







简介:梳理了MyBatis的基本使用和常用知识点,基本使用的都是xml描述,注解开发可以查看此篇:注解开发。
某些更具体的解释写在了链接的文章中。
目录
1. MyBatis概述
想要用Java程序操作数据库,我们可以使用传统的JDBC。但是,由于连接的建立,预处理对象的获取,结果集的处理,连接的释放等等,让人们不得不关注除业务核心逻辑(SQL语句)之外的东西。再加上占位符使用时的繁琐操作,加大了负担。
而MyBatis就封装了非核心代码,让人们可以只专注于SQL语句的编写,并通过配置和业务代码的分离,让模块耦合度更低。
2. MyBatis整体概览
想要操作数据库,那么连接数据库的步骤还是省不了的。MyBatis为我们提供了创建连接的接口,我们需要做的就是把连接的一些基本信息,如驱动,数据库地址等(即数据源相关信息),写在配置文件里,然后交给我们的框架。
然后,框架会给根据配置文件,给我们一个session对象。该对象内部,包含了一个前面建立好的连接对象,还有对应的接口方法及其实现。这样,我们就可以通过它,用于CRUD的操作。
我们以前都是写去写实现类来实现接口,而这里,可以把实现过程写到Mapper.xml中,从而获得接口的代理对象,进而实现一样的CRUD操作。
代码如下:

//读取配置文件
InputStream in = Resources.getResourceAsStream("MapConf.xml");
//用一个建造者对象在负责会话工厂的构建
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
//用这个建造者,根据配置文件,造一个会话工厂
SqlSessionFactory factory = builder.build(in);
//从这个工厂中获得对话对象
SqlSession session = factory.openSession();
//会话对象获得接口(userDao)的代理对象
//该对象中方法的实现是通过读取Mapper.xml实现的
UserDao userDao = session.getMapper(UserDao.class);
//使用方法,并在需要时提交事务
userDao.crud等();
//关闭资源
session.close();
in.close();
3. MyBatis主配置文件
在这里,主要配置了数据源信息,并制定了连接连接池的方式和事务管理方式。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--配置环境-->
<environments default="mysql">
<!-- 配置mysql的环境-->
<environment id="mysql">
<!-- 配置事务 -->
<transactionManager type="JDBC"/>
<!--配置连接池-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost/stu"/>
<property name="username" value="root"/>
<property name="password" value="1234"/>
</dataSource>
</environment>
</environments>
<!-- 配置映射文件的位置 -->
<mappers>
<mapper resource="com/hello/dao/UserDao.xml"/>
</mappers>
</configuration>
最后的标签,用来放我们前面提到的接口方法和方法具体实现的映射文件。
4. 基于xml编写CRUD
通过前面的Java程序可以看出,框架已经帮我们得到了接口的代理对象,通过该对象即可使用方法了。那么既然可以不写实现类,我们具体的实现写在哪呢?答案就是写在刚才提到多次的Mapper.xml配置文件中。
该文件指明了某个方法和其实现的对应关系。在一个工程中,
想要确定一个方法:有全限定类名,方法名,参数列表即可。在映射文件中,我们使用
<mapper namespace="com.hello.dao.UserDao"> </mapper>
中的namespace属性来指明全限定类名,该类的所有方法,就可以都以子标签的形式放在里面。我们以查询所有为例:
<select id="findAll" resultType="com.hello.domain.User">
select * from user;
</select>
id就代表了方法名,resultType代表了方法的"返回类型"。由于该方法是无参的,所以省略了参数列表,如有需求,可以放入parameterType属性中。(注:如果有多个参数:https://www.jianshu.com/p/d977eaadd1ed)
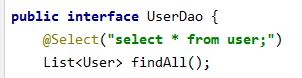
public interface UserDao {
List<User> findAll();
}
查询结果如下:

如果需要使用占位符,则可以使用#{属性名},来指定,比如看下面这个实例:
接口:

mapper.xml中的实现

xml中的parameterType属性,指明了对象类型传入的是ORM映射过来的实体类,占位符大括号里填的正是该对象的属性名。
比如我传了一个user对象,name属性是"xxx"。那么框架就会把这个对象的name属性的值,放到占位符中。
其他操作的例子 如下:
<mapper namespace="com.hello.dao.UserDao">
<select id="findAll" resultType="com.hello.domain.User">
select * from user;
</select>
<select id="findById" parameterType="int" resultType="com.hello.domain.User">
select * from user where id=#{id};
</select>
<insert id="saveUser" parameterType="com.hello.domain.User">
<selectKey keyProperty="id" keyColumn="id" resultType="Integer" order="AFTER">
select last_insert_id();
</selectKey>
insert into user(name,sex) values(#{name},#{sex});
</insert>
<update id="updateUser" parameterType="com.hello.domain.User">
update user set name=#{name},sex=#{sex} where id=#{id};
</update>
<delete id="deleteUser" parameterType="Integer">
delete from user where id=#{id};
</delete>
</mapper>
有一个比较特殊的地方:插入。
由于主键id是自增长的,所以我们在插入时,不需要设置值,但这样我们就不能知道插入后的对象,id的值是多少。测试如下:
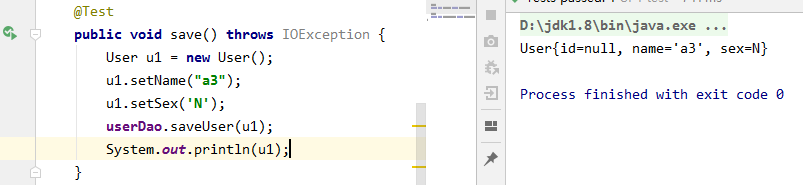
可以看出,虽然数据库中可以查看id(下图),但是对象中是没有的。
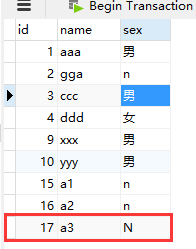
对此,我们可以通过标签来在插入后,获得此对象的id。写法如下:
<selectKey keyProperty="id" keyColumn="id" resultType="Integer" order="AFTER">
select last_insert_id();
</selectKey>
keyProperty是实体类中的属性名,
keyColumn是数据库表中的列名,这里就是告诉它主键是哪个列resultType是返回结果的数据是型,
order是执行的顺序。
该方法会通过执行select last_insert_id();语句,然后把结果封装到实体类属性中。
这样,对象的id值就也有了:
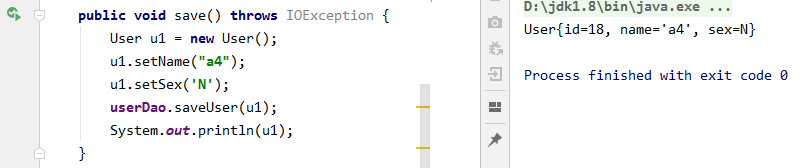
5. 基于注解编写CRUD
使用注解,我们就不需要在xml中来写实现,而是直接写在接口上。
不过在使用之前, 先把主配置文件中的一些细节修改:
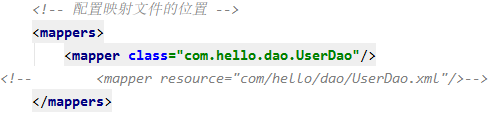
这里要把resource属性换成class属性,属性值写上接口的全限名,这样框架就会去解析该接口的注解,并执行相应的操作(xml文件及包要删除)。
==这篇文章的主要内容都使用xml配置,详细的注解开发写在了这篇博文中:
MyBatis的注解开发
6. 实体类属性和列名不一致
由于有些SQL操作,返回的是一个记录,而这些记录,会通过列名和属性的对应关系,把值付给对象的属性,比如:
<select id="findById" parameterType="int" resultType="com.hello.domain.User">
select * from user where id=#{id};
</select>
因为我们在resultType指定了返回类型为User,所以框架会把记录的列表,按和列名同名的属性名,来封装进去,如果对不上,那就无法封装,所以我们必须要让属性名和列名保持一致。
如果不一致的话,有2种解决方案。
-
方法一,取别名:给列名取别名,而别名正是实体类的属性名,就可以解决此问题。该方式执行效率高,但编写效率较低。
-
方法二,写Mapper映射:既然不能自动找到对应关系,那么我们就手动来让列名和属性对应起来:使用标签
<resultMap id="userMap" type="实体类的全限名">
<id property="实体类属性名" colum="列名"></id>
<result property="实体类属性名" colum="列名"></id>
<result property="实体类属性名" colum="列名"></id>
</resultMap>
上述标签中,resultMap的id属性用来标识这个映射,id子标签用来标识主键和属性的对应关系,result子标签用来标识其它列和属性的对应关系。
那么写好了这个,用在哪儿呢?答案就是:
<select id="findById" parameterType="int" resultType="com.hello.domain.User">
select * from user where id=#{id};
</select>
这是之前的查询语句,现在我们要把resultType改成resultMap:
<select id="findById" parameterType="int" resultMap="userMap">
select * from user where id=#{id};
</select>
这里resultMap填写的值,就是前面resultMap标签的id属性值。
这种方式,可以提高代码的复用性,但多了一次xml的解析,执行效率会有所降低。
7. SQL的动态注入
8. 表间关系
9. 延迟加载
有时候我们查记录,并不一定想查出其所有的关联信息。
比如现在有两张表:
用户表和订单表,他们之间是一对多和一对一的关系:一个用户有可多个订单,每个订单仅能对应一个用户。
当我们查用户的时候,如果总是把它关联的上百条订单信息,都一起查出来,那么会很大得影响性能。所以,我们要采用延迟加载的手段,当要使用订单信息时,再查。
何时使用延迟加载?
当我们的关联表,是“1”的时候,显然数据量不会太多,我们一般用立即加载而不启用延时加载。而如果是“多”,我们就会使用 延迟加载。
比如,一个用户只对应一个出生地信息,对于这种1对1的关联,通常使用立即加载。而对于一个用户的N条订单信息,我们就使用延迟加载。
如何使用延迟加载?
虽然对一的时候,通常不使用延迟,但还是一起演示一下,使用的例子是人类和手机,每个手机只有一个主人,每个人可有多个手机。
- 对一

以前是通过多表连接,直接查出手机对应的人的信息,所以会把该人的信息封装到human对象中。而延迟加载,就不需要这样的配置,因为根本不会返回“机主”的信息。所以我们把子标签的内容可以删除。然后再加上select属性和column属性。
select属性:写一个方法,该方法为“通过id查到相应的数据”,如这里我们就是要调用人类的findHumanById方法,来获得记录。
column属性,findxxxById方法,总是要传入一个Id作为形参的,那这个形参,正是由column字段的值提供的,比如本例中,就是手机表的hid字段。
<resultMap id="phoneMap" type="phone">
<id property="pid" column="pid"/>
<result property="brand" column="brand"/>
<result property="hid" column="hid"/>
<!-- 下面的并不在表的字段中,但是在实体类中是有属性的-->
<association property="human" javaType="human"
select="人类dao接口的全限名.findxxxById"
column="hid">
</association>
</resultMap>
<select id="findAll" resultType="phone">
select * from phone;
</select>
- 对多
对多和对一大同小异:
<resultMap id="humanMap" type="human">
<id property="hid" column="hid"></id>
<result property="name" column="name"></result>
<collection property="phones" ofType="phone"
select="手机dao接口的全限名.findxxxById"
column="hid">
</collection>
</resultMap>
<select id="findAll" resultType="humanMap">
select * from human
</select>
光是这样配置还不能够起作用,还需要在主配置文件进行延迟加载的开启

在< configuration>标签下写
<settings>
<setting name="lazyLoadingEnabled" value="true">
<setting name="aggressiveLazyLoading" value="false">
</settings>
10. 缓存
一级缓存
使用的是sqlSession对象中的一个Map空间,该缓存是默认开启的。查数据时,先查看该Map,如没有,再去数据库中查。因为是放在sqlSession中的,所以如果该对象关闭了,缓存也就自动消失了(调用session对象的clearCache()方法可以手动清除缓存)。
增删改操作:
如果调用sqlSession对象的增删改,提交,关闭等方法,就会自动清除一级缓存。从而在一定程度上,避免了缓存数据和库中不一致的情况。
二级缓存
二级缓存是放在SqlSessionFactory这个工厂中的,所以所有从这个工厂中开启的session对象,都可以访问到该缓存,所以它的影响范围是一个命名空间,只要是同一个namespace中的操作,都影响着同一个缓冲区。而一个命名空间通常都是对一个表进行操作的,所以可以理解为,不同的对象操作同一个表,都有一个公共的缓存区。

不过二级缓存不是默认开启的,开启步骤如下:
①:在主配置文件中添加配置:
和配置延迟加载一样,
在< configuration>标签下写
<settings>
<setting name="cacheEnabled" value="true">
</settings>

不过可以看出,由于默认值就是true,所以不写也行。
②:在实现dao接口的xml文件中添加配置:
在< mapper>标签下写:
<cache/>
③:让操作的方法支持此配置:
该操作依然是在实现dao接口的xml文件中,在相应的查询语句上,添加useCache="true"

和一级缓存一样,二级缓存在面对更新操作时,同样会清空缓存。并且多表操作时,使用二级缓存会产生脏数据,所以如果要使用多表操作,就不要开启二级缓存。
还需要注意的一点的,一级缓存存放的是对象,二级缓存存放的是数据。所以当查询命中二级缓存时,会再新建一个对象,来封装这些数据,然后返回给调用者。















 5282
5282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









