






之所以会说 TCP 是面向字节流的协议,UDP 是面向报文的协议,是因为操作系统对TCP 和 UDP 协议的发送机制不同,也就是问题原因在发送方。
UDP为什么面向报文协议?
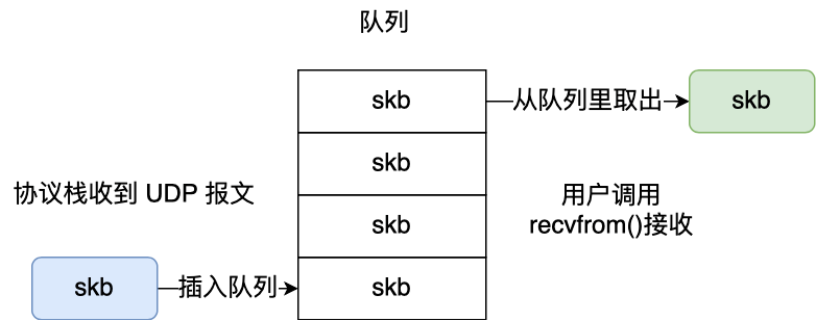
当用户消息通过 UDP 协议传输时,操作系统不会对消息进行拆分,在组装好 UDP 头部后就交给网络层来处理,所以发出去的 UDP报文中的数据部分就是完整的用户消息,也就是每个 UDP 报文就是一个用户消息的边界,这样接收方在接收到 UDP 报文后,读一个 UDP 报文就能读取到完整的用户消息。你可能会问,如果收到了两个 UDP 报文,操作系统是怎么区分开的?操作系统在收到 UDP 报文后,会将其插入到队列里,队列里的每一个元素就是一个UDP 报文,这样当用户调用 recvfrom0 系统调用读数据的时候,就会从队列里取出个数据,然后从内核里拷贝给用户缓冲区。
TCP为什么是面向字节流协议?
当用户消息通过 TCP 协议传输时,消息可能会被操作系统分组成多个的 TCP 报文,也就是一个完整的用户消息被拆分成多个 TCP 报文进行传输。这时,接收方的程序如果不知道发送方发送的消息的长度,也就是不知道消息的边界时,是无法读出一个有效的用户消息的,因为用户消息被拆分成多个 TCP 报文后,并不能像 UDP 那样,一个 UDP 报文就能代表一个完整的用户消息。
举个实际的例子来说明。
发送方准备发送「Hi.」和「l am Xiaolin」这两个消息。在发送端,当我们调用 send 函数完成数据”发送”以后,数据并没有被真正从网络上发送出去,只是从应用程序拷贝到了操作系统内核协议中。至于什么时候真正被发送,取决于发送窗口、拥塞窗口以及当前发送缓冲区的大小等条件。也就是说,我们不能认为每次 send 调用发送的数据,都会作为一个整体完整地消息被发送出去。
如果我们考虑实际网络传输过程中的各种影响,假设发送端陆续调用 send 函数先后发送[Hi.」和[l am Xiaolin」 报文,那么实际的发送很有可能是这几种情况。第一种情况,这两个消息被分到同一个 TCP 报文,像这样:

类似的情况还能举例很多种,这里主要是想说明,我们不知道「Hi.」和「lamXiaolin」 这两个用户消息是如何进行 TCP 分组传输的。
因此,我们不能认为一个用户消息对应一个 TCP 报文,正因为这样,所以 TCP 是面向字节流的协议。
当两个消息的某个部分内容被分到同一个 TCP 报文时,就是我们常说的 TCP 粘包问题,这时接收方不知道消息的边界的话,是无法读出有效的消息。要解决这个问题,要交给应用程序。















 6728
6728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









