







cache 将数据临时存储在内存中进行数据重用
会在血缘关系中添加新的依赖,一旦出现问题,可以重头读取数据
persist:将数据临时存储在磁盘文件中进行数据重用
涉及到磁盘IO,性能较低,但是数据安全
如果作业执行完毕,临时保存的数据文件就会丢失
会在血缘关系中添加新的依赖,一旦出现问题,可以重头读取数据
checkpoint 将数据长久地保存在磁盘文件中进行数据重用
涉及到磁盘IO,性能较低,但是数据安全
为了保证数据安全,所以一般情况下,会独立执行作业(在原有的job上重新起动一个job)
为了能够提高效率,一般情况下,是需要跟cache联合使用的(这样就不独立执行了)
执行过程中,会切血缘关系,重新建立新的血缘关系
checkpoint等同于改变数据源
源码:



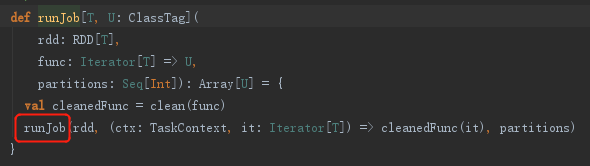

当dagScheduler.runJob执行之后,执行了rdd.doCheckpoint操作


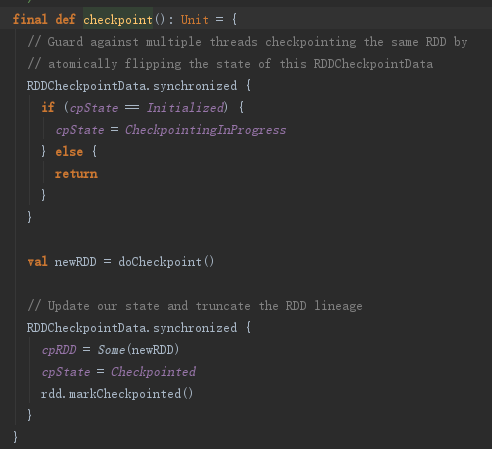
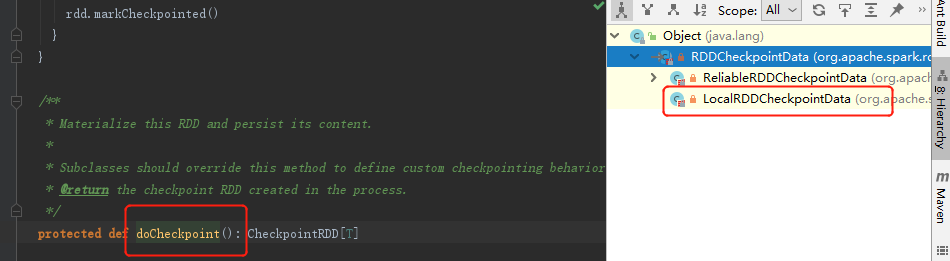
在底层又再一次提交了job因此会执行两次job
















 2818
2818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









