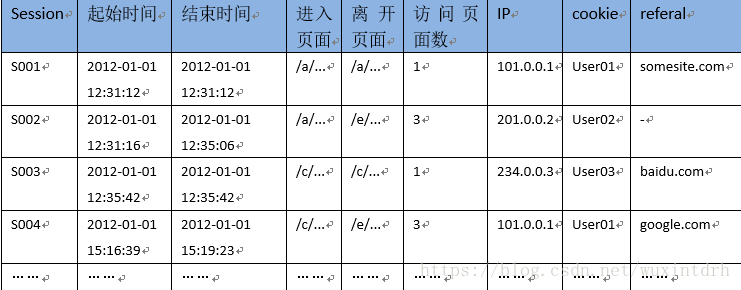
这就是点击流模型。当WEB日志转化成点击流数据的时候,很多网站分析度量的计算变得简单了,这就是点击流的“魔力”所在。基于点击流数据我们可以统计出许多常见的网站分析度量
2 整体技术流程及架构
2.1 数据处理流程
该项目是一个纯粹的数据分析项目,其整体流程基本上就是依据数据的处理流程进行,依此有以下几个大的步骤:
1) 数据采集
首先,通过页面嵌入JS代码的方式获取用户访问行为,并发送到web服务的后台记录日志
然后,将各服务器上生成的点击流日志通过实时或批量的方式汇聚到HDFS文件系统中
当然,一个综合分析系统,数据源可能不仅包含点击流数据,还有数据库中的业务数据(如用户信息、商品信息、订单信息等)及对分析有益的外部数据。
2) 数据预处理
通过spark程序对采集到的点击流数据进行预处理,比如清洗,格式整理,滤除脏数据等
3) 数据入库
将预处理之后的数据导入到HIVE仓库中相应的库和表中
4) 数据分析
项目的核心内容,即根据需求开发ETL分析语句,得出各种统计结果
5) 数据展现
将分析所得数据进行可视化
2.2 项目结构
由于本项目是一个纯粹数据分析项目,其整体结构亦跟分析流程匹配,并没有特别复杂的结构,如下图:
其中,需要强调的是:
系统的数据分析不是一次性的,而是按照一定的时间频率反复计算,因而整个处理链条中的各个环节需要按照一定的先后依赖关系紧密衔接,即涉及到大量任务单元的管理调度,所以,项目中需要添加一个任务调度模块
2.3 数据展现
数据展现的目的是将分析所得的数据进行可视化,以便运营决策人员能更方便地获取数据,更快更简单地理解数据
3 模块开发——数据采集
3.1 需求
数据采集的需求广义上来说分为两大部分。
1)是在页面采集用户的访问行为,具体开发工作:
1、开发页面埋点js,采集用户访问行为
2、后台接受页面js请求记录日志
此部分工作也可以归属为“数据源”,其开发工作通常由web开发团队负责
2)是从web服务器上汇聚日志到HDFS,是数据分析系统的数据采集,此部分工作由数据分析平台建设团队负责,具体的技术实现有很多方式:
Shell脚本
优点:轻量级,开发简单
缺点:对日志采集过程中的容错处理不便控制
Java采集程序
优点:可对采集过程实现精细控制
缺点:开发工作量大
Flume日志采集框架
成熟的开源日志采集系统,且本身就是hadoop生态体系中的一员,与hadoop体系中的各种框架组件具有天生的亲和力,可扩展性强
3.2 技术选型
在点击流日志分析这种场景中,对数据采集部分的可靠性、容错能力要求通常不会非常严苛,因此使用通用的flume日志采集框架完全可以满足需求。
本项目即使用flume来实现日志采集。
3.3 Flume日志采集系统搭建
1、数据源信息
本项目分析的数据用nginx服务器所生成的流量日志,存放在各台nginx服务器上,如:
/var/log/httpd/access_log.2015-11-10-13-00.log
/var/log/httpd/access_log.2015-11-10-14-00.log
/var/log/httpd/access_log.2015-11-10-15-00.log
/var/log/httpd/access_log.2015-11-10-16-00.log
1
2
3
4
5
2、数据内容样例
数据的具体内容在采集阶段其实不用太关心。
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0"
字段解析:
1、访客ip地址: 58.215.204.118
2、访客用户信息: - -
3、请求时间:[18/Sep/2013:06:51:35 +0000]
4、请求方式:GET
5、请求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2
6、请求所用协议:HTTP/1.1
7、响应码:304
8、返回的数据流量:0
9、访客的来源url:http://blog.fens.me/nodejs-socketio-chat/
10、访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
3、日志文件生成规律
基本规律为:
当前正在写的文件为access_log;
文件体积达到256M,或时间间隔达到60分钟,即滚动重命名切换成历史日志文件;
形如: access_log.2015-11-10-13-00.log
当然,每个公司的web服务器日志策略不同,可在web程序的log4j.properties中定义,如下:
log4j.appender.logDailyFile = org.apache.log4j.DailyRollingFileAppender
log4j.appender.logDailyFile.layout = org.apache.log4j.PatternLayout
log4j.appender.logDailyFile.layout.ConversionPattern = [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.logDailyFile.Threshold = DEBUG
log4j.appender.logDailyFile.ImmediateFlush = TRUE
log4j.appender.logDailyFile.Append = TRUE
log4j.appender.logDailyFile.File = /var/logs/access_log
log4j.appender.logDailyFile.DatePattern = '.'yyyy-MM-dd-HH-mm'.log'
log4j.appender.logDailyFile.Encoding = UTF-8
1
2
3
4
5
6
7
8
9
10
4、Flume采集实现
Flume采集系统的搭建相对简单:
1、在个web服务器上部署agent节点,修改配置文件
2、启动agent节点,将采集到的数据汇聚到指定的HDFS目录中
如下图:
版本选择:apache-flume-1.6.0
采集规则设计:
1、 采集源:nginx服务器日志目录
2、 存放地:hdfs目录/home/hadoop/weblogs/
采集规则配置详情
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure spooldir source1
#agent1.sources.source1.type = spooldir
#agent1.sources.source1.spoolDir = /var/logs/nginx/
#agent1.sources.source1.fileHeader = false
# Describe/configure tail -F source1
#使用exec作为数据源source组件
agent1.sources.source1.type = exec
#使用tail -F命令实时收集新产生的日志数据
agent1.sources.source1.command = tail -F /var/logs/nginx/access_log
agent1.sources.source1.channels = channel1
#configure host for source
#配置一个拦截器插件
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
#使用拦截器插件获取agent所在服务器的主机名
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#配置sink组件为hdfs
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
#agent1.sinks.sink1.hdfs.path=hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H%M%S
#指定文件sink到hdfs上的路径
agent1.sinks.sink1.hdfs.path=
hdfs://hdp-node-01:9000/weblog/flume-collection/%y-%m-%d/%H-%M_%hostname
#指定文件名前缀
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
#指定每批下沉数据的记录条数
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
#指定下沉文件按1G大小滚动
agent1.sinks.sink1.hdfs.rollSize = 1024*1024*1024
#指定下沉文件按1000000条数滚动
agent1.sinks.sink1.hdfs.rollCount = 1000000
#指定下沉文件按30分钟滚动
agent1.sinks.sink1.hdfs.rollInterval = 30
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
#使用memory类型channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
启动采集
在部署了flume的nginx服务器上,启动flume的agent,命令如下:
bin/flume-ng agent –conf ./conf -f ./conf/weblog.properties.2 -n agent
注意:启动命令中的 -n 参数要给配置文件中配置的agent名称
4 模块开发——数据预处理
4.1 主要目的:
过滤“不合规”数据
格式转换和规整
根据后续的统计需求,过滤分离出各种不同主题(不同栏目path)的基础数据
4.2 实现方式:
对源数据进行预处理
源表
drop table if exists ods_weblog_origin;
create table ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
4.3 点击流模型数据梳理
由于大量的指标统计从点击流模型中更容易得出,所以在预处理阶段,可以使用mr程序来生成点击流模型的数据
4.3.1 点击流模型pageviews表
点击流模型pageviews表 ods_click_pageviews
drop table if exists ods_click_pageviews;
create table ods_click_pageviews(
Session string,
remote_addr string,
remote_user string,
time_local string,
request string,
visit_step string,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
4.3.2 点击流模型visit信息表
注:“一次访问”=“N次连续请求”
直接从原始数据中用hql语法得出每个人的“次”访问信息比较困难,可先用mapreduce程序分析原始数据得出“次”信息数据,然后再用hql进行更多维度统计
用spark程序从pageviews数据中,梳理出每一次visit的起止时间、页面信息
然后,在hive仓库中建点击流visit模型表
drop table if exist click_stream_visit;
create table click_stream_visit(
session string,
remote_addr string,
inTime string,
outTime string,
inPage string,
outPage string,
referal string,
pageVisits int)
partitioned by (datestr string);
1
2
3
4
5
6
7
8
9
10
11
12
然后,将运算得到的visit数据导入visit模型表
load data local inpath '/uardata/hivetest/weblog/visit.log' into table ods_click_visit partition(datestr='2013-03-18');
1
2
5 模块开发——数据仓库设计
注:采用星型模型
5.1 事实表
5.2 维度表
6 模块开发——ETL
该项目的数据分析过程在hadoop集群上实现,主要应用hive数据仓库工具,因此,采集并经过预处理后的数据,需要加载到hive数据仓库中,以进行后续的挖掘分析。
在hive仓库中建贴源数据表 ods_weblog_origin
点击流模型pageviews表 ods_click_pageviews
点击流visit模型表 click_stream_visit
时间维表创建
drop table dim_time if exists ods_click_pageviews;
create table dim_time(
year string,
month string,
day string,
hour string)
row format delimited
fields terminated by ',';
1
2
3
4
5
6
7
8
9
6.2导入数据
导入清洗结果数据到贴源数据表ods_weblog_origin
load data inpath '/weblog/preprocessed/16-02-24-16/' overwrite into table ods_weblog_origin partition(datestr='2013-09-18');
导入点击流模型pageviews数据到ods_click_pageviews表
load data inpath '/weblog/clickstream/pageviews' overwrite into table ods_click_pageviews partition(datestr='2013-09-18');
导入点击流模型visit数据到click_stream_visit表
Load data local inpath '/weblog/clickstream/visits' overwrite into table click_stream_visit partition(datestr='2013-09-18');
1
2
3
4
5
6
7
8
9
10
11
6.3 生成ODS层明细宽表
6.3.1 需求概述
整个数据分析的过程是按照数据仓库的层次分层进行的,总体来说,是从ODS原始数据中整理出一些中间表(比如,为后续分析方便,将原始数据中的时间、url等非结构化数据作结构化抽取,将各种字段信息进行细化,形成明细表),然后再在中间表的基础之上统计出各种指标数据
6.3.2 ETL实现
建表——明细表ods_weblog_detail (源:ods_weblog_origin) (目标:ods_weblog_detail)
#etl明细宽表
drop table ods_weblog_detail;
create table ods_weblog_detail(
valid string, --有效标识
remote_addr string, --来源IP
remote_user string, --用户标识
time_local string, --访问完整时间
daystr string, --访问日期
timestr string, --访问时间
month string, --访问月
day string, --访问日
hour string, --访问时
request string, --请求的url
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源url
ref_host string, --来源的host
ref_path string, --来源的路径
ref_query string, --来源参数query
ref_query_id string, --来源参数query的值
http_user_agent string --客户终端标识
)
partitioned by(datestr string);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
抽取refer_url到中间表 “t_ods_tmp_referurl”
将来访url分离出host path query query id
drop table if exists t_ods_tmp_referurl;
create table t_ods_tmp_referurl as
SELECT a.*,b.*
FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as host, path, query, query_id;
1
2
3
4
5
抽取转换time_local字段到中间表明细表 ”t_ ods _detail”
drop table if exists t_ods_tmp_detail;
create table t_ods_tmp_detail as
select b.*,substring(time_local,0,10) as daystr,
substring(time_local,11) as tmstr,
substring(time_local,6,2) as month,
substring(time_local,9,2) as day,
substring(time_local,12,2) as hour
From t_ods_tmp_referurl b;
1
2
3
4
5
6
7
8
9
以上语句可以改写成:
insert into table ods_weblog_detail partition(datestr='2013-09-18')
select c.valid,c.remote_addr,c.remote_user,c.time_local,
substring(c.time_local,0,10) as daystr,
substring(c.time_local,12) as tmstr,
substring(c.time_local,6,2) as month,
substring(c.time_local,9,2) as day,
substring(c.time_local,11,3) as hour,
c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent
from
(SELECT
a.valid,a.remote_addr,a.remote_user,a.time_local,
a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent,b.ref_host,b.ref_path,b.ref_query,b.ref_query_id
FROM ods_weblog_origin a LATERAL VIEW parse_url_tuple(regexp_replace(http_referer, "\"", ""), 'HOST', 'PATH','QUERY', 'QUERY:id') b as ref_host, ref_path, ref_query, ref_query_id) c;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









