









索引到底是什么?
alter table user add index idx_name (name); 在字段上创建索引数据库索引是数据库管理系统中一个排序的数据结构,以协助快速查询,更新数据表中的数据。数据是以文件的形式存放在磁盘上的。
索引类型:
Normal普通索引:
unique唯一索引:比普通索引多一种约束:唯一
主键索引:比唯一索引多一种约束,不能用空值
Full Text全文索引:使用 where name like %北京%;匹配用不到索引,此时使用全文索引。
索引方法:
HASH,BTREE,B+TREE,
数据模型:(存储索引的数据模型)
有序数组:查询快,修改慢
单链表:修改快,查询慢。
二叉查找树:当插入的数据索引是递增的,就变成了单链表结构。
平衡的二叉查找树:左右子树深度差绝对值不能超过1.
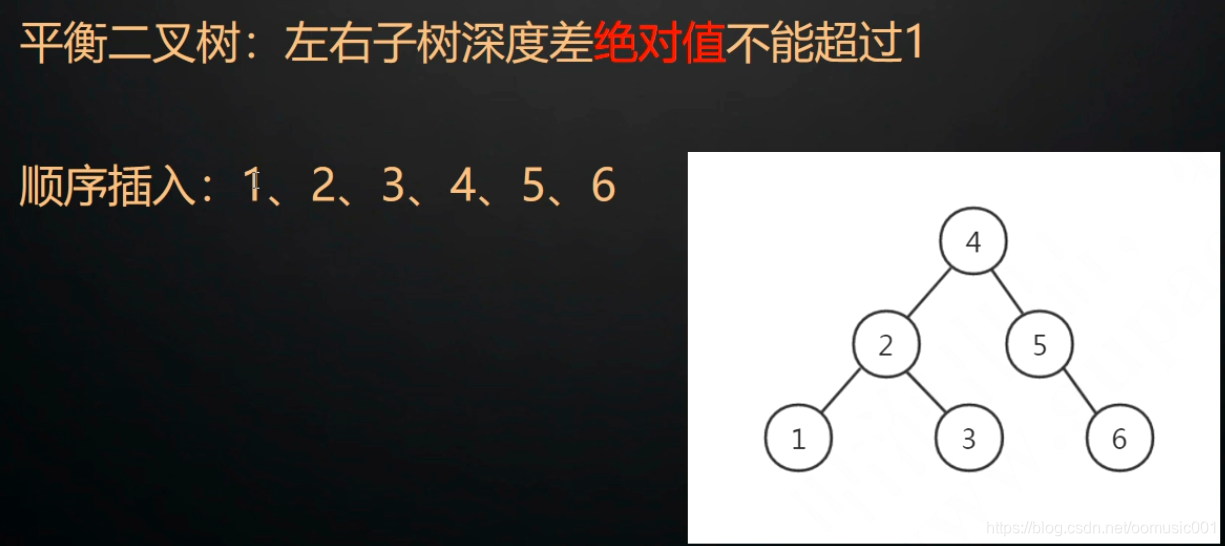
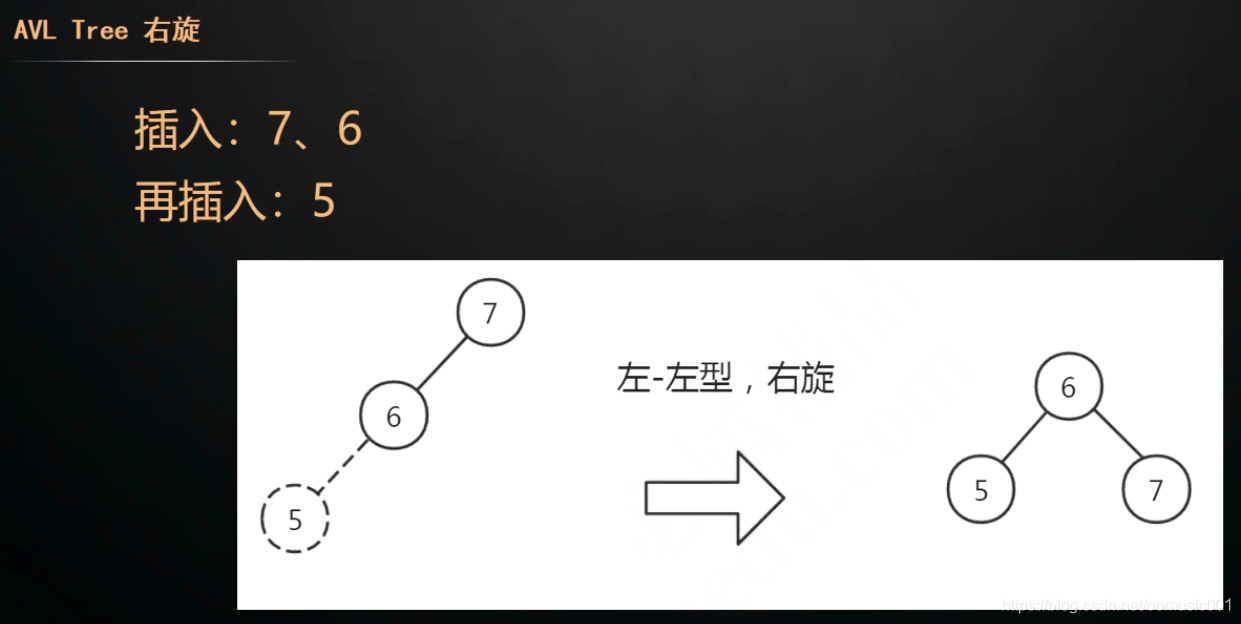
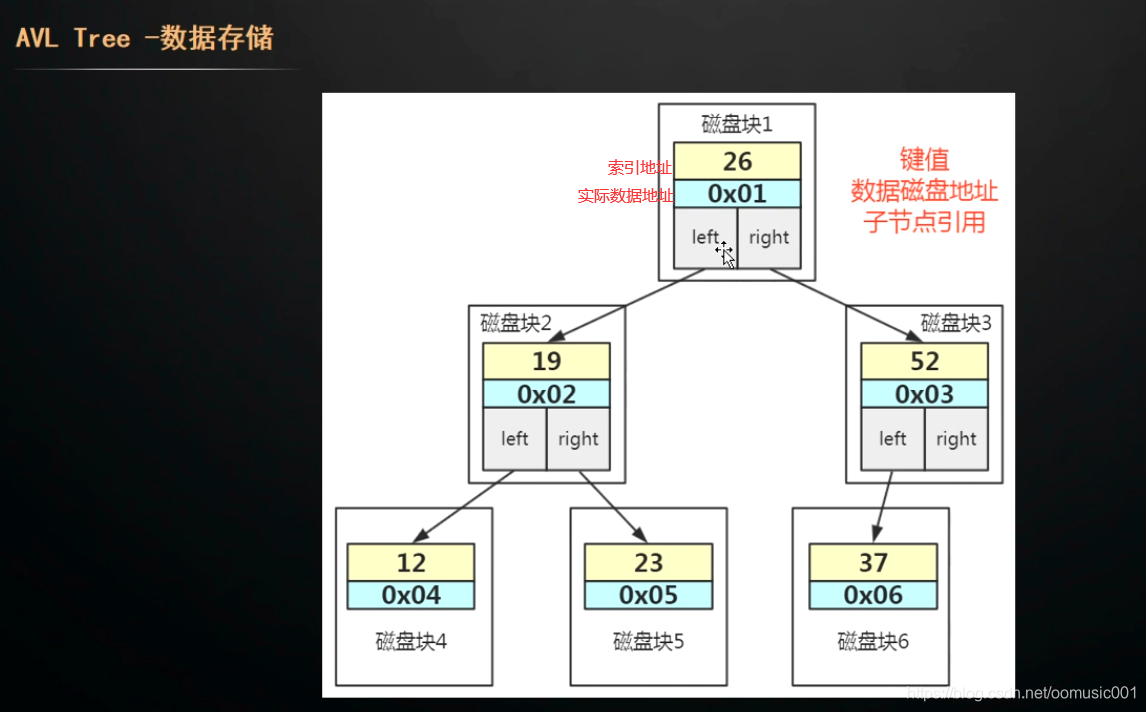
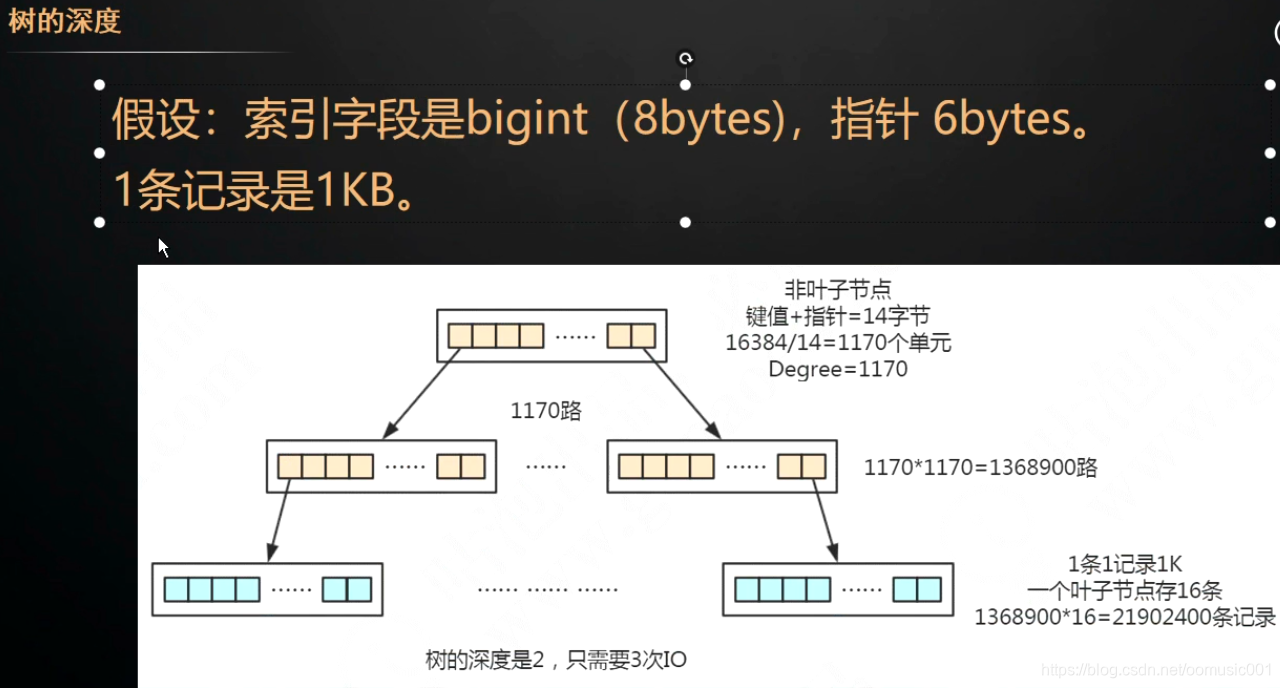
平衡树存在的问题:索引是存储在磁盘上的。当进行查询时,会从磁盘拿到数据块到内存,如果不存在,就再次从磁盘拿数据库到内存。在InnoDB中把磁盘数据加载到内存最新的逻辑单位是页:16kb。当把一个数据节点设计为16kb,但实际存的只有索引地址,实际数据地址,左右节点地址,大小远小于16kb,造成了空间的浪费,而且InnoDB一次只读取一页16kb到内存,这样查询一个数据和磁盘的交互大大增加。如查询id=28的数据,16-->52-->37.需要三次io。即6条数据就需要3次io。几百万条数据则无法想象。如果把节点大小缩小,也会存在树过深的问题。
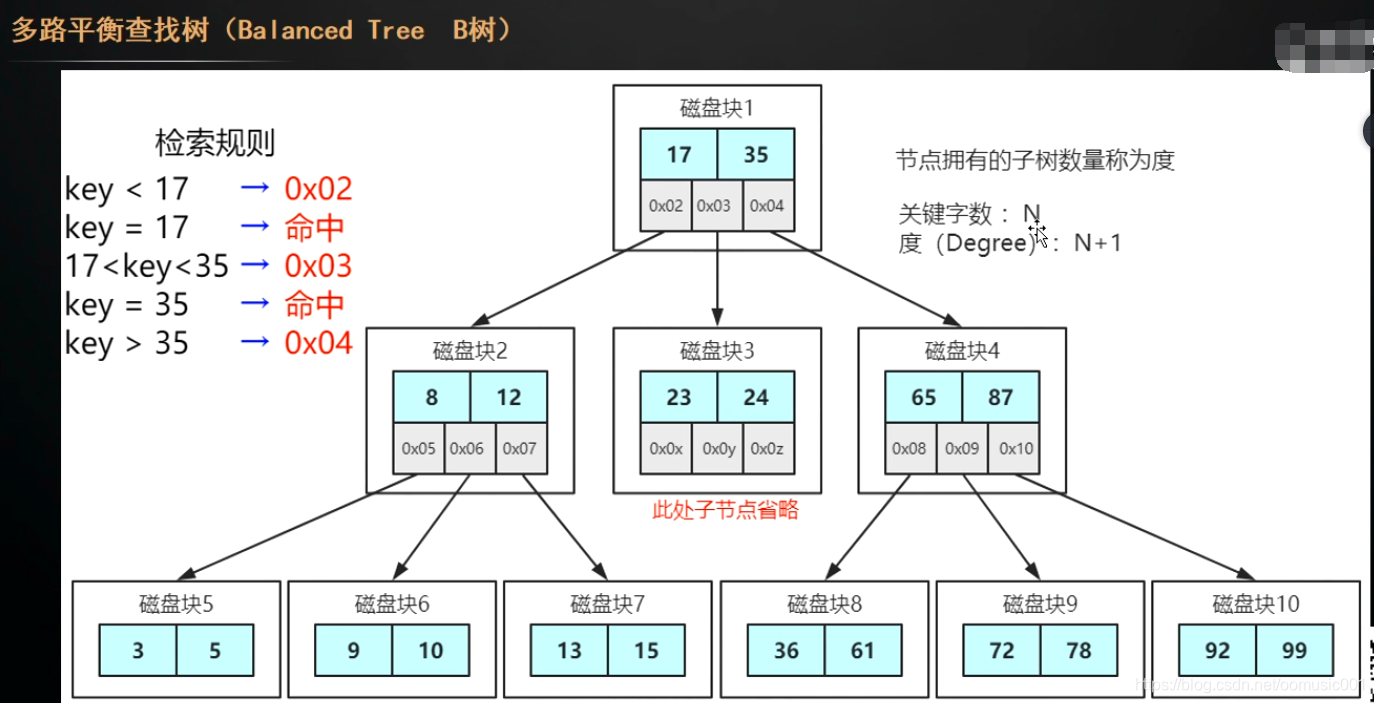
解决办法:将每一个节点存储更多的数据。或增加更多的指针。--->多路平衡查找树:
多路平衡查找树(B树):
B+树:
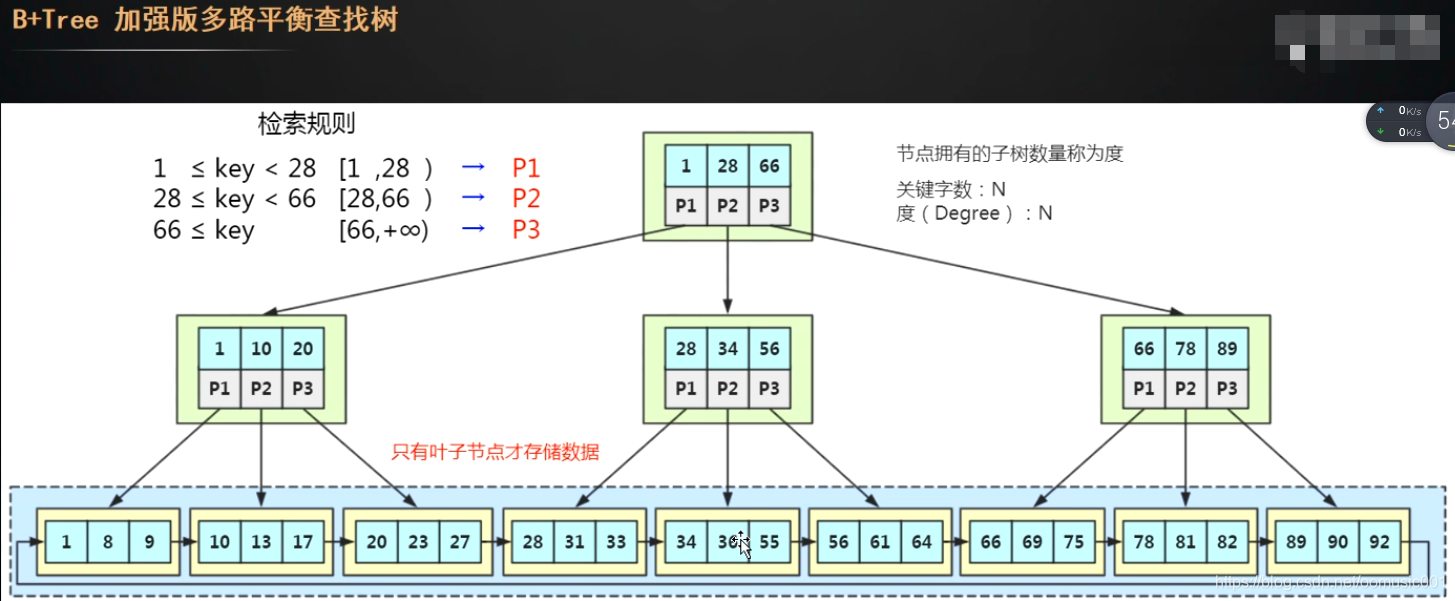
B+树特点:无论查询哪一条数据,经过的io次数都一样,因为数据都是存在叶子节点。
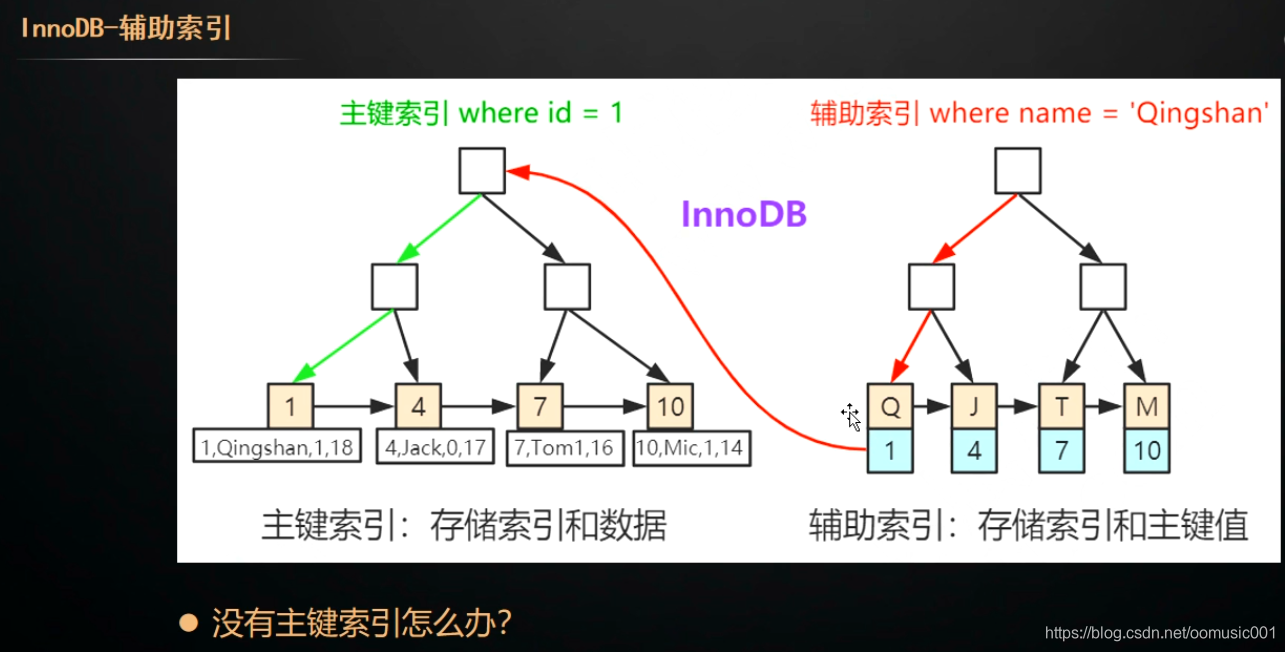
MyISAM的主键索引和辅助索引,都是通过从索引的页子节点找到数据的地址,通过地址获取数据。
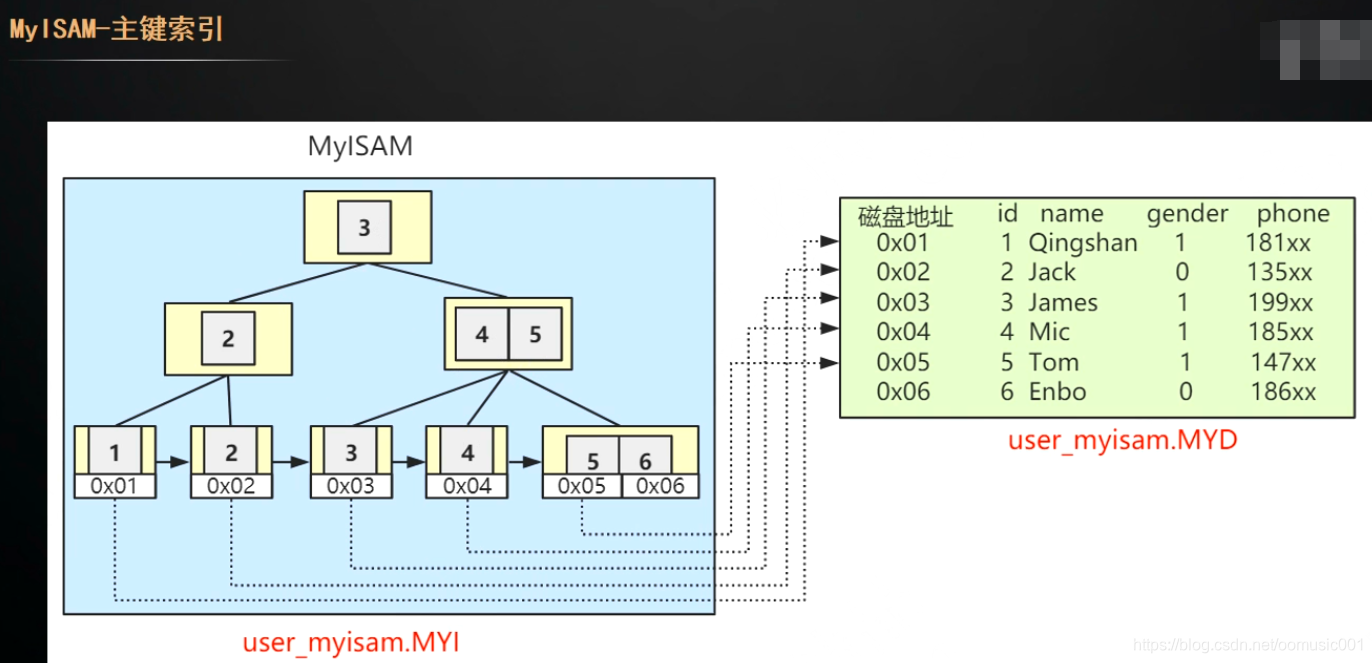
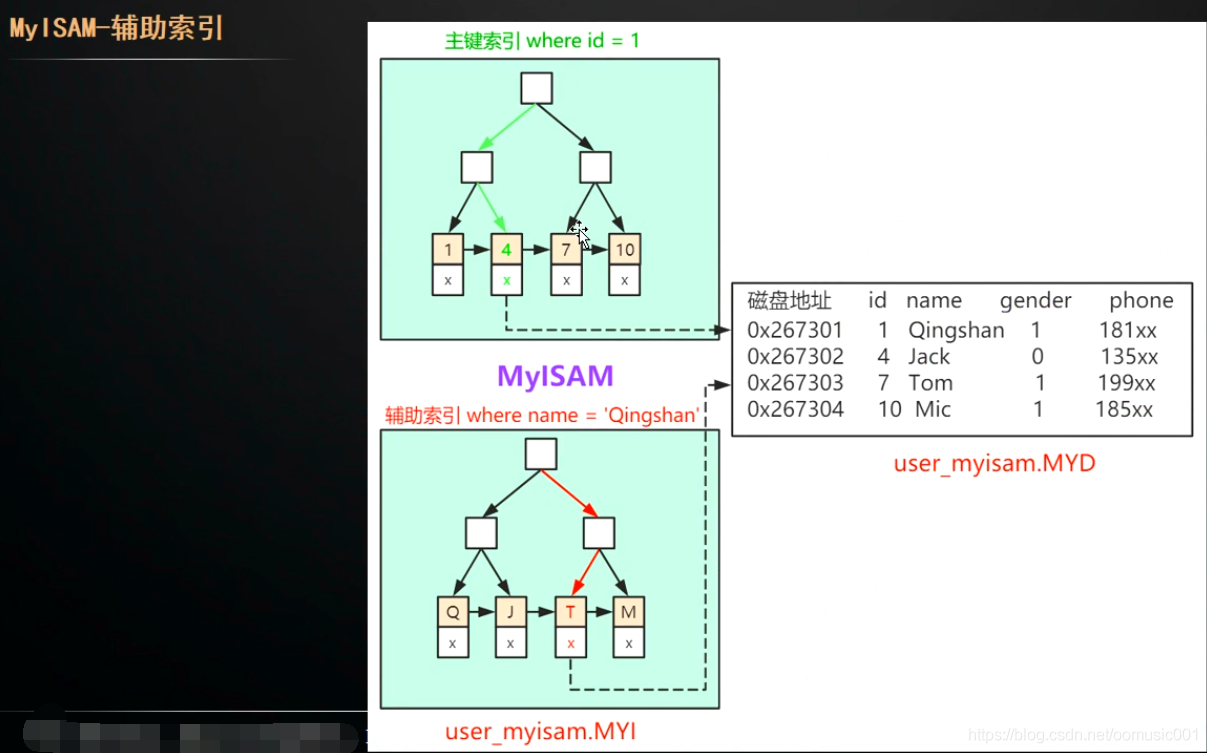
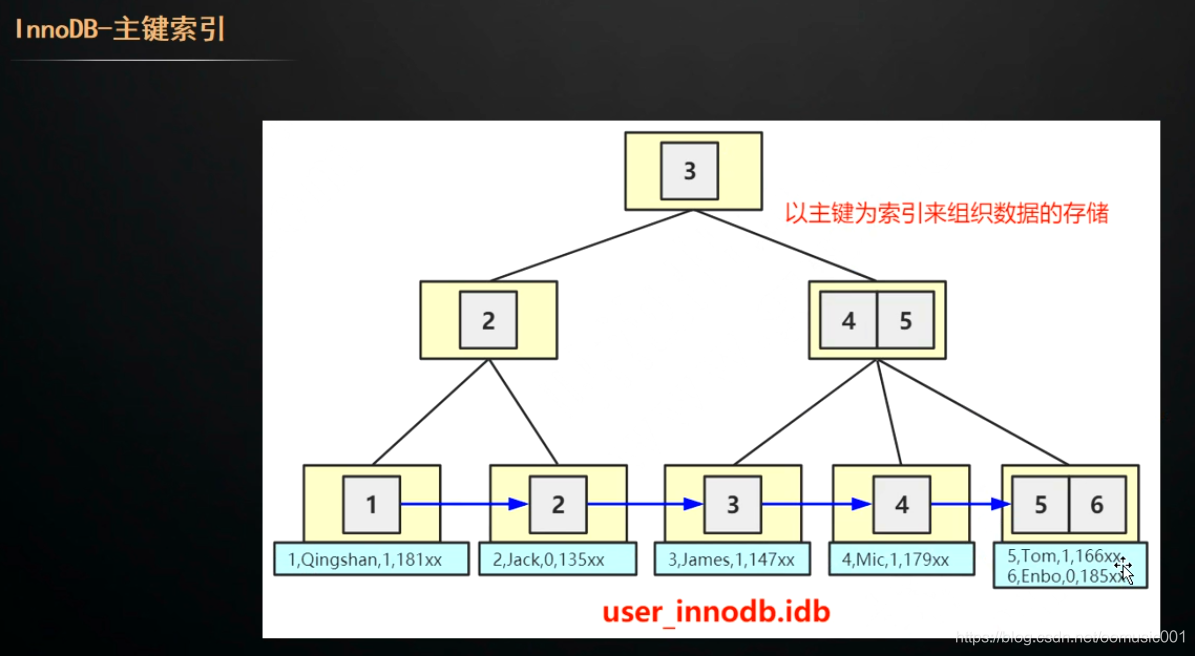
在InnoDB中 主键索引==聚集索引
没有索引:隐藏的有一个列 "_rowid" 作为索引
没有主键索引,有unique key:找到第一个没有null的普通索引作为聚集索引决定数据存放的位置
没有主键索引,也没有非空唯一索引:
InnoDB的主键索引是直接通过索引找到页子节点上的数据。
InnoDB是通过辅助索引找到页子节点上的主键索引,再通过主键索引找到主键索引页子节点上的数据
为什么MySql选择B+Tree?
存储引擎中索引如何落地?
MySql索引使用原则:
第一个原则:
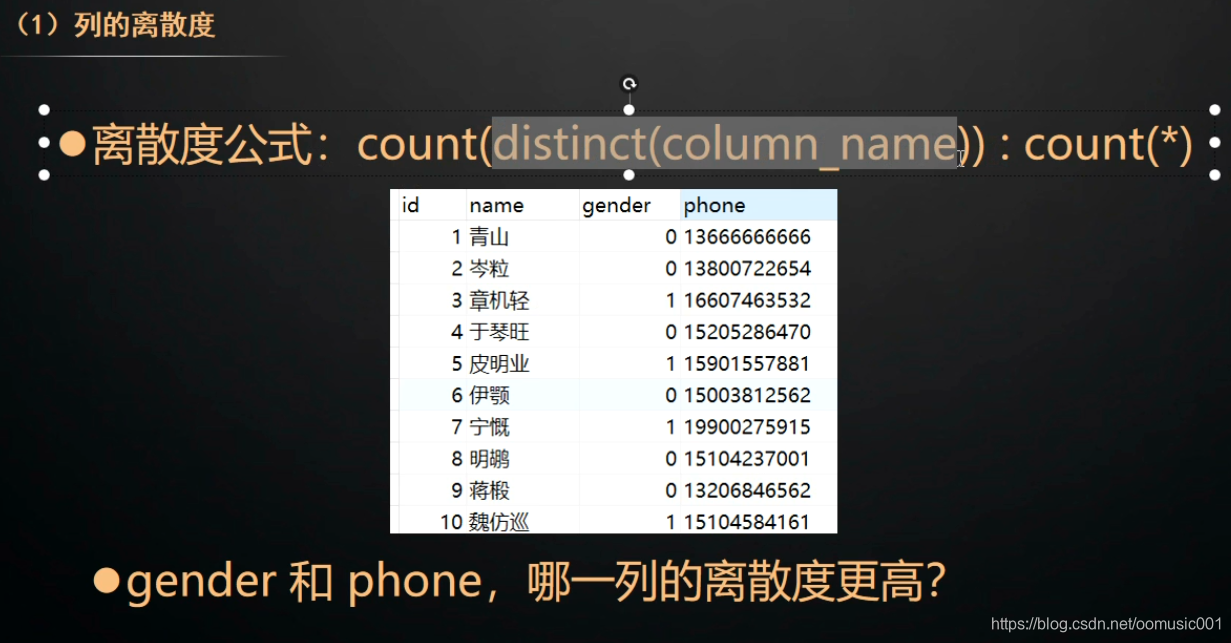
离散度越高,越适合做索引。
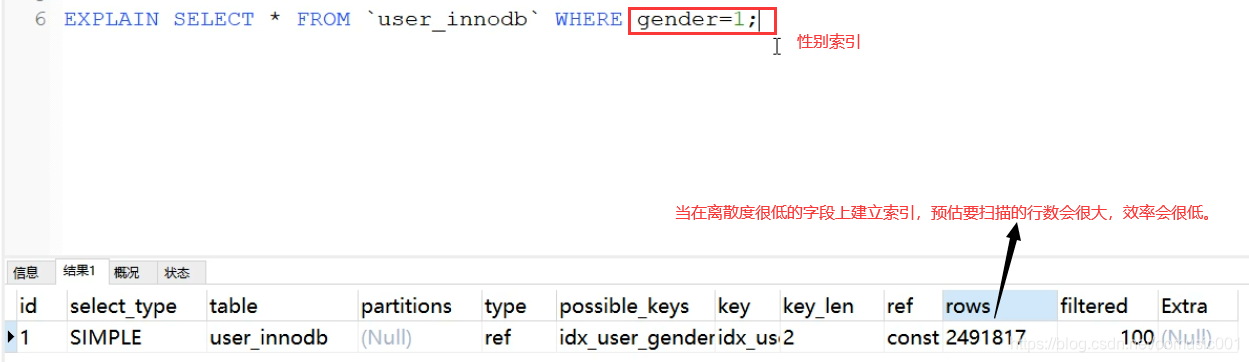
离散度低的索引,当用该索引进行查询时,扫描的行数会很高。
性别索引:
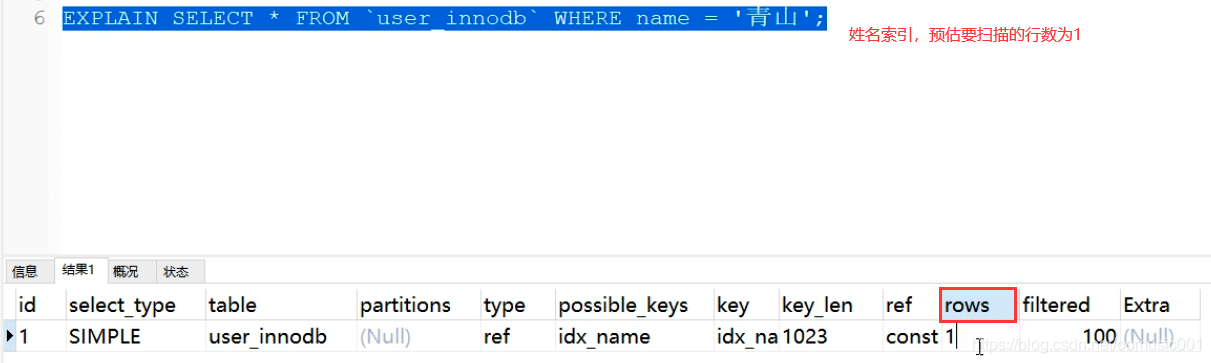
姓名索引:
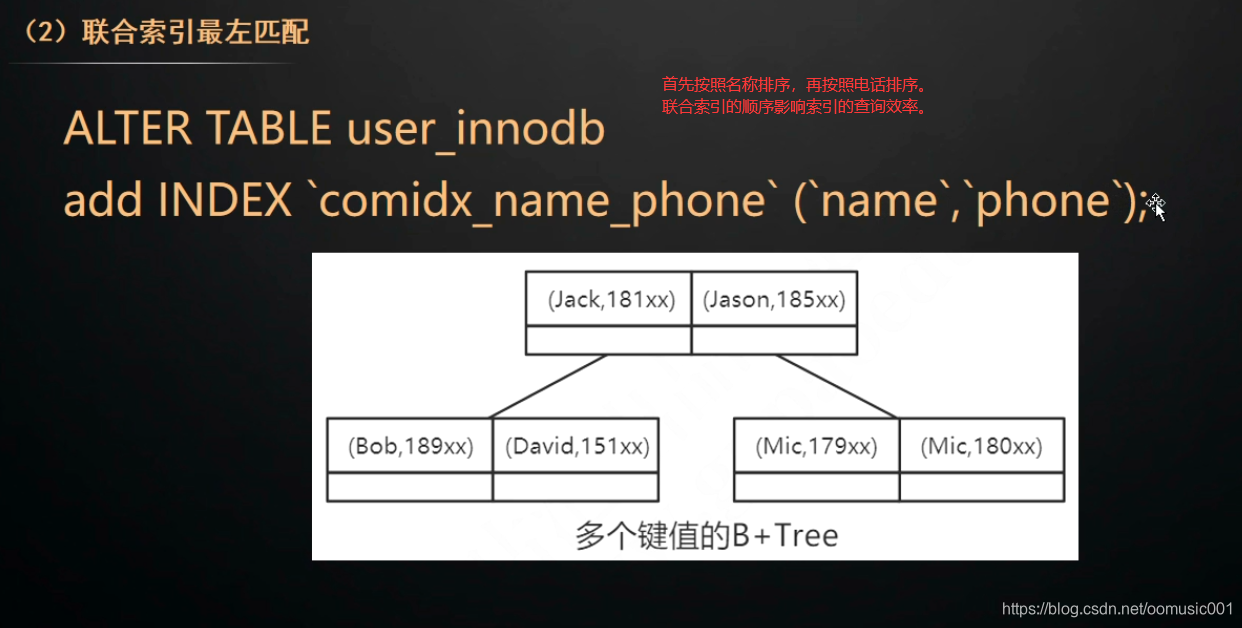
第二个原则:
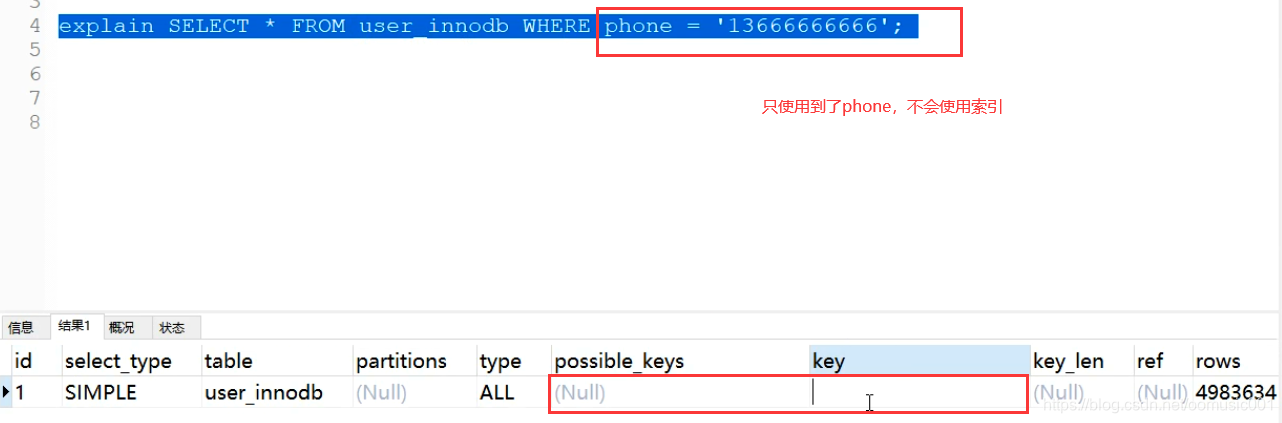
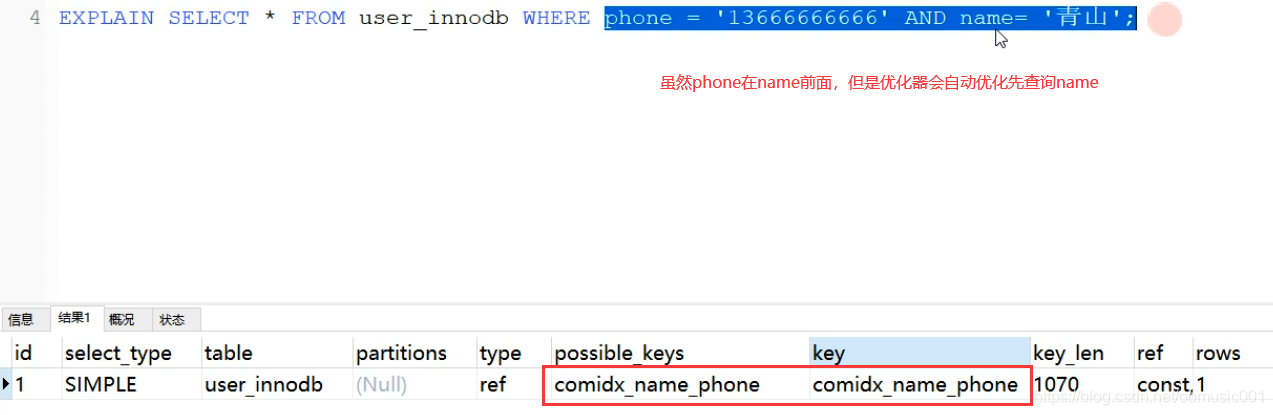

回表:当使用辅助索引查询数据的时候,因为叶子节点没有完整数据,需要多扫描一颗b+树。
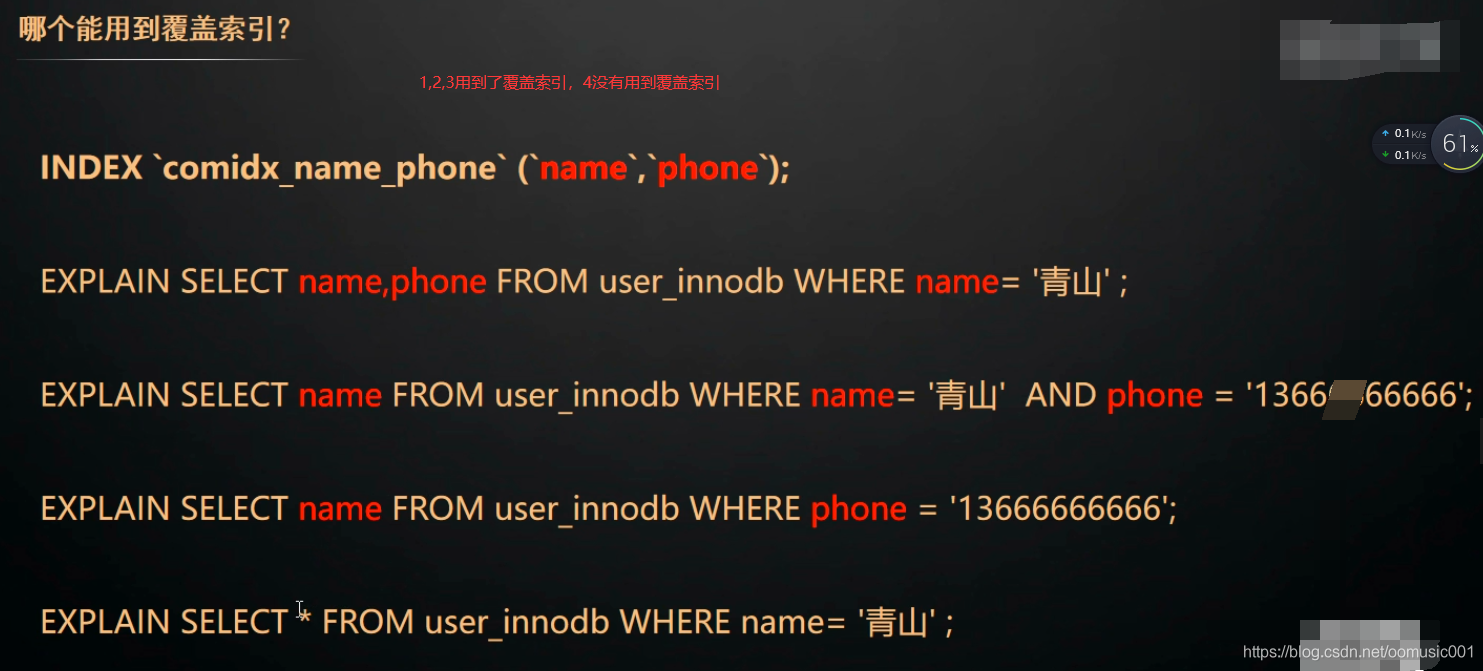
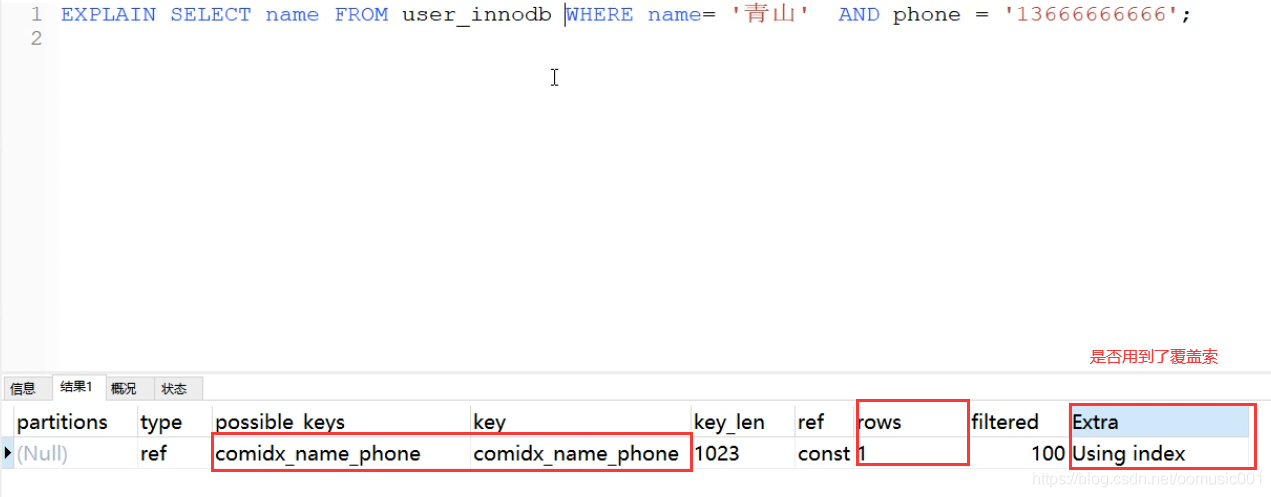
覆盖索引:当select 的列已经包含在用到的索引里的时候,这种情况叫做覆盖索引。覆盖索引不需要回表(不需要多差一个索引表)
select phone from user where name = 'zhangsan'; 因为name 和 phone 是联合索引,通过name就可以查到phone,不需要通过name查到主键索引,再通过主键索引去查找phone了。
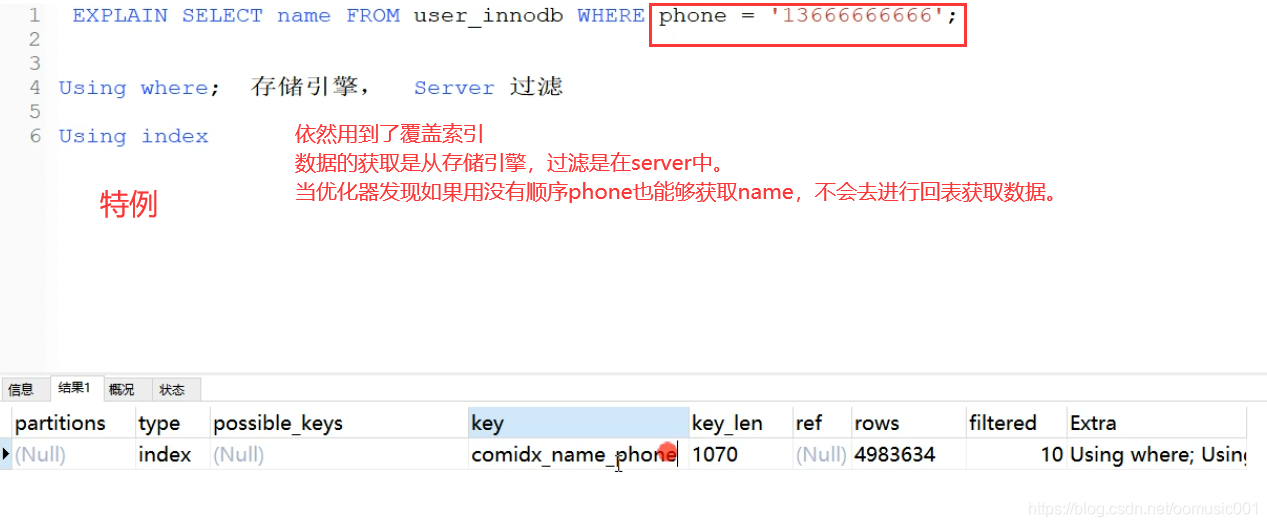
select * from user ..... 会导致回表。



AVL平衡二叉树解决的是二叉查找树插入的数据是递增的时候,会不平衡,导致树的深度很深,查找的效率很低。
B树(多路的平衡查找树)解决的是在一个节点上面存储空间的浪费,导致io次数过多的问题。
B+树,只在叶子节点存储数据,查找数据的io效率非常稳定,增加了页子节点的指针,增加了范围查找和顺序查找的效率。
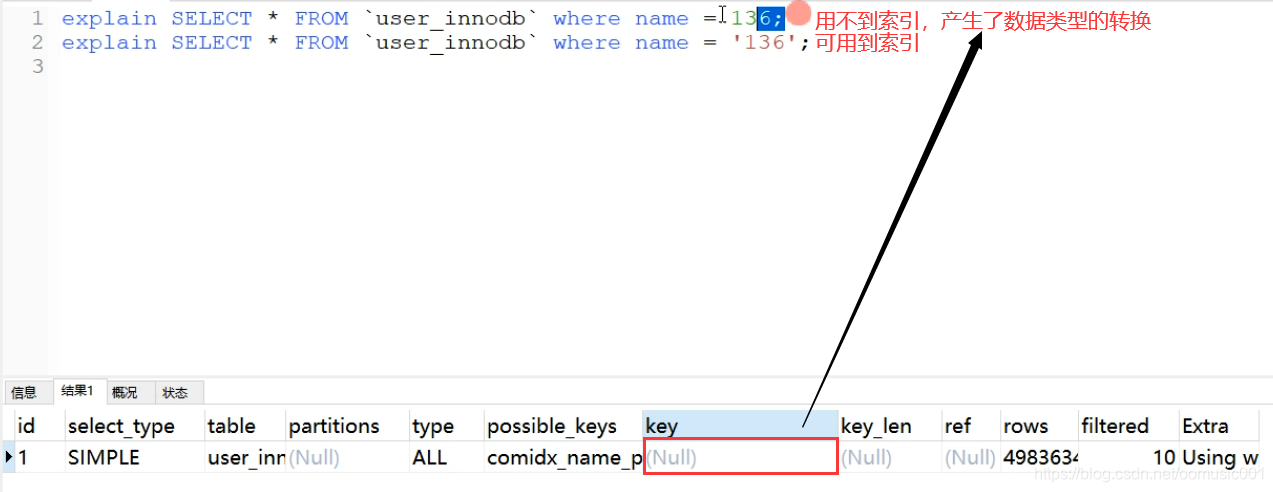
为什么不推荐uuid或身份证号作为索引?而是推荐有序的字段作为索引。
数据就是索引,索引就是数据。
因为uuid,idcard不连续。















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









