







上次试验了一下smartbi的文本挖掘工作流。很简单地词频可视化,初步上手比较顺利。但是从文本中提取词频还有一些技术问题,比如分词。
想要理解句子的含义,词汇是一个最基本的单元。让计算机理解句子也是同样的,首先要对文本进行分词。中文分词比英文分词复杂许多。因为英文单词是用空格隔开的,而中文句子中,词语没有明显的自然分割,所以要划分词汇还得先费一番功夫。
就查找到的资料来说,目前中文分词的方法可以分为三类:基于词典的方法,基于统计的方法,基于语义的方法。
- 基于词典的方法:先建立一个词典,用词典中的词来匹配句子中连续的字,按匹配的结果进行划分。有前向最大匹配、后向最大匹配方法等等。
- 基于统计的方法:统计文本中相邻字出现的频率,频率越高,越有可能是一个词。先划分出所有可能的结果,在运用统计模型来确定最优的划分。机器学习也可以运用到这上面。
- 基于语义的方法:让计算机像人一样通过语义的分析来分词,处理歧义现象。不过由于中文文法复杂,目前还没有很成熟的此类方法。
建模比赛时查到一些分词工具:
- Rwordseg,R语言的package
- ICTCLAS,中科院的收费分词系统
- “结巴”分词,python插件
- MMSEG,源代码可以直接用gcc编译,基本上使用不限平台
- 其他
不过工具嘛,好用就行。记得建模比赛的时候我们打算提取评论中出现的高频词汇作为垃圾评论的特征。这是一个很简单的想法,但比赛时由于技术原因,最后是目测的。当时使用了rwordseg分词包,由于速成R语言太水,只能处理单个句子。
下面试一下smartbi的分词,处理的是李白的诗歌,看看有没有好玩的结论。
打开节点库,看到文本挖掘选项下包含了很多基本节点:
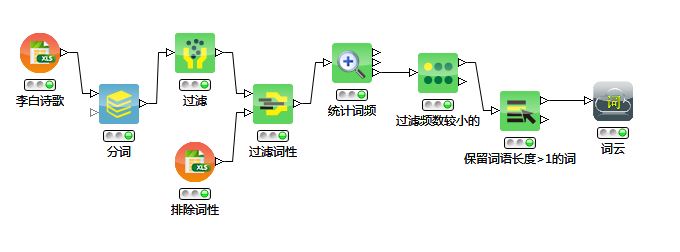
按照思路 -采集数据-对句子进行分词-过滤掉某些字段-统计词频-筛选高频词- 来建立工作流:
获取的词云如下:

在中间的竟然是其一、其二,看来很多题目都写了至少两首嘛。
其次的常用词有黄金、春风、浮云、万里、金陵.
同样的流程,再看看杜甫的:

呃,看来杜甫比较多写绝句。
对比诗歌使用的意象,杜甫更关心朝廷百姓,李白更加豪放不羁。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









