






【背景】
以前一直没出现过jm overuse的情况,今天刚好遇到,记录一下。
【相关知识】
现象:作业频繁重启又自行恢复,陷入循环。
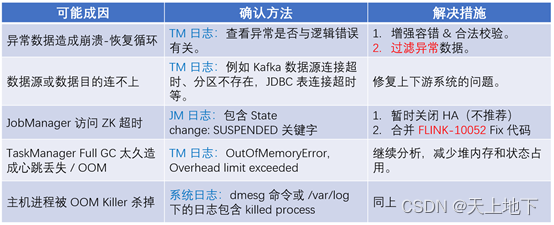
我的还没有那么频繁,但是也基本是几个小时重启一次:

最近一次发现任务在18:21出现了重启
看yarn log,没有明确的报警信息:

可以看到,18:16时还是能正常checkpoint,后面就出现了Shutting down
因此自然而言去看下ck log(checkpoint log),看是不是checkpoint failed了
看到几个error信息:
02-22 18:22:52.058 org.apache.flink.shaded.curator4.org.apache.curator.ConnectionState Authentication failed
02-22 18:21:37.488 org.apache.flink.connector.hbase.source.HBaseRowDataLookupFunction
HBase lookup error, retry times = 0 java.io.InterruptedIOException: null at org.apache.hadoop.hbase.ipc.BlockingRpcCallback.get(BlockingRpcCallback.java:64) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.ipc.AbstractRpcClient.callBlockingMethod(AbstractRpcClient.java:332) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.ipc.AbstractRpcClient.access$200(AbstractRpcClient.java:96) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.ipc.AbstractRpcClient$BlockingRpcChannelImplementation.callBlockingMethod(AbstractRpcClient.java:631) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$BlockingStub.get(ClientProtos.java:37226) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.client.HTable$3.call(HTable.java:855) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.client.HTable$3.call(HTable.java:845) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithRetries(RpcRetryingCaller.java:142) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.client.HTable.get(HTable.java:863) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.hadoop.hbase.client.HTable.get(HTable.java:828) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at org.apache.flink.connector.hbase.source.HBaseRowDataLookupFunction.eval(HBaseRowDataLookupFunction.java:109) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] at LookupFunction$835.flatMap(Unknown Source) ~[?:?] at org.apache.flink.table.runtime.operators.join.lookup.LookupJoinRunner.processElement(LookupJoinRunner.java:81) ~[flink-table-blink_2.11 at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ~[flink-dist_2.11-] at org.apache.flink.streaming.runtime.io.StreamTwoInputProcessor.processInput(StreamTwoInputProcessor.java:96) ~[flink-dist_2.11-] at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:433) ~[flink-dist_2.11- at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204) ~[flink-dist_2.11-] at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:696) ~[flink-dist_2.11] at java.lang.Thread.run(Thread.java:748) [?:1.8.0_252] Caused by: java.lang.InterruptedException at java.lang.Object.wait(Native Method) ~[?:1.8.0_252] at java.lang.Object.wait(Object.java:502) ~[?:1.8.0_252] at org.apache.hadoop.hbase.ipc.BlockingRpcCallback.get(BlockingRpcCallback.java:62) ~[blob_p-f79fbf6978bb30be01b7b52a64827a71b800c03d-e2c9f02092da188242bbe9b17f0637dd:?] ... 46 more
这里看上去是hbase的鉴权问题,但是时间点不对,因为18:21:36就已经失败shutting down了,而18:21:41就重启完成了:

回去继续找yarn log
其实从diagnostics info就可以看到:
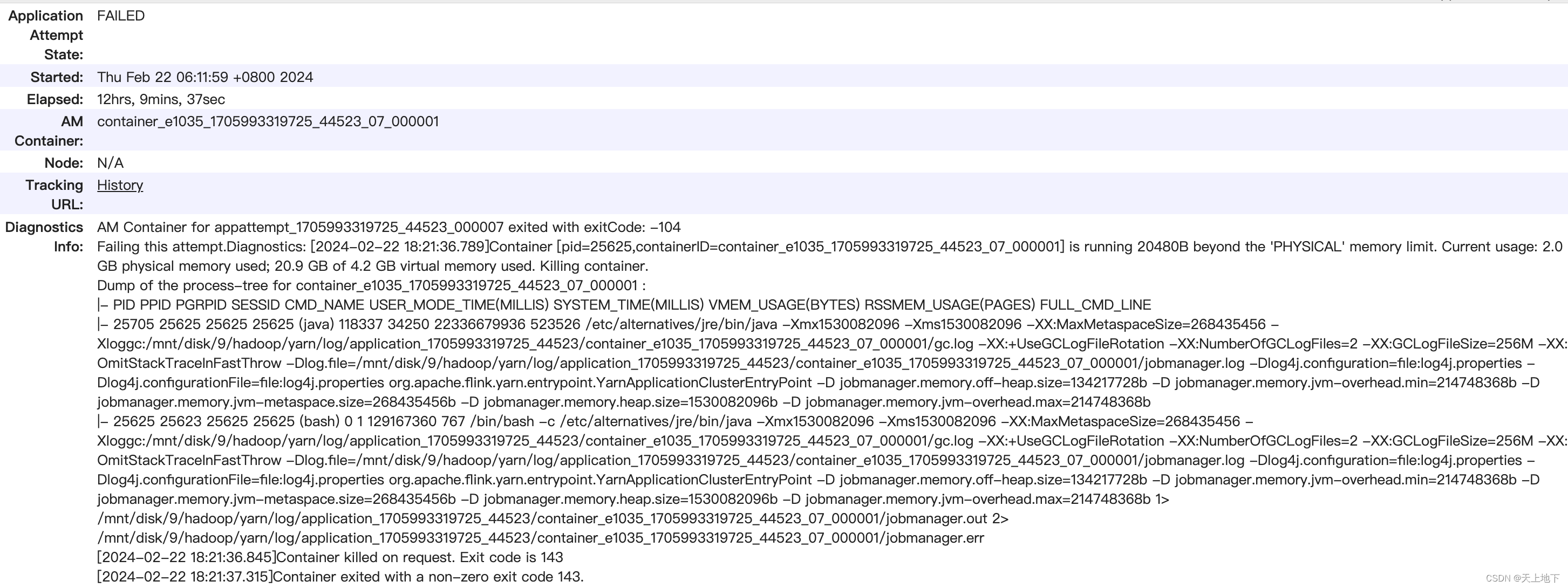
M Container for appattempt_1705993319725_44523_000007 exited with exitCode: -104
Failing this attempt.Diagnostics: [2024-02-22 18:21:36.789]Container [pid=25625,containerID=container_e1035_1705993319725_44523_07_000001] is running 20480B beyond the 'PHYSICAL' memory limit. Current usage: 2.0 GB of 2 GB physical memory used; 20.9 GB of 4.2 GB virtual memory used. Killing container.
原来是jm内存不足(可能是我这个DAG比较大,表也很多,数据量也很多,jm管理有压力)
目前设置的是2G,需要对应增加jm内存
看当时的监控,确实堆内+堆外基本是满的了
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









