







 该文章详细介绍了Spark编程中创建配置,读取文件,使用flatMap进行单词拆分,reduceByKey进行词频统计的过程,并提到了任务调度的两种方式:FIFO和公平调度。
该文章详细介绍了Spark编程中创建配置,读取文件,使用flatMap进行单词拆分,reduceByKey进行词频统计的过程,并提到了任务调度的两种方式:FIFO和公平调度。
val conf: SparkConf = new SparkConf().setMaster("local").setAppName("wordcount")
val context: SparkContext = new SparkContext(conf)
val file: RDD[String] = context.textFile("datas")
val wordcount: RDD[(String, Int)] = file.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
wordcount.collect().foreach(println(_))
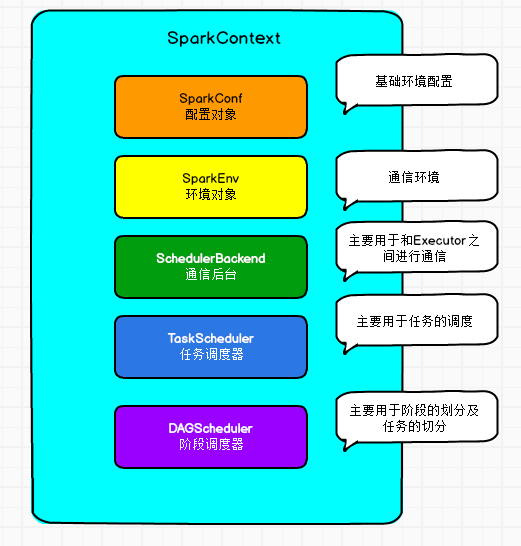
context.stop()1.应用程序会new SparkContext对象
SparkConf 环境配置
SparkEnv 环境
SchedulerBackend 调度后台
TaskScheduler 任务调度
DAGScheduler 作业调度
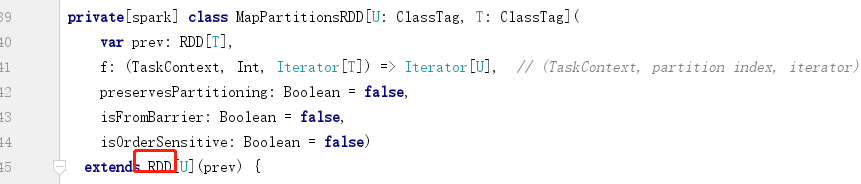
2.构建依赖
context.textFile("datas")


flatMap(_.split(" "))

reduceByKey(_+_)

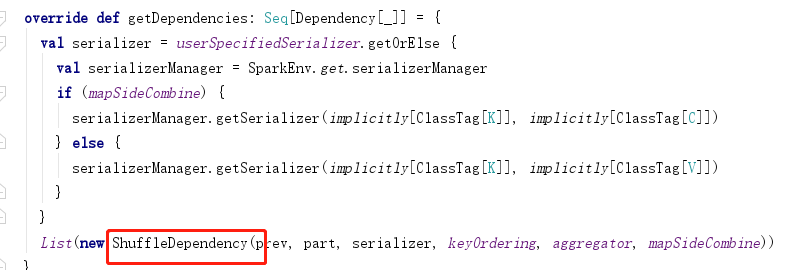
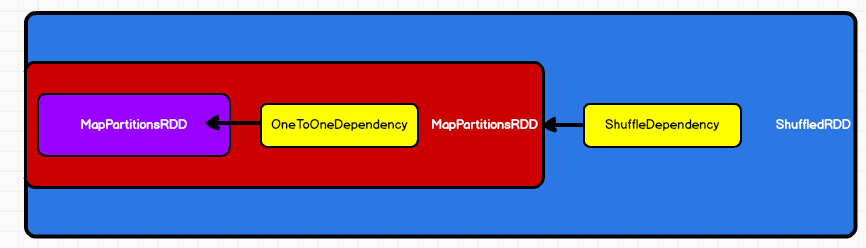
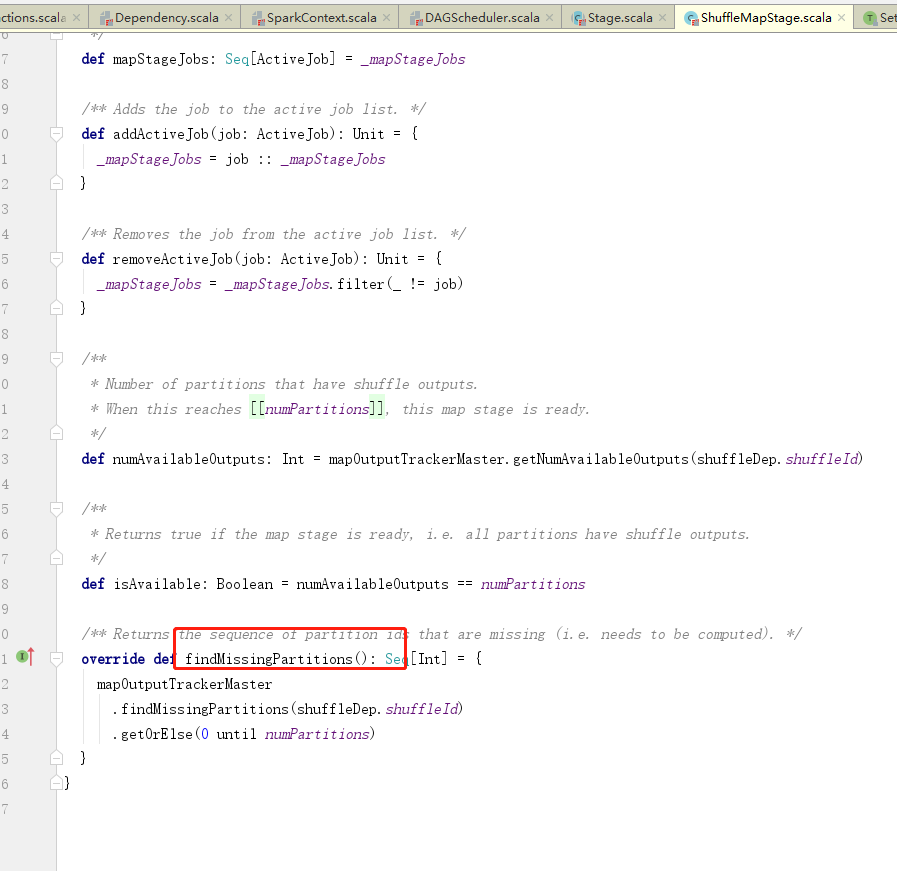
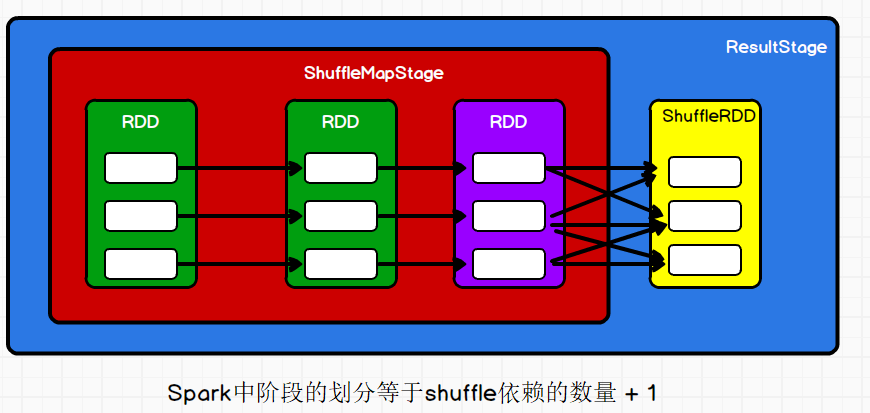
3.阶段划分

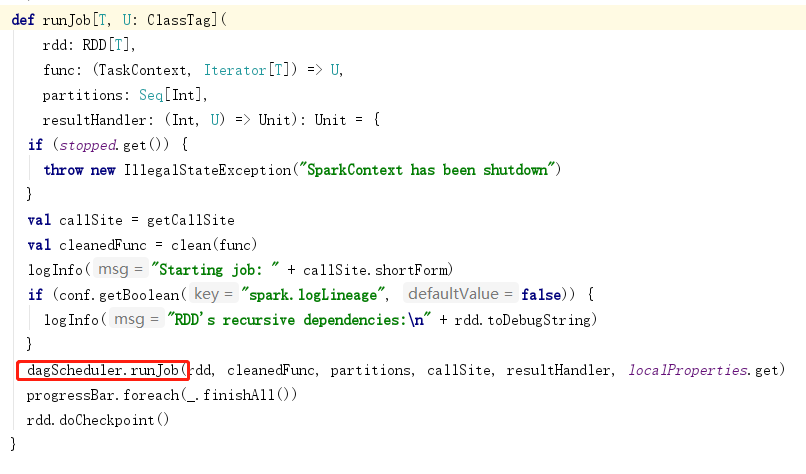
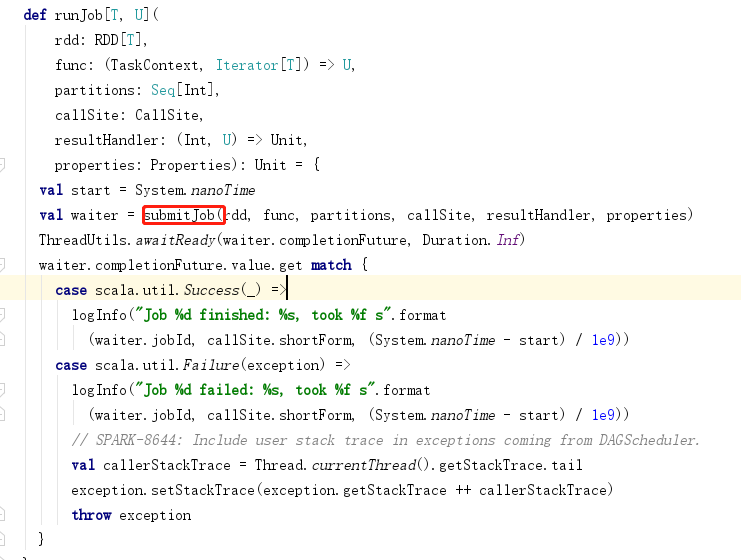


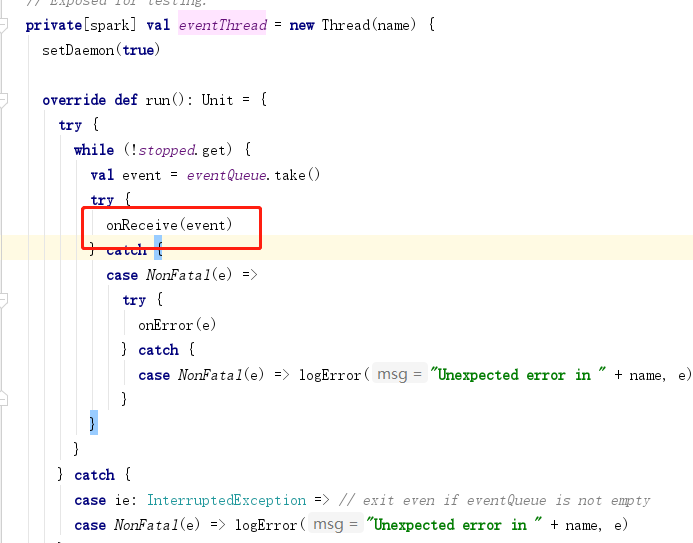
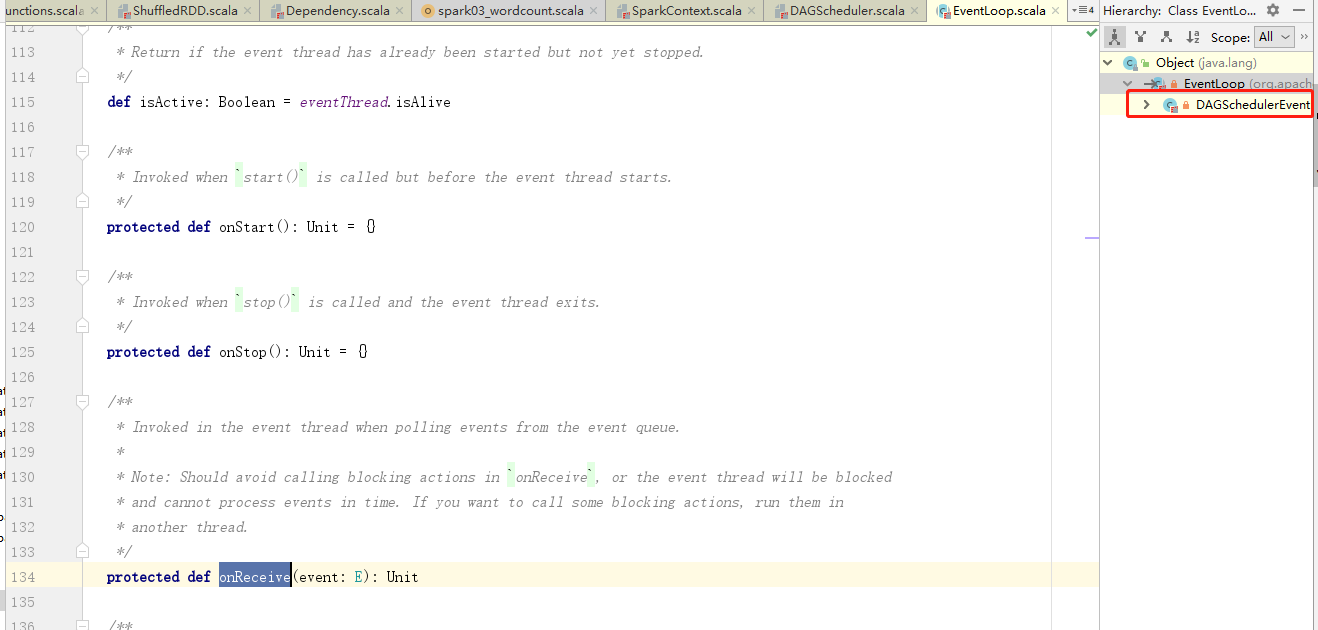


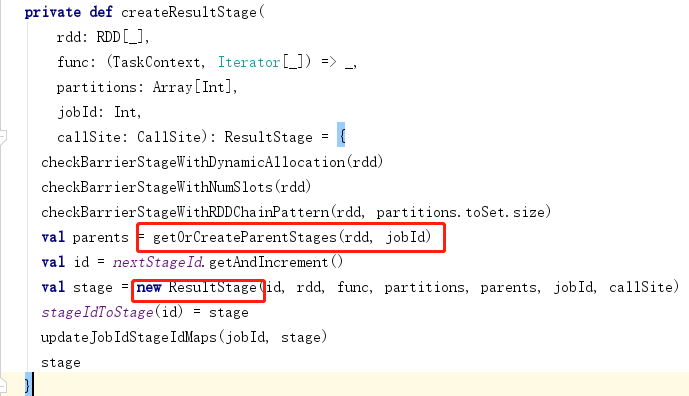

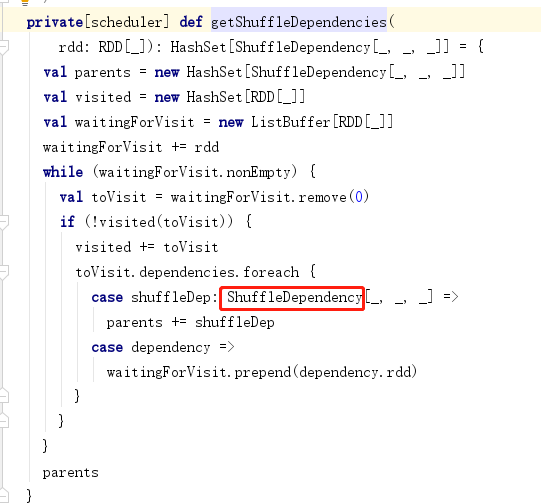
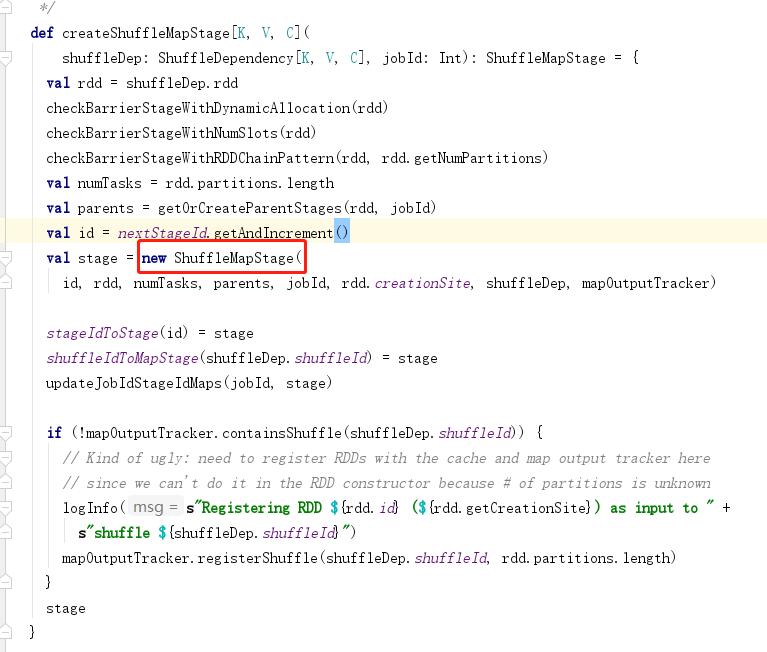
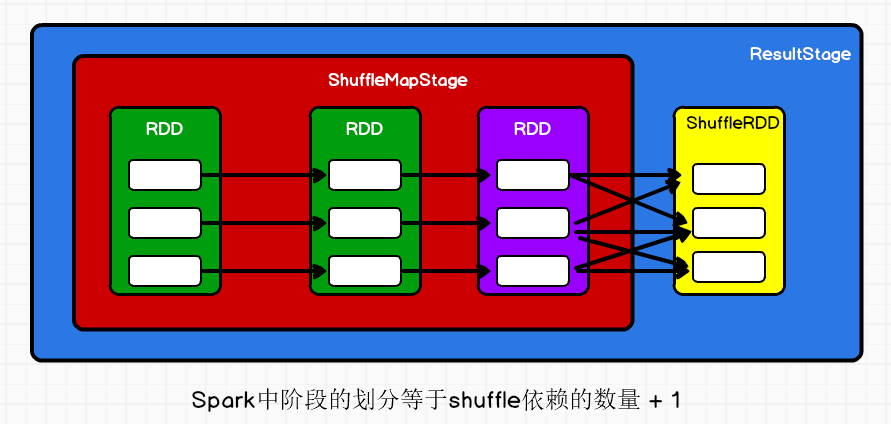
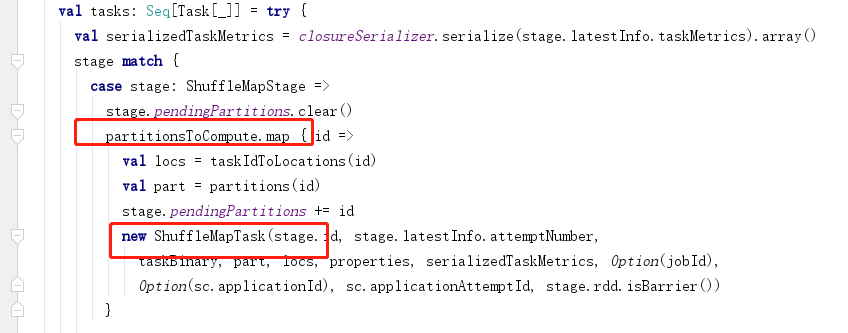
4.任务划分
每个阶段task的数量是每个阶段的最后一个RDD的分区的数量
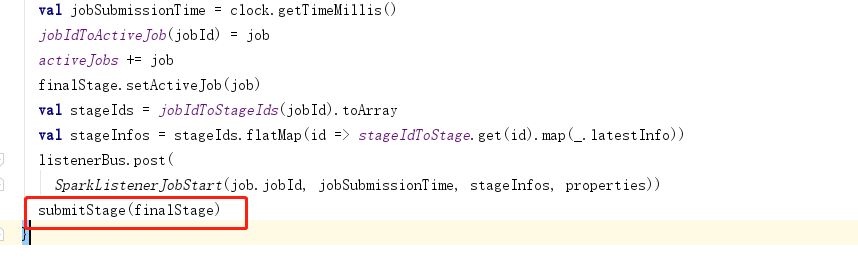
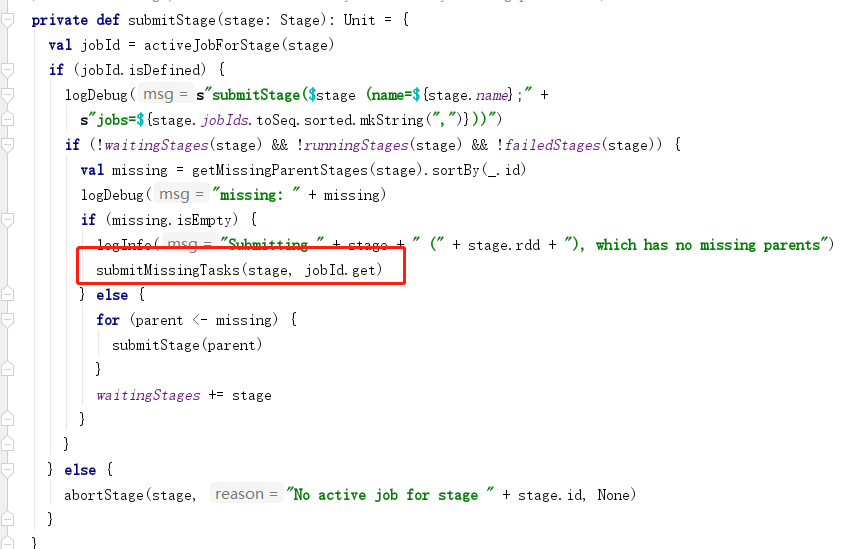
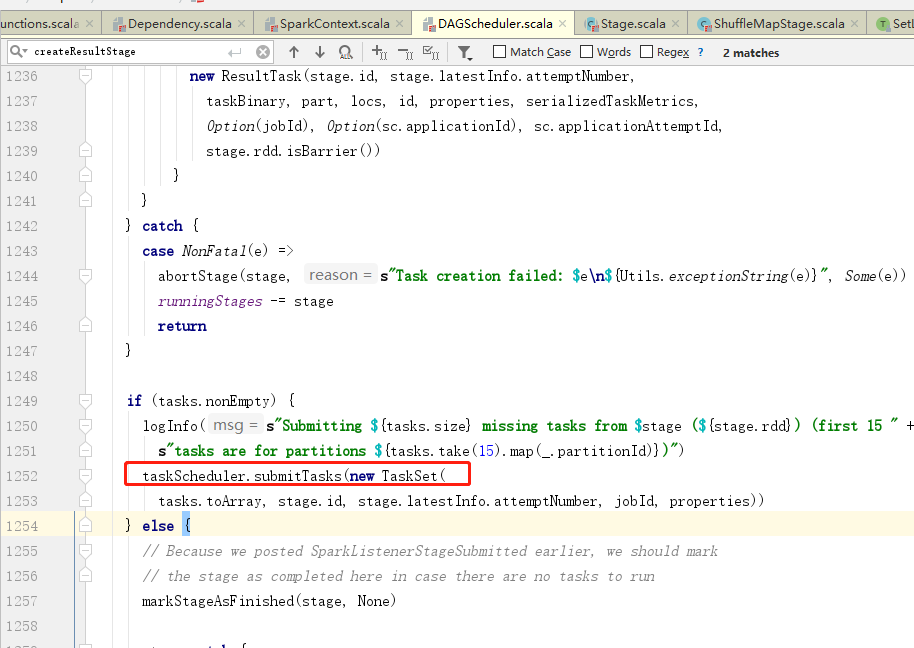
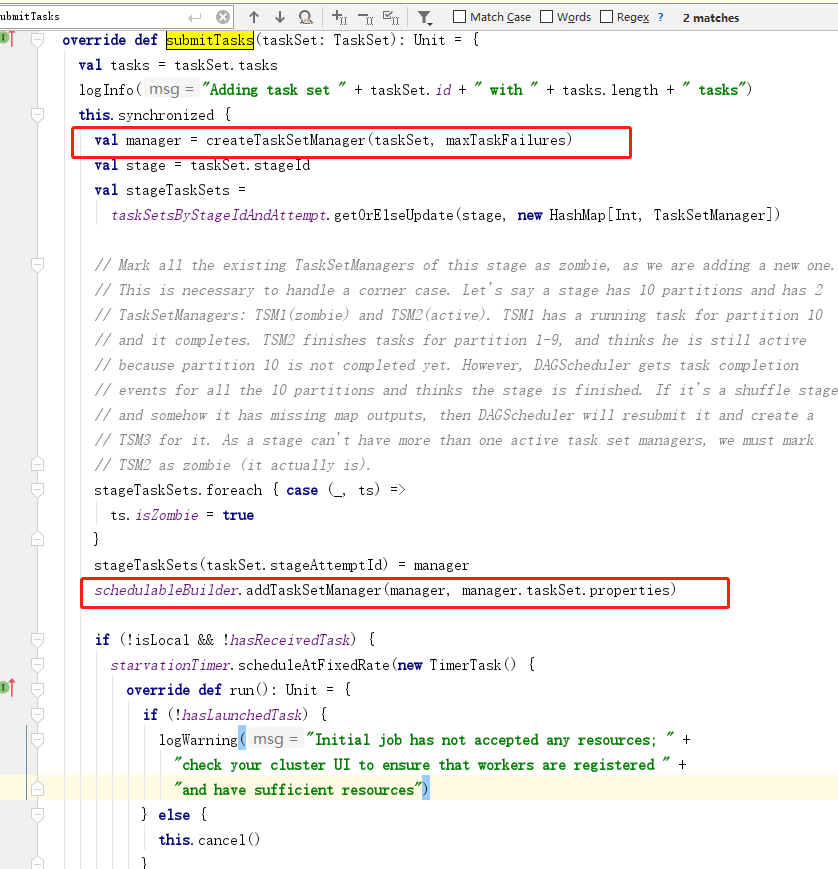
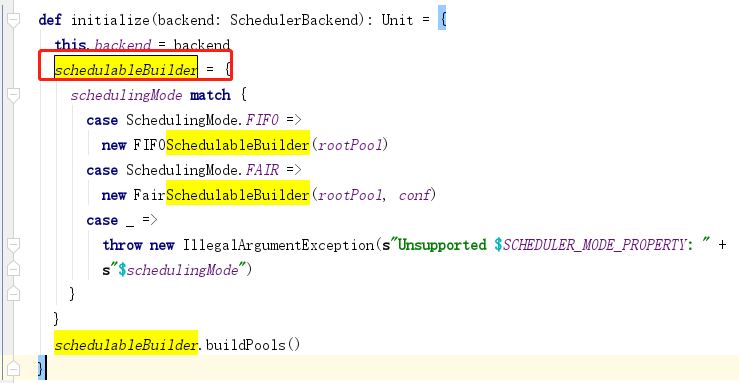
5.任务的调度
在spark中默认的调度方式是fifo
一共两个 公平调度和先进先出调度




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









