







1 Abstract
我们介绍了一个新的语言表示模型BERT,这个名字来自于双向的transformer编码器表示。和最近语言表示的模型不同(ELMo、GPT),BERT是被训练深的双向表示,用的是没有标号的数据,然后再连接左右的上下文信息。因为我们的设计,导致我们训练好的BERT只需要额外的加一个输出层,就可以使得在很多nlp的任务上得到一个不错的结果,比如问答、语言推理,且不需要对任务做一些特别的架构上的改动。
BERT在概念上更加简单,在实验上更加好。他在11个NLP的任务上得到了新的最好的结果。
2 Introduction
语言模型预训练可以有效提升很多自然语言的任务。比如句子层面的任务:获得两个句子之间的关系,词元(token)层面的任务:实体命名。
在使用预训练模型做特征表示的时候一般有两类策略:基于特征的和基于微调的。基于特征的代表作是ELMo,在预训练好的这些表示,它作为一个额外的特征和输入会一起输入模型中。基于微调的方法是GPT,把训练好的模型放在下游任务时,不需要改太多,这个模型预训练好的所有参数会在下游任务上再进行一下微调。这两个方法在预训练中都使用了相同的目标函数,都是使用了一个单向的语言模型。
我们认为当前的技术限制了预训练表征的能力,尤其是微调方法。主要限制是标准语言模型是单向的,这限制了可以在预训练期间使用的体系结构的选择。例如,在 OpenAI GPT 中,作者使用从左到右的架构,其中每个标记只能关注 Transformer 的自我注意层中的先前标记(Vaswani 等人,2017)。这样的限制对于句子级任务来说是次优的,并且在将基于微调的方法应用于标记级任务(例如问答)时可能非常有害,因为在这些任务中,从两个方向结合上下文是至关重要的。
在本文中,我们通过提出BERT:来自变形器的双向编码器表示法来改进基于微调的方法。BERT通过使用受Cloze任务(Taylor, 1953)启发的 “带掩码的语言模型”(MLM)预训练目标,缓解了之前提到的单向性约束。这个带掩码的语言模型随机遮住输入的一些token,其目的是根据上下文信息预测被遮住的原始词汇。与从左到右预训练语言模型不同,MLM目标使表征融合了左、右语境,这使我们能够预训练一个深度的双向transformer。除了带掩码的语言模型,我们还使用了一个 "下一句预测 "任务,共同预训练文本对表征。我们的论文的贡献如下:
(1)展示了双向信息的重要性;
(2)预先训练的表示法减少了对许多工程繁重的特定任务体系结构的需求。BERT是第一个基于微调的表示模型,它在一大套句子级和词元级任务上实现了最先进的性能,表现优于许多特定于任务的体系结构;
(3)BERT的代码。
3 Conclusion
最近由于语言模型的迁移学习而带来的经验改进表明,丰富的、无监督的预训练是许多语言理解系统的组成部分。特别是,这些结果使即使是低资源的任务也能从深度单向架构中受益。我们的主要贡献是将这些发现进一步推广到深度双向体系结构,允许相同的预训练模型成功地处理广泛的NLP任务。
4 Related Work
非监督的基于特征的方法
非监督的基于微调的方法
在有标号的数据上做迁移学习
5 BERT模型
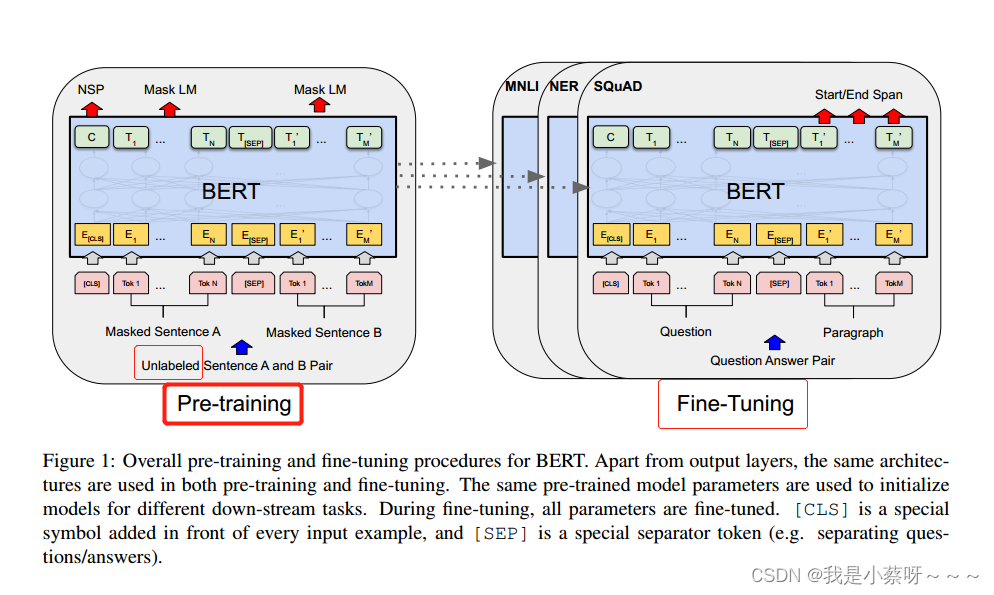
介绍一下BERT的细节。主要有两个工作:预训练和微调。在预训练中,这个模型是在一个没有标号的数据上训练的。在微调时,同样使用一个BERT模型,但其权重初始化时为我们预训练时得到的权重,所用的权重在微调时都会参与训练且用的是有标号的数据。每一个下游任务都会创建一个新的BERT模型,虽然都是用已训练好的模型做初始化,但是对每一个下游任务都会根据自己的数据训练好自己的模型。见图一。
Model Architecture
BERT模型就是一个多层的双向transformer的编码器,直接基于原始的论文和代码。
在本文工作中,调了transformer的个数L,隐藏层大小H,多头自注意力机制的头数A。我们有两个模型:BERT base(L=12, H=768, A=12, Total Parameters=110M) ,BERT(L=24, H=1024,A=16, Total Parameters=340M)。
BERT base和GPT模型的数量差不多,可以做一个比较公平的比较。
Input/Output Representations
对于下游任务,有时输入是一个/一对句子,为了使BERT能够处理这些情况,其输入可以是一个/一对句子。一个句子的意思是一段连续的文字,不一定是真正语义上的一个句子。对于BERT,一个序列有可能是一个/两个句子。
我们使用WordPiece(如果一个词出现的概率不大,那么切开看其子序列,类似词根,子序列出现概率比较大的话,只保留这个子序列)得到一个3w的词典(从而可以表示一个比较大的文本)。这个序列的第一个词永远是一个特殊的记号([CLS]),BERT的最后输出希望是代表一个句子的信息。句子对被打包成一个句子,我们有两个方法来区分:(1)在每一个句子后面放一个特殊的词[SEP];(2)学习一个嵌入层来表示是第一个/第二个句子。见图一。
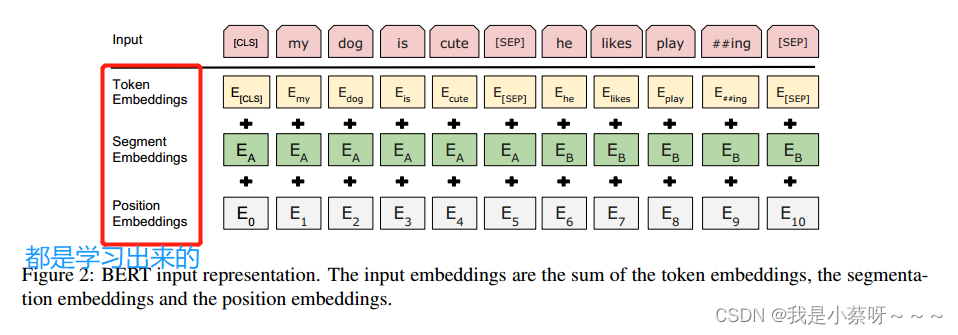
对于每个词元,进入BERT的向量表示为:词元本身的embedding+在哪一个句子的embedding+位置的embedding。见图2。
Pre-training BERT
Task #1:Masked LM
带掩码的语言模型,对于一个token序列,如果每一个token都是由WorkPiece生成,会有15%的概率随机替换成一个掩码。但是对于特殊的词元,就不做替换了。
但是也会有一些问题,因为在做掩码的时候,会把词元替换成一个特殊的token:[mask],在预训练的时候会看到15%的mask,但是在微调的时候没有这个东西,从而导致在预训练和微调时候的数据会有一些不一样。
解决措施:被选中15%的词(1)有80%的概率真的被替换(2)10%的概率被替换成一个随机的词元(3)10%的概率不做改变。

Task #2:Next Sentence Prediction(NSP)
预测下一个句子。
很多重要的下游任务如QA、NLI都是一个句子对,所以需要学一些句子层面的信息。具体来说,我们的输入序列有两个句子A和B,有50%的概率B在原文中间、A之后;50%的概率B是随机从一个地方选取出来的一个句子。(意味着50%为正例,50%为负例)。

Pre-training data
其用了两个数据集,给一些文本(是一片一片的文章,而不是随机打乱的句子)效果会好一些。
Fine-tuning BERT
BERT和一些基于编码器-解码器结构的不同:因为BERT把整个句子对都放进去了,self-attention能够在两端之间互相看,但是encoder-decoder这个架构中,编码器一般是看不到解码器的东西,所以说BERT在这块会好一些,但是不能像transformer一样做机器翻译。
在做下游任务的时候,会根据不同的任务,设计任务相关的输入和输出。具体实验小结。
Experiments
GLUE
句子层面的任务
QA
SWAG
判断两个句子之间的关系
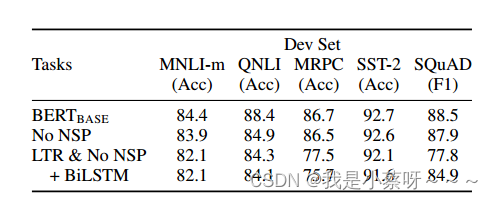
Ablation Studies




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











