







paper:Going deeper with Image Transformers
official implementation:https://github.com/facebookresearch/deit
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/cait.py
出发点
这篇文章的研究重点是改进视觉Transformer(ViTs)在图像分类任务中的性能和训练稳定性。虽然视觉Transformer在某些方面表现出色,但随着网络深度的增加,模型在训练大规模数据集(如ImageNet)时常常面临收敛性和性能问题。作者基于Vision Transformer(ViT)架构和数据高效图像Transformer(DeiT)优化方法,致力于解决这些挑战。作者希望证明,当训练过程和模型架构进行适当修改时,模型确实可以从增加深度中受益。
创新点
对于深层视觉Transformer模型在训练过程中容易出现的不稳定性和性能瓶颈问题。本文通过引入LayerScale和Class-Attention,显著提高了深层模型的准确性和训练效果,使得这些模型在ImageNet等数据集上能够取得更好的表现。
- LayerScale: 在每个残差块的输出上引入可学习的对角矩阵,这种简单的层显著改善了训练动态性,允许训练更深层次的高容量图像Transformer。
- Class-Attention层: 将自注意力层与专门用于提取类别embedding的类注意力层分开,避免了在处理类嵌入时引导注意力过程的矛盾目标。这种新架构被称为CaiT(Class-Attention in Image Transformers),提高了分类器处理类嵌入的效率。
方法介绍
LayerScale
如图1所示,作者首先对比了几种不同的归一化策略。
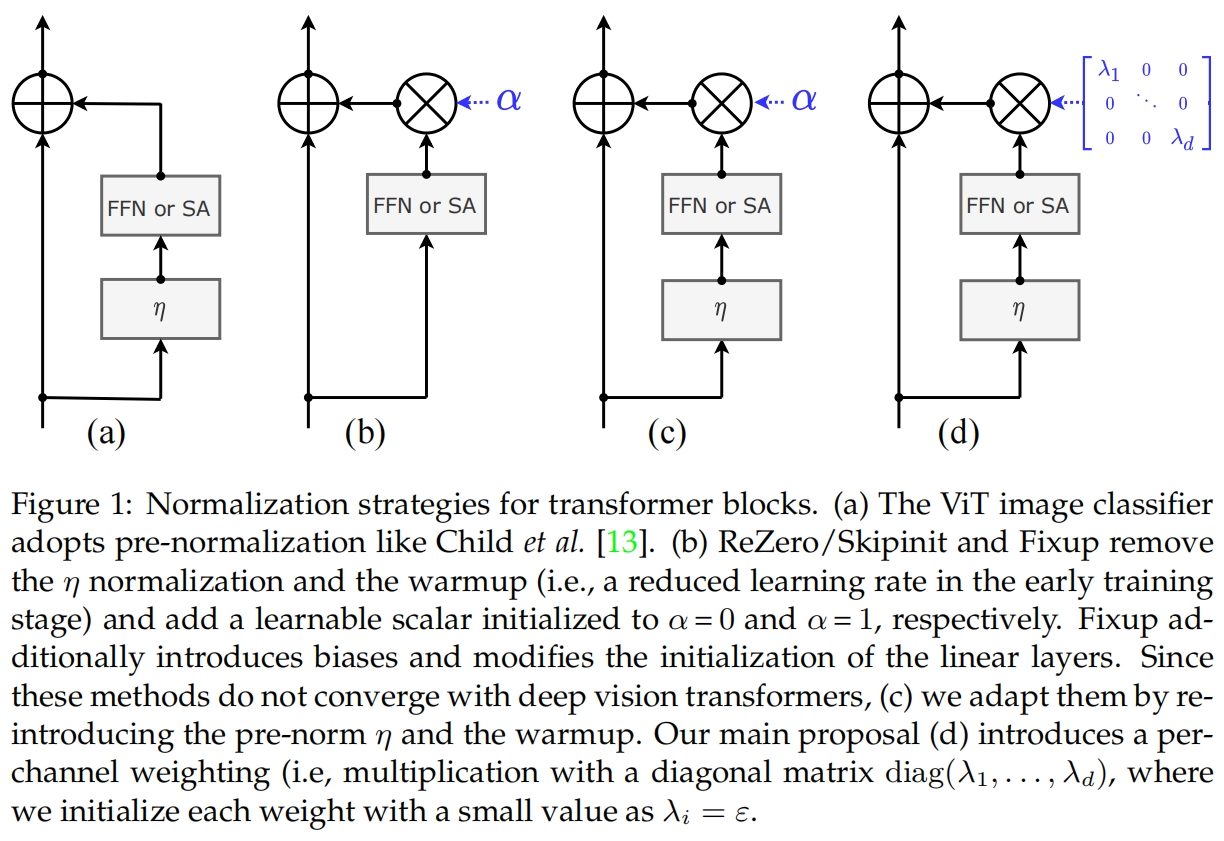
(a)是ViT和DeiT中使用的pre-norm结构。Fixup、ReZero和SkipInit对于residual block的输出引入了一个开学习的加权标量 \(\alpha_l\),同时去掉了pre-norm和warmup,如(b)所示。但作者通过实验发现,即使经过调参这些方法也无法收敛。作者认为是去掉的warm-up和layer-normalization导致训练不稳定的,因此作者在DeiT中又重新引入了这两个因素,如图1(c)所示,此时模型就收敛了。图1(d)是作者最终提出的LayerScale,即将(c)中的标量 \(\alpha\) 换成一个对角矩阵,从而实现per-channel的加权,如下式
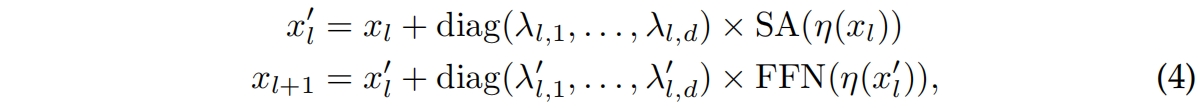
其中 \(\lambda_{l,i}\) 和 \(\lambda_{l,i}'\) 是可学习的权重,都初始化为一个固定的很小的数 \(\varepsilon \),网络深度小于18层时 \(\varepsilon =0.1\),网络层数为24层时 \(\varepsilon =10^{-5}\),更深的网络 \(\varepsilon =10^{-6}\)。
Class-Attention
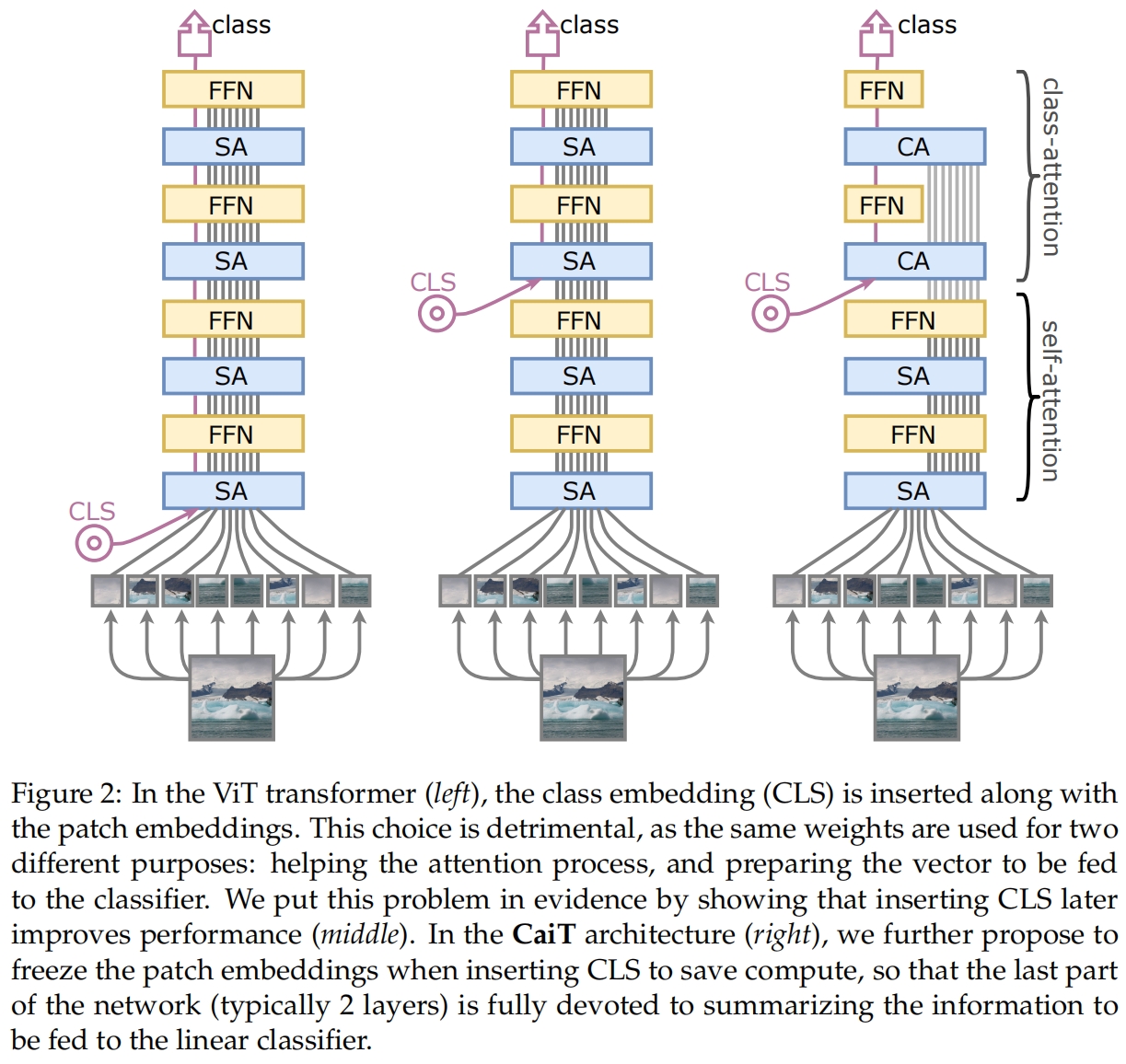
CaiT的结构如图2右所示,这样设计是为了避免ViT结构中存在的一个问题:学习到的权重被要求优化两个相互矛盾的目标,引导patch之间自注意力的学习的同时还要总结对线性分类器有用的信息。因此作者提出将这两部分分开进行。
作者首先想到把class token往后放,如图2中间所示,这样在前面的层网络只用专心学习self-attention,消除了前面层优化的矛盾问题。进而又提出了最终的结构如图2右所示,网络的最后两层换成了class-attention,整体结构还是self-attention,只不过其中只更新class token,而不更新patch embedding。
考虑一个有 \(h\) 个head和 \(p\) 个patch的网络 ,embedding size为 \(d\),我们用几个投影矩阵 \(W_q,W_k,W_v,W_o\in \mathbf{R}^{d\times d}\) 来参数化multi-head class attention,对应的bias为 \(b_q,b_k,b_v,b_o\in \mathbf{R}^{d}\)。我们首先扩展patch embedding得到 \(z=[x_{class},x_{patches}]\),然后按下式进行映射
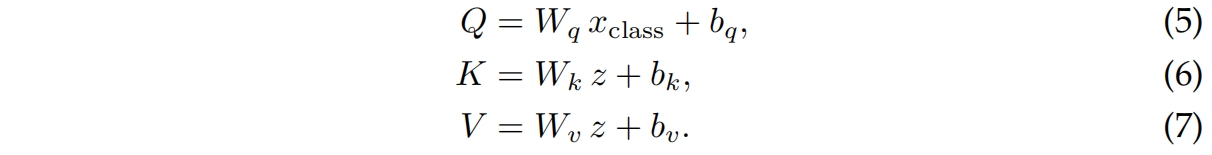
class-attention的权重根据下式得到
![]()
其中 \(Q\cdot K^{T}\in \mathbf{R}^{h\times 1\times p}\),然后根据下式得到残差输出向量
![]()
其实class-attention和普通的self-attention的区别就在于后者式(5)中的 \(x_{class}\) 是 \(z\)。作者通过实验发现两层的class-attention就足够了。
实验结果
对LayerScale的分析
作者首先评估了Layerscale对一个有36个block的transformer的影响,具体通过参数激活的norm和主分支激活的norm的比值 \(\left \| g_l(x) \right \|_2/\left \| x \right \|_2 \) 来衡量,如图4所示。可以看到,使用Layerscale训练一个模型可以使这个比值在不同层之间更加统一并且似乎防止了某些层对激活产生不成比例的影响。

表2展示了不同层数的self-attention和class-attention的组合的结果,可以看到12层self-attention加上2层class-attention得到的效果最好。
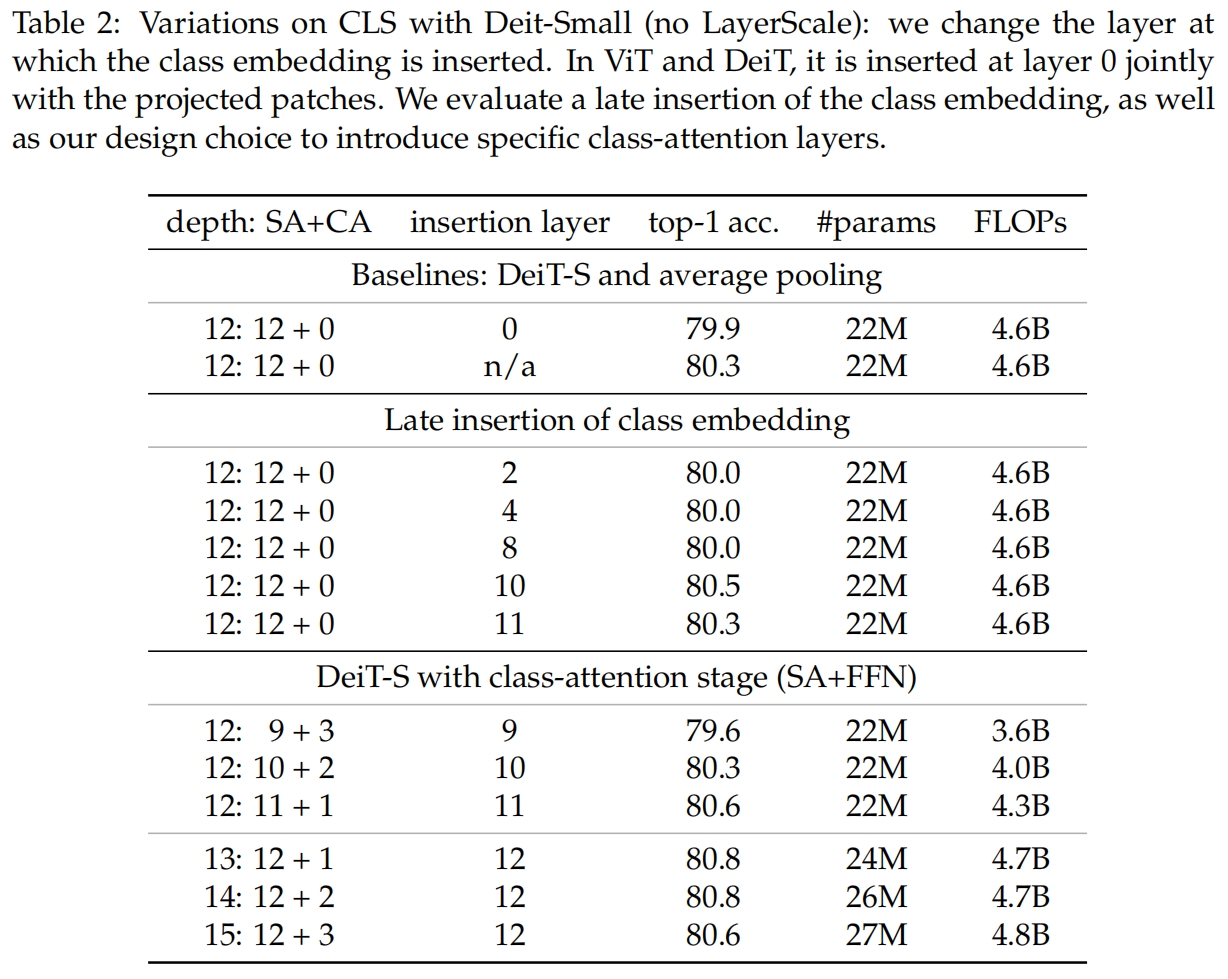
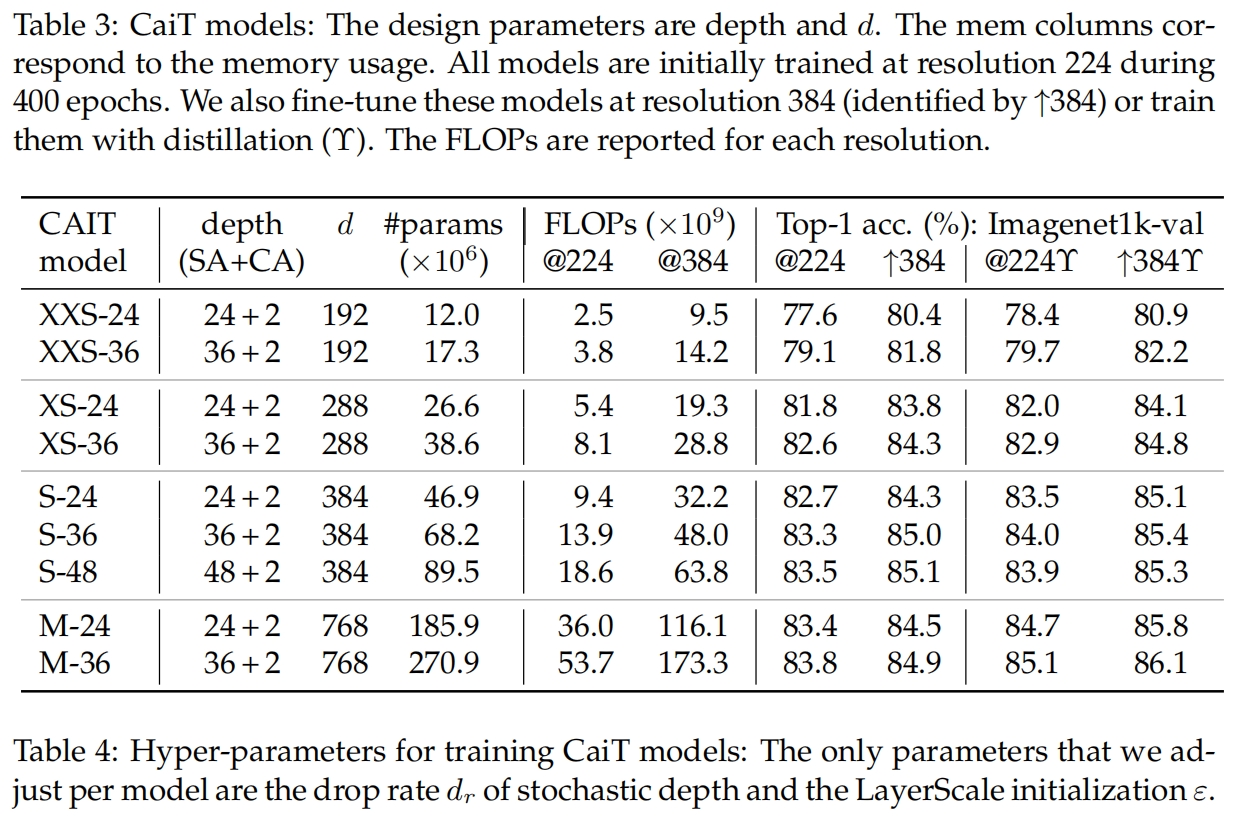
表3是不同size的CaiT模型的配置、参数量和精度的对比。
不同的CaiT模型除了网络层数和特征维度不同外,还有两个超参也不一样,如表4所示。
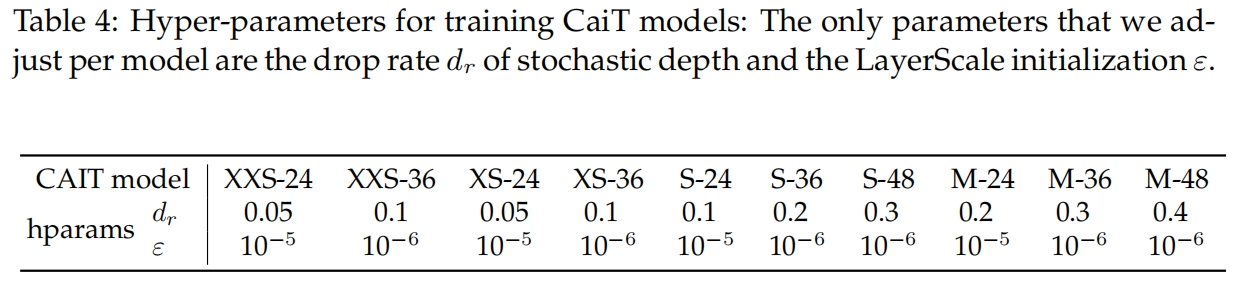
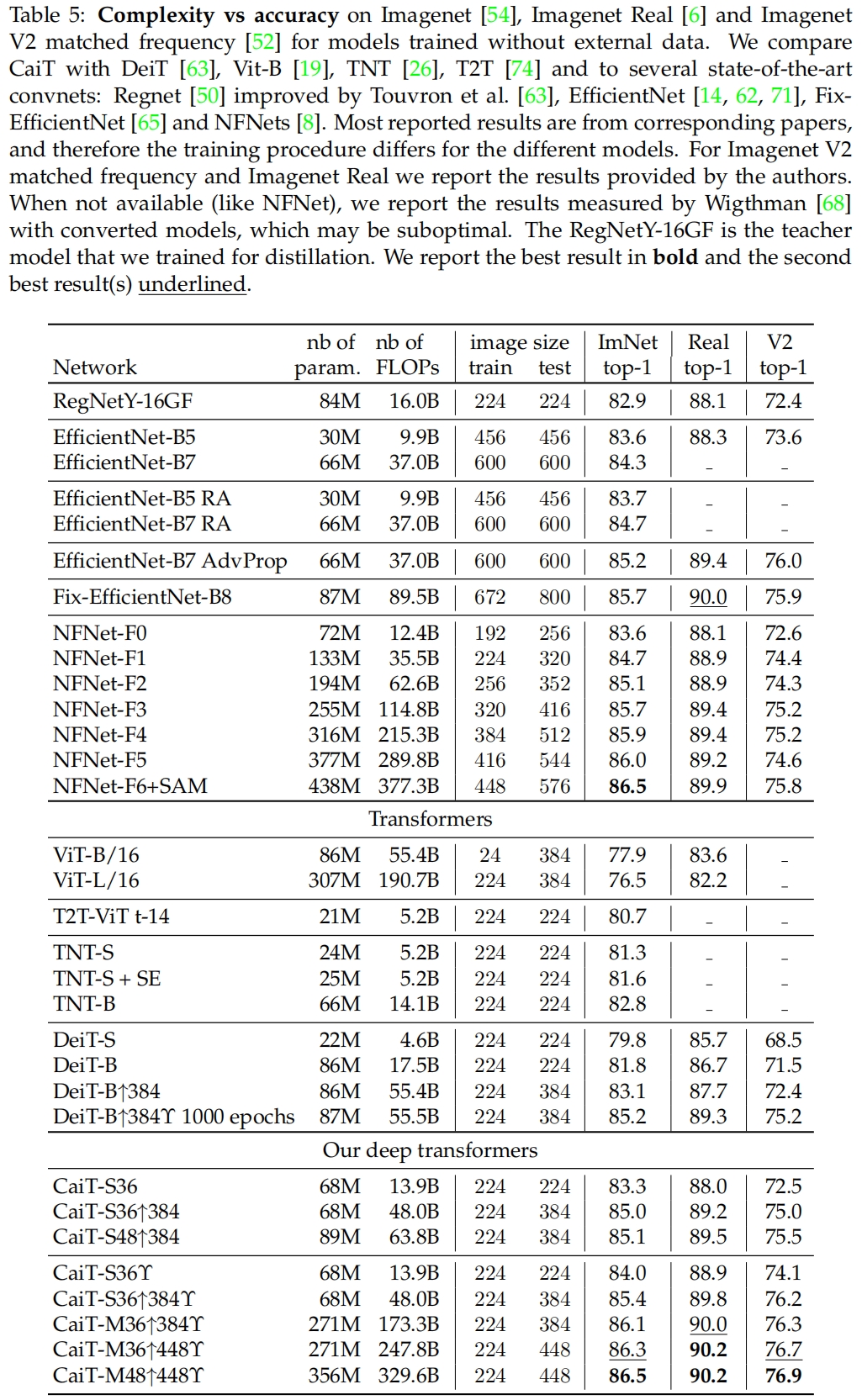
表5是和其它SOTA模型在ImageNet上的结果对比。
代码解析
这里以timm中的实现为例,输入shape为(1, 3, 224, 224),模型选择"cait_s24_224"。
LayerScaleBlock中的forward函数如下,可以看到和普通transformer block的区别就是在attention和mlp的后面分别乘上了一个self.gamma_1和self.gamma_2,即本文提出的layerscale。论文中提到 \(\alpha\) 即这里的gamma_1和gamma_2是一个对角矩阵,但这里就是一个维度和transformer block的特征维度相等的向量,比如self.attn的输出shape为(1, 196, 384),其中1是batch size,196是seq_len即patch的数量,384是特征维度,而gamma_1和gamma_2的维度都是(384, )。
self.gamma_1 = nn.Parameter(init_values * torch.ones(dim))
self.gamma_2 = nn.Parameter(init_values * torch.ones(dim))
def forward(self, x):
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
return x另外这里的self.attn=TalkingHeadAttn,论文中作者提到CaiT中的attention使用的是Talking-Heads Attention,具体介绍见Talking-Heads Attention-CSDN博客。
然后是class attention,代码如下。其中和self-attention的区别就是上面提到的式(5),即下面的第22行,self.q投影时选择了x[:, 0]即只投影class token,而在self-attention中是投影全部的x包括class token和后面的patch embddings。
class ClassAttn(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to do CA
fused_attn: torch.jit.Final[bool]
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.fused_attn = use_fused_attn()
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.k = nn.Linear(dim, dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape # (1,197,384)
q = self.q(x[:, 0]).unsqueeze(1).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
# (1,384)->(1,384)->(1,1,384)->(1,1,8,48)->(1,8,1,48)
k = self.k(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # (1,8,197,48)
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # (1,8,197,48)
if self.fused_attn:
x_cls = torch.nn.functional.scaled_dot_product_attention(
q, k, v,
dropout_p=self.attn_drop.p if self.training else 0.,
)
else:
q = q * self.scale
attn = q @ k.transpose(-2, -1) # (1,8,1,197)
attn = attn.softmax(dim=-1) # (1,8,1,197)
attn = self.attn_drop(attn)
x_cls = attn @ v # (1,8,1,48)
x_cls = x_cls.transpose(1, 2).reshape(B, 1, C) # (1,1,384)
x_cls = self.proj(x_cls) # (1,1,384)
x_cls = self.proj_drop(x_cls)
return x_cls


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











