







【前言】
Linux的网络层次如图所示:
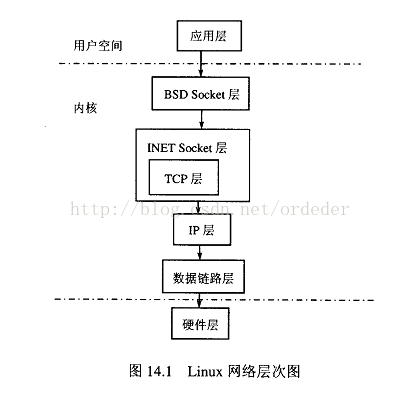
网络的各个层具有严格的限定。其中BSD Socket是UNIX系统中通用的网络接口,它不仅支持各种不同的网络类型,而且也是一种内部进程之间的通信机制。可以将BSD层看做面向用户的通用接口,可以具有不同类型的Family,比如AF_UNIX:域套接字,仅在单台机子上不同进程间的socket通信;AF_INET:网络域套接字,不同机子间的进程通信。网络传输层是在INET Socket及以下开始的。
BSD Socket 和 INET Socket 所维护的socket数据结构和数据存储结构也是不同的。
| Socket数据结构 | 数据报结构 | |
| BSD Socket | Struct socket | Struct msghdr |
| INET Socket | Struct sock | Struct sk_buff |
值得注意的是,
1)BSD Socket 所涉及的报文的读写函数都是采用struct msghdr来描述的。
2)在传输层~数据链路层间的报文都是用Struct sk_buff来描述的。Sk_buff中具有很多指向报文数据部分的各种指针,以便使sk_buff在网络的各层间传递的时候能快速的定位数据:ip报文头指针、tcp/udp报文头指针、数据部分指针等等。
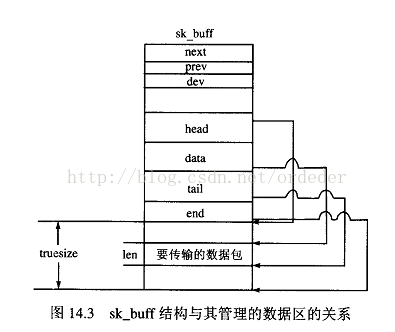
【链路层的数据】
数据链路层(图中的硬件层)的网卡接收数据后,内核调用netif_rx(),netif_receive_skb()接收网络数据包,数据是以sk_buff的结构体进行存储的。该层有一个维护着多个已接收sk_buff组成的队列。当队列非空时,内核通过中断调用ip_rcv()让IP层来提取数据报。
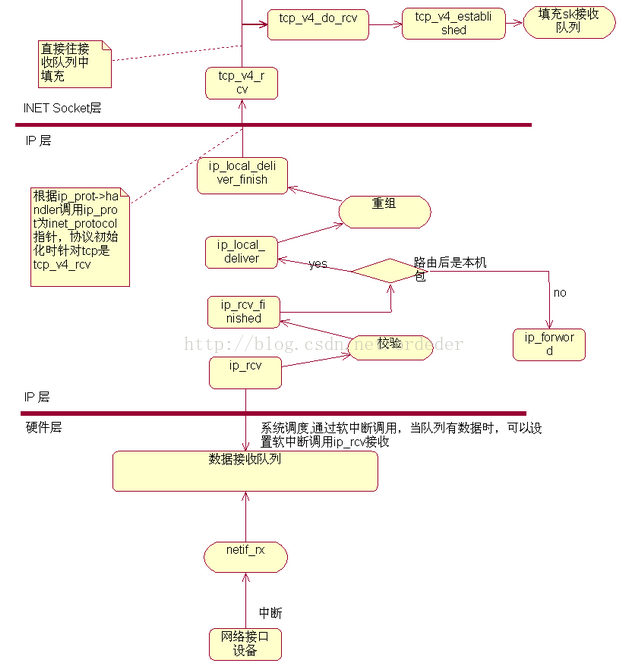
【IP层】
1. ip_rcv()
链路层通过软中断调用IP层的ip_rcv()函数的原型如下:
Skb:链路层数据队列中的某个被选中的报文
Dev:网卡设备
Packet_type:数据包的类型
该函数主要完成一些检查操作:
1)非本机的数据报
这个应该是通过mac地址来判定的,而且是在目标局域网中(数据报到达目标局域网 后,是通过局域网广播的方式将数据发出去,而目标mac地址符合的机子才真正接受 该数据报,其他机子将丢弃之。
2)校验检查
IP版本类型是否符合,IPV4 IPV4
数据报的长度至少有IP头的长度
校验和是否正确
虚假长度(Doesn't have a bogus length?)
::错处的处理IP_INC_STATS_BH(IpInHdrErrors);并丢弃报文
3)如果数据报没有出入,那就调用ip_rcv_finish进入正式的数据报接收。
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt)
{
struct iphdr *iph = skb->nh.iph;
/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/
if (skb->pkt_type == PACKET_OTHERHOST)
goto drop;
IP_INC_STATS_BH(IpInReceives);
if ((skb = skb_share_check(skb, GFP_ATOMIC)) == NULL)
goto out;
/*
* RFC1122: 3.1.2.2 MUST silently discard any IP frame that fails the checksum.
*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* 4. Doesn't have a bogus length
*/
if (skb->len < sizeof(struct iphdr) || skb->len < (iph->ihl<<2))
goto inhdr_error;
if (iph->ihl < 5 || iph->version != 4 || ip_fast_csum((u8 *)iph, iph->ihl) != 0)
goto inhdr_error;
{
__u32 len = ntohs(iph->tot_len);
if (skb->len < len || len < (iph->ihl<<2))
goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
* Note this now means skb->len holds ntohs(iph->tot_len).
*/
__skb_trim(skb, len);
}
return NF_HOOK(PF_INET, NF_IP_PRE_ROUTING, skb, dev, NULL,
ip_rcv_finish);
inhdr_error:
IP_INC_STATS_BH(IpInHdrErrors);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}2.ip_rcv_finish()
参数
Skb:还是前文提到的skb
主要功能
1)调用ip_route_input()函数判定skb路由去向。ip_route_input()包skb查找路由,现在缓冲区的路由hash表中查找,如果没找到,在调用ip_route_input_slow()到路由表中查找。最后设定skb->dst(struct dst_dentry),包括本机出口,其他网段出口。
2)检查包,有问题报错+丢弃
3)调用skb->dst->input(skb)向上层输入包。这个函数根据路由的不同调用了不同的函数(这个在ip_route_input()的时候就设定了的):
ip_local_deliver 向本机上层传送
Ip_forward 路由转发
static inline int ip_rcv_finish(struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
struct iphdr *iph = skb->nh.iph;
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
if (skb->dst == NULL) {
if (ip_route_input(skb, iph->daddr, iph->saddr, iph->tos, dev)) //路由
goto drop;
}
#ifdef CONFIG_NET_CLS_ROUTE
if (skb->dst->tclassid) {
struct ip_rt_acct *st = ip_rt_acct + 256*smp_processor_id();
u32 idx = skb->dst->tclassid;
st[idx&0xFF].o_packets++;
st[idx&0xFF].o_bytes+=skb->len;
st[(idx>>16)&0xFF].i_packets++;
st[(idx>>16)&0xFF].i_bytes+=skb->len;
}
#endif
//IP头部是否大于20B
if (iph->ihl > 5) {
struct ip_options *opt;
/* It looks as overkill, because not all
IP options require packet mangling.
But it is the easiest for now, especially taking
into account that combination of IP options
and running sniffer is extremely rare condition.
--ANK (980813)
*/
skb = skb_cow(skb, skb_headroom(skb));
if (skb == NULL)
return NET_RX_DROP;
iph = skb->nh.iph;
skb->ip_summed = 0;
if (ip_options_compile(NULL, skb))
goto inhdr_error;
opt = &(IPCB(skb)->opt);
if (opt->srr) {
struct in_device *in_dev = in_dev_get(dev);
if (in_dev) {
if (!IN_DEV_SOURCE_ROUTE(in_dev)) {
if (IN_DEV_LOG_MARTIANS(in_dev) && net_ratelimit())
printk(KERN_INFO "source route option %u.%u.%u.%u -> %u.%u.%u.%u\n",
NIPQUAD(iph->saddr), NIPQUAD(iph->daddr));
in_dev_put(in_dev);
goto drop;
}
in_dev_put(in_dev);
}
if (ip_options_rcv_srr(skb))
goto drop;
}
}
return skb->dst->input(skb);//input 指向 ip_forward() || ip_local_deliver,是在ip_route_input()确定
inhdr_error:
IP_INC_STATS_BH(IpInHdrErrors);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}3.ip_local_deliver
1)检查是否要进行数据报重组
http://hi.baidu.com/zengzhaonong/item/96cca415a151c30b8fbde471
(1) 当内核接收到本地的IP包,在传递给上层协议处理之前,先进行碎片重组。IP包片段之间的标识号(id)是相同的。当IP包片偏量(frag_off)第 14位(IP_MF)为1时,表示该IP包有后继片段。片偏量的低13位则为该片段在完整数据包中的偏移量,以8字节为单位。当IP_MF位为0时,表示IP包是最后一块碎片。
(2) 碎片重组由重组队列完成,每一重组队列对应于(daddr, saddr, protocol, id)构成的键值,它们存在于ipq结构构成的散列链之中。重组队列将IP包按照将片段偏量的顺序进行排列,当所有的片段都到齐后,就可以将队列中的包碎片按顺序拼合成一个完整的IP包。
(3) 如果30秒后重组队列内包未到齐,则重组过程失败,重组队列被释放,同时向发送方以ICMP协议通知失败信息。重组队列的内存消耗不得大于256k (sysctl_ipfrag_high_thresh),否则将会调用(ip_evictor)释放每支散列尾端的重组队列。
2)调用上层ip_local_deliver_finish
int ip_local_deliver(struct sk_buff *skb)
{
struct iphdr *iph = skb->nh.iph;
/*
* Reassemble IP fragments.
*/
//IP 碎片包重组
if (iph->frag_off & htons(IP_MF|IP_OFFSET)) {
skb = ip_defrag(skb); //IP包重组
if (!skb)
return 0;
}
return NF_HOOK(PF_INET, NF_IP_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish); /调用上一层函数
}4.ip_local_deliver_finish
更具数据报的传输层协议:UDP||TCP,确定转发函数。
Tcp : tcp_v4_rcv()
至此,链路层的数据通过IP层传入了运输层。
static inline int ip_local_deliver_finish(struct sk_buff *skb)
{
struct iphdr *iph = skb->nh.iph;
#ifdef CONFIG_NETFILTER_DEBUG
nf_debug_ip_local_deliver(skb);
#endif /*CONFIG_NETFILTER_DEBUG*/
/* Point into the IP datagram, just past the header. */
skb->h.raw = skb->nh.raw + iph->ihl*4;
{
/* Note: See raw.c and net/raw.h, RAWV4_HTABLE_SIZE==MAX_INET_PROTOS */
int hash = iph->protocol & (MAX_INET_PROTOS - 1);
struct sock *raw_sk = raw_v4_htable[hash];
struct inet_protocol *ipprot;
int flag;
/* If there maybe a raw socket we must check - if not we
* don't care less
*/
if(raw_sk != NULL)
raw_sk = raw_v4_input(skb, iph, hash);
ipprot = (struct inet_protocol *) inet_protos[hash];
flag = 0;
if(ipprot != NULL) {
if(raw_sk == NULL &&
ipprot->next == NULL &&
ipprot->protocol == iph->protocol) {
int ret;
/* Fast path... */
ret = ipprot->handler(skb, (ntohs(iph->tot_len) -
(iph->ihl * 4)));
return ret;
} else {
flag = ip_run_ipprot(skb, iph, ipprot, (raw_sk != NULL));
}
}
/* All protocols checked.
* If this packet was a broadcast, we may *not* reply to it, since that
* causes (proven, grin) ARP storms and a leakage of memory (i.e. all
* ICMP reply messages get queued up for transmission...)
*/
if(raw_sk != NULL) { /* Shift to last raw user */
raw_rcv(raw_sk, skb);
sock_put(raw_sk);
} else if (!flag) { /* Free and report errors */
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0);
kfree_skb(skb);
}
}
return 0;
}
参考:
http://blog.csdn.net/cz_hyf/article/details/602802?reload
http://hi.baidu.com/zengzhaonong/item/96cca415a151c30b8fbde471















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









