







Elasticsearch也需要安装IK分析器以实现对中文更好的分词支持。
去Github下载最新版elasticsearch-ik
https://github.com/medcl/elasticsearch-analysis-ik/releases

将ik文件夹放在elasticsearch/plugins目录下,重启elasticsearch。
Console控制台输出:
[2019-09-04T08:50:23,395][INFO ][o.e.p.PluginsService ] [THINKPAD-T460P] loaded plugin [analysis-ik]
2|0二、测试分词效果
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
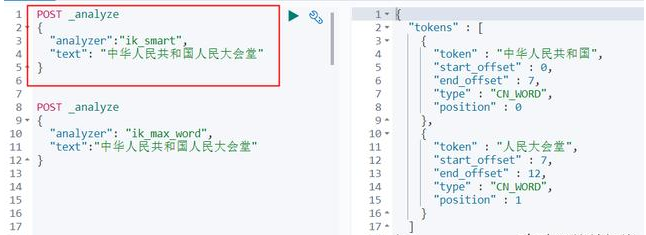
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
测试两种分词模式的效果。分词查询要用GET、POST请求,需要把请求参数写在body中,且需要JSON格式。
发送:post localhost:9200/_analyze
(1)测试ik_max_word
POST _analyze { "analyzer": "ik_max_word", "text":"中华人民共和国人民大会堂" }
(2)测试ik_smart
POST _analyze { "analyzer":"ik_smart", "text": "中华人民共和国人民大会堂" }
网上关于两种分词器使用的最佳实践是:索引时用ik_max_word,在搜索时用ik_smart。
即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
不过,需要注意的是:ik_smart 分词结果并不是 ik_max_word的子集。这样,在使用ik_max_word 建索引,用ik_smart 搜索时,有可能结果匹配不上,所以这是两种不同类型的分词结果,建议还是不要混用。
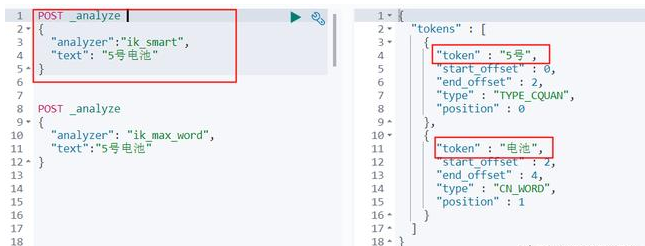
下面测试【5号电池】,在两种分词模式下的输出结果。

3|0三、扩展词典
在elasticsearch/plugins/ik/config下新建my.dic文件,在my.dic中写入想要分词识别的文字;修改IKAnalyzer.cfg.xml文件,在<entry key="ext_dict">中指定my.dic。
<properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">my.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
重启elasticsearch即可看到分词效果。















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









