






作者介绍:云和恩墨资深Oracle dba,专注于数据库运维、架构和行业发展,有12年左右的金融、保险、政府、地税、运营商等业务关键型系统的运维经验,曾担任公司异常恢复东区接口人,负责紧急异常恢复工作,技术二线专家。目前负责PG、openGauss/MogDB运维、国产化MogDB数据库的推广工作。
一、问题表象:
最近客户遇到一个奇怪的问题,oracle数据库大量undo段迟迟不expired, 最终导致undo不够用,引发一系列undo相关报错,关于隐患参数_undo_autotune是false。v$undostat 始终只有一行,数据一直累加,而正常环境应该是5分钟有一条新纪录。多次尝试重建undo没作用,Undo unexpire还是持续上涨, 修改undo_retention为10800(3小时), _highthreshold_undoretention也改为10800,仍然不起作用。 smon在启动后报了报错:
*** 2020-08-11 17:35:57.551
SMON: following errors trapped and ignored:
ORA-01595: error freeing extent (13934) of rollback segment (168))
ORA-00600: internal error code, arguments: [4193], [], [], [], [], [], [], [], [], [], [], []
*** 2020-08-11 17:35:17.268
Exception [type: SIGSEGV, Address not mapped to object] [ADDR:0x505E2AE3] [PC:0x981A396, kgegpa()+40] [flags: 0x0, count: 1]
DDE previous invocation failed before phase II
当出现断电或硬件故障数据库崩溃或者bug等,通常会发生此问题。启动时,数据库先进行正常的前滚(重做),然后再进行回滚(撤消),这是在回滚时生成错误的地方。 根据官方文档:ORA-600 [4193] "seq# mismatch while adding undo record" (Doc ID 39282.1)的描述,在重做记录和回滚记录之间检测到不匹配。
Format: ORA-600 [4193] [a] [b]
VERSIONS:
versions 6.0 to 12.1
DESCRIPTION:
A mismatch has been detected between Redo records and Rollback (Undo)
records.
We are validating the Undo block sequence number in the undo block against
the Redo block sequence number relating to the change being applied.
This error is reported when this validation fails.
ARGUMENTS:
Arg [a] Undo record seq number
Arg [b] Redo record seq number
常规情况,可以通过重建undo来解决,可以参考文档:Step by step to resolve ORA-600 4194 4193 4197 on database crash (Doc ID 1428786.1)
Best practice to create a new undo tablespace.
This method includes segment check.
1. Create pfile from spfile to edit
SQL> Create pfile='/tmp/initsid.ora' from spfile;
2. Shutdown the instance
3. set the following parameters in the pfile /tmp/initsid.ora
undo_management = manual
event = '10513 trace name context forever, level 2'
4. SQL>>startup restrict pfile='/tmp/initsid.ora'
5. SQL>select tablespace_name, status, segment_name from dba_rollback_segs where status != 'OFFLINE';
If all offline then continue to the next step
6. Create new undo tablespace - example
SQL>create undo tablespace <new undo tablespace> datafile <datafile> size 2000M;
7. Drop old undo tablespace
SQL>drop tablespace <old undo tablespace> including contents and datafiles;
8. SQL>shutdown immediate;
9 SQL>startup nomount; --> Using your Original spfile
10. Modify the spfile with the new undo tablespace name
SQL> Alter system set undo_tablespace = '<new tablespace created in step 6>' scope=spfile;
11. SQL>shutdown immediate;
12. SQL>startup; --> Using spfile
二、问题分析
从 Oracle 9i 开始,oracle引入了一种管理前镜像的新方式. 之前的版本这是通过 RollBack Segment 进行的,或称为 manual undo(手动 undo)。 Oracle引入回滚段的目的: 1、事务回滚 2、数据库恢复 3、提供读一致性 4、数据库闪回查询(9i引入) 5、利用闪回特性可以恢复
我来们看下具体的报错,smon具体的报错信息如下:
Incident 698921 created, dump file: /u01/app/oracle/diag/rdbms/dblsshop/dblsshop1/incident/incdir_698921/dblsshop1_smon_39402_i698921.trc
ORA-00600: internal error code, arguments: [4193], [], [], [], [], [], [], [], [], [], [], []
Error 600 in redo application callback
Dump of change vector:
TYP:0 CLS:352 AFN:8 DBA:0x022195de OBJ:4294967295 SCN:0x0432.fc1651cf SEQ:1 OP:5.1 ENC:0 RBL:0
ktudb redo: siz: 80 spc: 8068 flg: 0x0010 seq: 0xeeab rec: 0x02
xid: 0x00a8.01d.03d46b1f --XID
ktubl redo: slt: 29 rci: 0 opc: 5.7 [objn: 0 objd: 0 tsn: 0]
Undo type: Regular undo Begin trans Last buffer split: No
Temp Object: No
Tablespace Undo: No
0x00000000 prev ctl uba: 0x022195de.eeab.01 --uba
prev ctl max cmt scn: 0x040d.a2b82979 prev tx cmt scn: 0x040d.a2b829cc
txn start scn: 0xffff.ffffffff logon user: 0 prev brb: 0 prev bcl: 35097533 BuExt idx: 0 flg2: 0
Block after image is corrupt:
buffer rdba: 0x022195de
scn: 0x0432.fc1651cf seq: 0x01 flg: 0x04 tail: 0x51cf0201
frmt: 0x02 chkval: 0x3745 type: 0x02=KTU UNDO BLOCK
Hex dump of block: st=0, typ_found=1
这里的XID,上面的第七行,表示当前undo block所记录的事务xid,对应V$TRANSACTION.XID信息。
xid: 0x00a8.01d.03d46b1f
0x00a8 --回滚段编号,转换后为168,说明该事务使用的回滚段是第168号回滚段
01d --事务槽编号(slot),转换后为29,说明对应undo segment header中的transaction table记录中的index是29
03d46b1f --序号(同一个事务可能具有多个SCN,用于区分一个事务中的多个操作)
看下trace里的ktuxc的信息,ktuxc的结构在undo segment header中
TRN CTL:: seq: 0xeeab chd: 0x001d ctl: 0x0009 inc: 0x00000000 nfb: 0x0001
mgc: 0xb000 xts: 0x0068 flg: 0x0001 opt: 2147483646 (0x7ffffffe)
uba: 0x022195de.eeab.01 scn: 0x040d.a2b82979
----chd:指向最早提交的事务,ctl:指向最新提交的事务 0x0009,这表示最新commit的Tx table中的记录
Version: 0x01
FREE BLOCK POOL::
uba: 0x022195de.eeab.01 ext: 0x366d spc: 0x1f84
uba: 0x00000000.edc6.27 ext: 0x3588 spc: 0x424
uba: 0x00000000.edb6.13 ext: 0x3578 spc: 0x618
uba: 0x00000000.86eb.08 ext: 0x59e4 spc: 0x1bce
uba: 0x00000000.0000.00 ext: 0x0 spc: 0x0
任何时候,一个事务只能使用一个undo block。当然,在Tx 事务表头(ktuxc)中,没有必要存放整个完整的uba地址,存放undo block的dba地址就足够了。事务用这个来指向最近被使用的undo block、块头包含了一个指针,指向了该事务所创建的的最新undo record记录。之前的记录都保存在同一个block或者在另外一个undo block中。undo chain的最末端是是没有dba地址,rci就是undo chain。
事务回滚的完整流程: 1、首先通过TX table header(ktuxc)找到的uba地址 2、通过Tx table中的uba地址,定位到最新使用的undo block地址 3、根据最新的undo block定位到最新的undo record 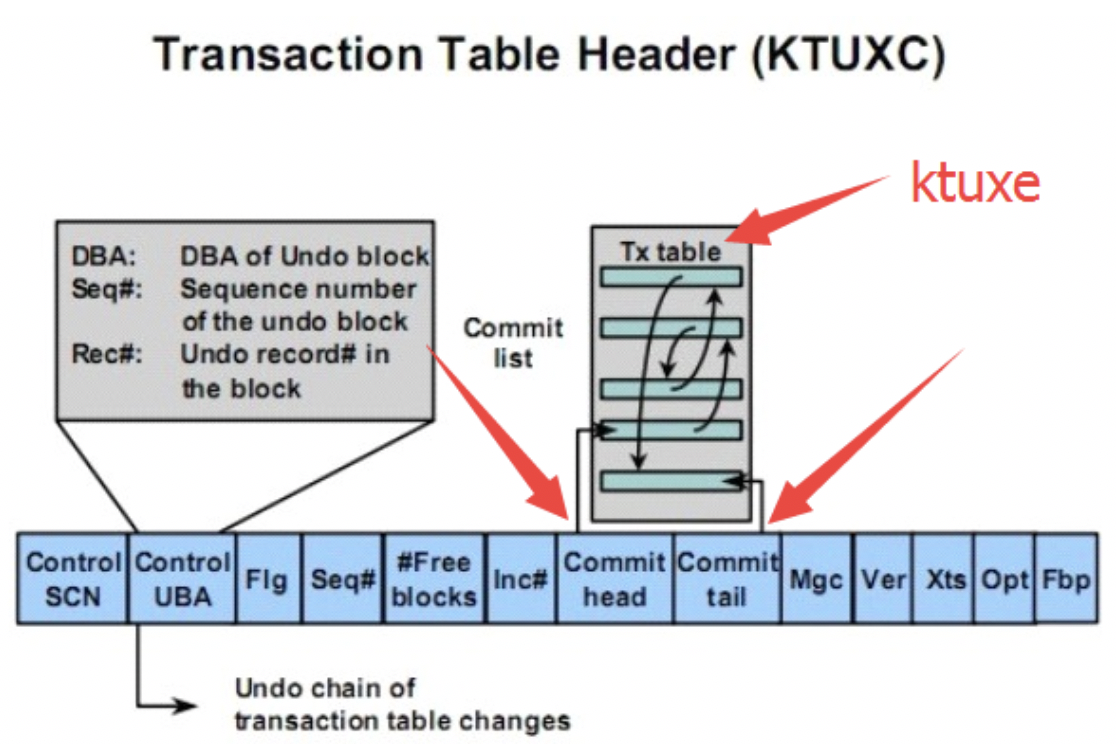
继续看smon的trace
UNDO BLK:
xid: 0x0d6c.005.000005f7 seq: 0xa2 cnt: 0x1 irb: 0x1 icl: 0x0 flg: 0x0000
Rec Offset Rec Offset Rec Offset Rec Offset Rec Offset
---------------------------------------------------------------------------
0x01 0x1f98
*-----------------------------
* Rec #0x1 slt: 0x05 objn: 0(0x00000000) objd: 0 tblspc: 0(0x00000000)
* Layer: 5 (Transaction Undo) opc: 7 rci 0x00
Undo type: Regular undo Begin trans Last buffer split: No
Temp Object: No
Tablespace Undo: No
rdba: 0x00000000Ext idx: 0
flg2: 0
*-----------------------------
uba: 0x022195dd.00a2.01 ctl max scn: 0x0432.fc146142 prv tx scn: 0x0432.fc146cf4
txn start scn: scn: 0x0432.fc1651cf logon user: 104
prev brb: 0 prev bcl: 35658340
kcra_dump_redo_internal: skipped for critical process
Doing block recovery for file 8 block 2201054
Block header before block recovery:
buffer tsn: 8 rdba: 0x022195de (8/2201054)
scn: 0x0432.fc1651cf seq: 0x01 flg: 0x04 tail: 0x51cf0201
frmt: 0x02 chkval: 0x3745 type: 0x02=KTU UNDO BLOCK
Resuming block recovery (PMON) for file 8 block 2201054
Block recovery from logseq 87805, block 8240 to scn 4617027688283
Doing block recovery for file 8 block 2201054,这里数据尝试去恢复这个块,这个块是undo数据 文件的块,也就是,uba:0x022195de.eeab.01对应的回滚段的块。
SQL> /
Enter value for uda: 0x022195de.eeab.01
old 7: from (select '&uda' uba from dual)
new 7: from (select '0x022195de.eeab.01' uba from dual)
UNDO_FILE# UNDO_BLOCK UNDO_SEQUENCE UNDO_RECORD
---------- ---------- ------------- -----------
8 2201054 61099 1
-- uba:第一部分undo block地址,第二部分:seq,第三部分: record
SQL> alter system dump datafile 8 block 2201054
*
ERROR at line 1:
ORA-01410: invalid ROWID --提示无效的rowid
准备将这个块dump出来,发现提示无效的rowid。将这个块从asm到本地,发现无法拷贝。后来了解到,8号数据文件也就是undo数据文件,已经经过多次重建,已经找不到之前的数据块。 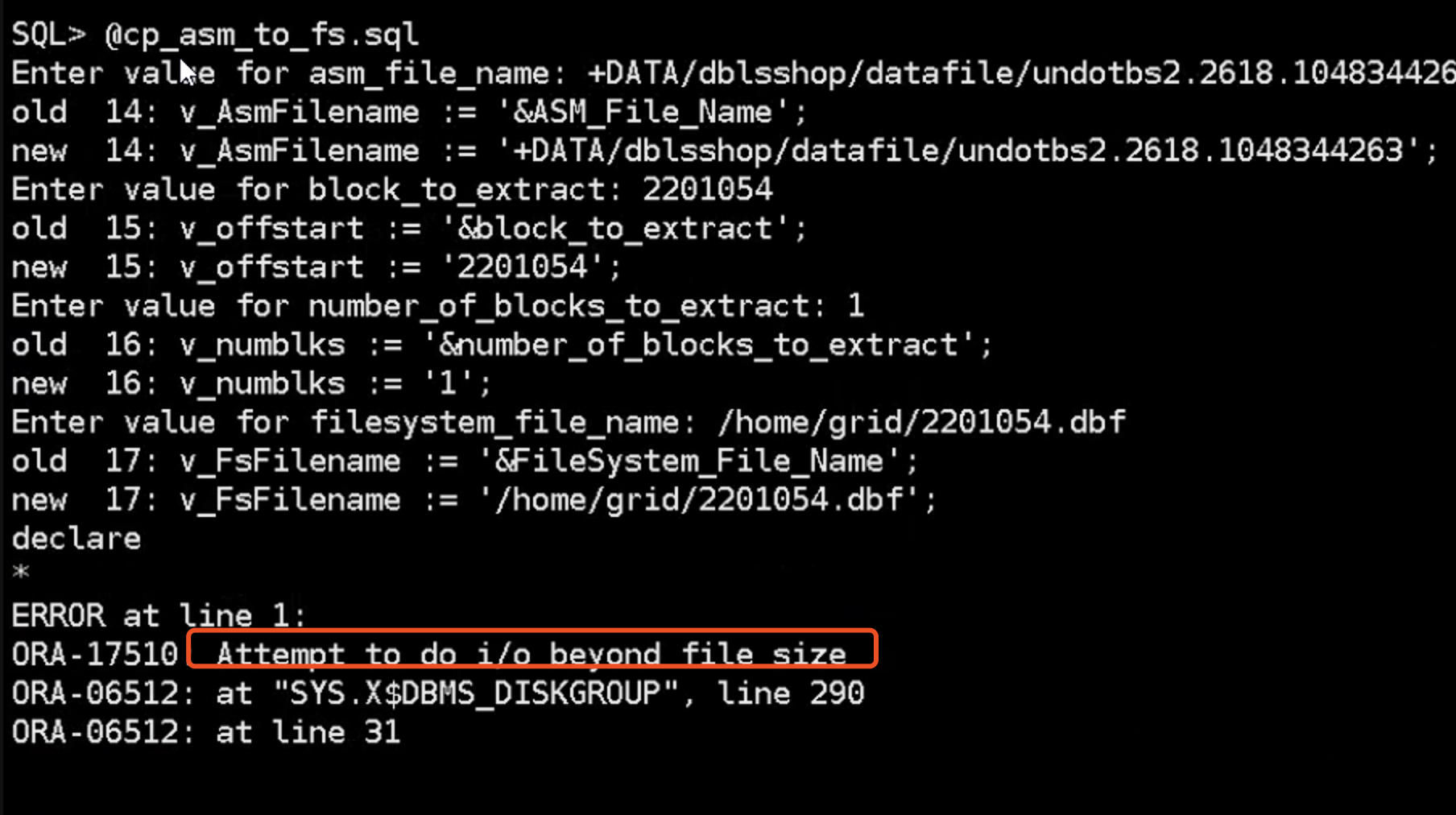
三、解决方法
通过上面的分析,发现通过Tx table中的uba地址,定位到最新使用的undo block地址,这个块根本不存在,多次尝试重建undo没作用。重点来了,那么如何处理? 解决方法: 1、隐含参数*._corrupted_rollback_segments、._offline_rollback_segments。 2、10513 event来禁止smon 进行事务恢复(不一定起作用)。 3、通过bbed修改system回滚段的块,清除free block pool,让oracle认为没有可用的undo block了。
BBED> map
File: /home/oracle/128.dbf (0)
Block: 1 Dba:0x00000000
------------------------------------------------------------
Unlimited Undo Segment Header
struct kcbh, 20 bytes @0
struct ktech, 72 bytes @20
struct ktemh, 16 bytes @92
struct ktetb[8], 64 bytes @108
struct ktuxc, 104 bytes @4148
struct ktuxe[0], 0 bytes @4252
ub4 tailchk @8188
BBED> p ktuxc
struct ktuxc, 104 bytes @4148
struct ktuxcscn, 8 bytes @4148
ub4 kscnbas @4148 0xff5779ed
ub2 kscnwrp @4152 0x0432
struct ktuxcuba, 8 bytes @4156
ub4 kubadba @4156 0x00400225
ub2 kubaseq @4160 0x0226
ub1 kubarec @4162 0x1e
sb2 ktuxcflg @4164 1 (KTUXCFSK)
ub2 ktuxcseq @4166 0x0226
sb2 ktuxcnfb @4168 1 --free block个数,需要改成0
ub4 ktuxcinc @4172 0x00000000
sb2 ktuxcchd @4176 97
sb2 ktuxcctl @4178 68
ub2 ktuxcmgc @4180 0x8002
ub4 ktuxcopt @4188 0x7ffffffe
struct ktuxcfbp[0], 12 bytes @4192
struct ktufbuba, 8 bytes @4192
ub4 kubadba @4192 0x00400225 --也修改为00
ub2 kubaseq @4196 0x0226
ub1 kubarec @4198 0x1e
sb2 ktufbext @4200 6
sb2 ktufbspc @4202 586
system检查没有坏块。 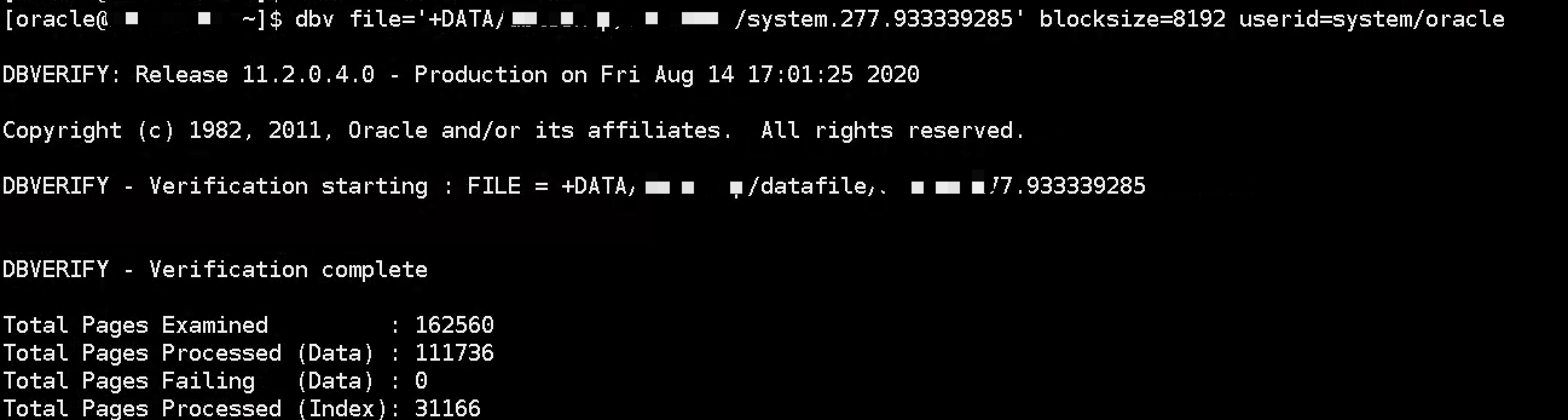
smon的trace不再报错,恢复正常。 
备注:核心生产的system数据块的修改具有一定的危险性,如有问题请及时留言,为您提供快速专业可靠的服务。
本文由 mdnice 多平台发布















 3550
3550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









