







大家好,我是大飞哥。今天我要分享的是一款声音克隆的软件,通过训练自己的TTS模型库来实现根据自己的音色将文字转化为语音,或者将别人的声音转化为自己的音色声音。在本节课中,我们将重点讲解如何使用这个软件以及各种参数的使用方法。
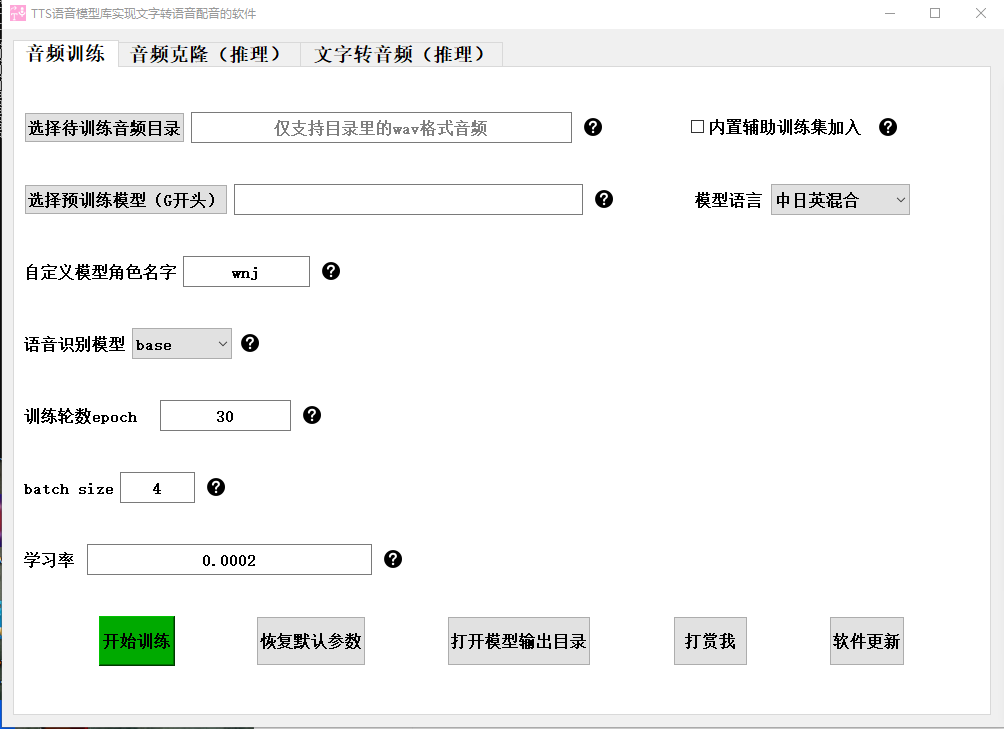
首先,让我们来了解一下TTS(Text-to-Speech)模型库是什么。TTS模型库是一种能够将文字转化为语音的技术,它可以通过训练来模仿人类的语音特征,从而实现准确而自然的语音合成。通过这个软件,我们可以训练自己的TTS模型库,使它能够根据我们的音色,将文字转化为具有我们自己声音特点的语音。
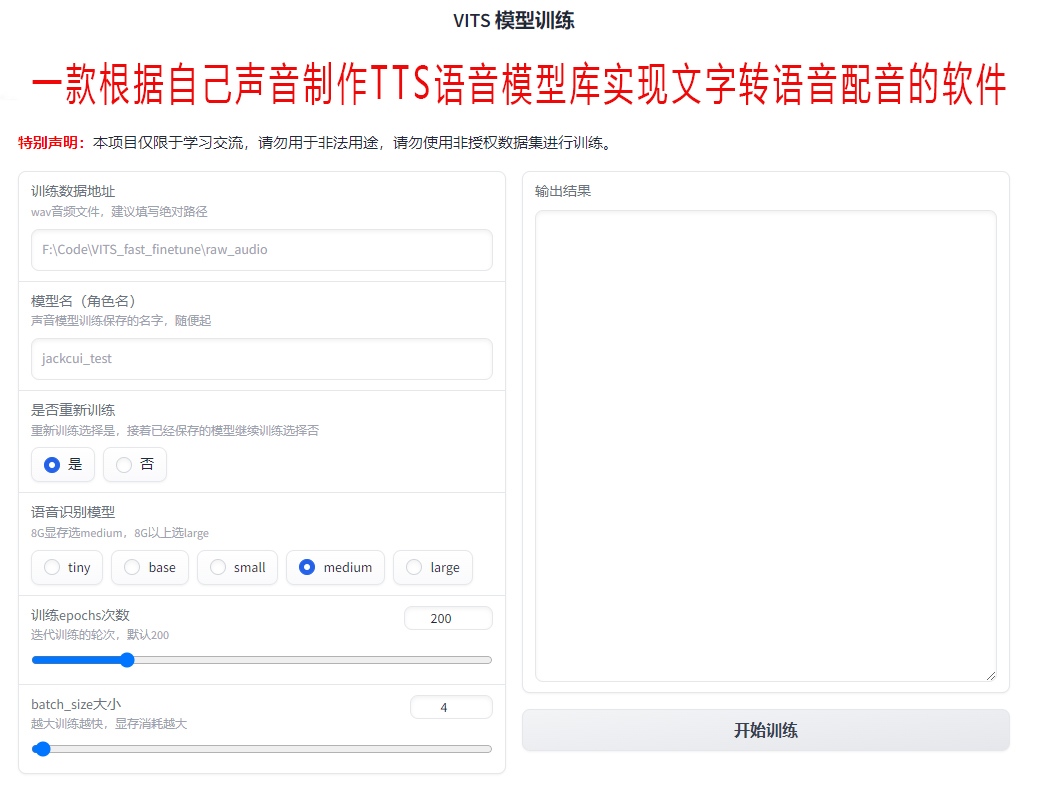
接下来,让我们看一下这个软件的使用方法。首先,我们需要准备一些文本样本,这些文本将会用来训练我们的TTS模型库。可以选择一些短文、新闻报道或者其他感兴趣的内容作为训练文本。然后,通过软件提供的训练功能,我们可以开始训练我们的模型库。在训练过程中,软件会学习我们的音色特征,不断调整模型以适应我们的声音。
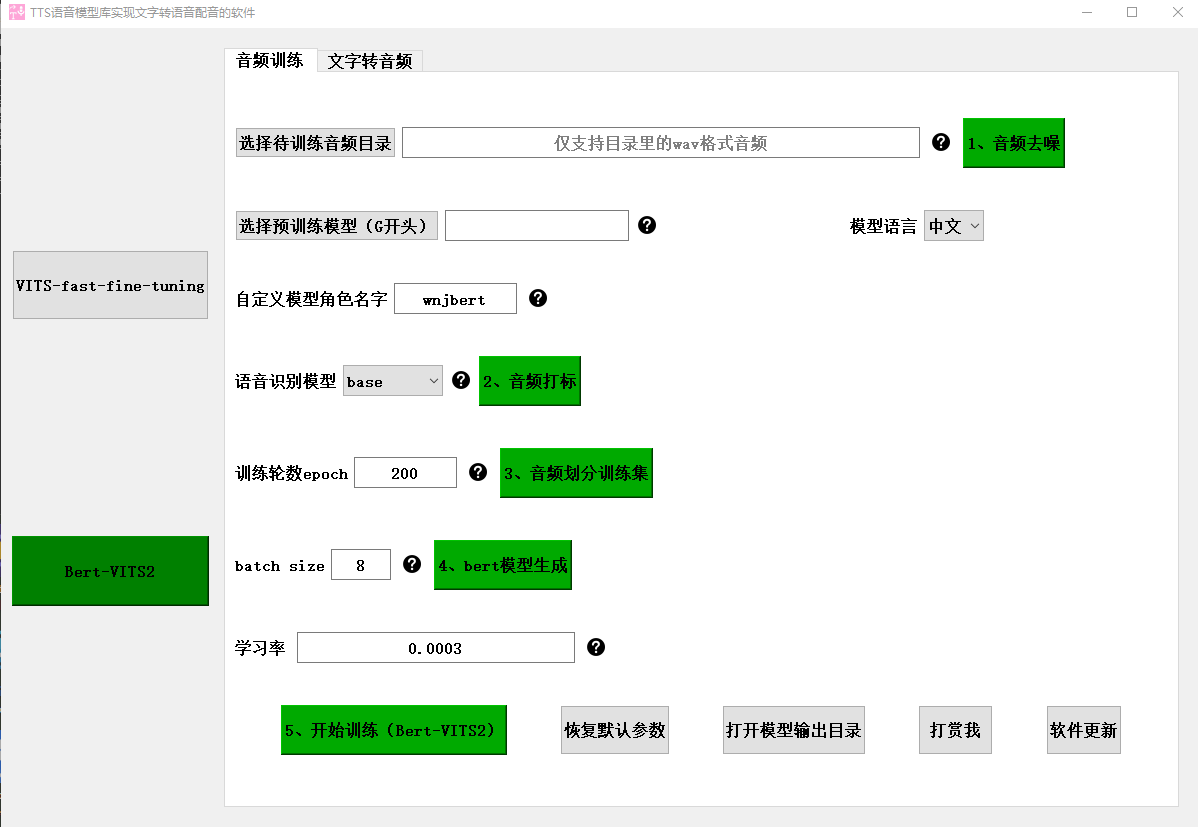
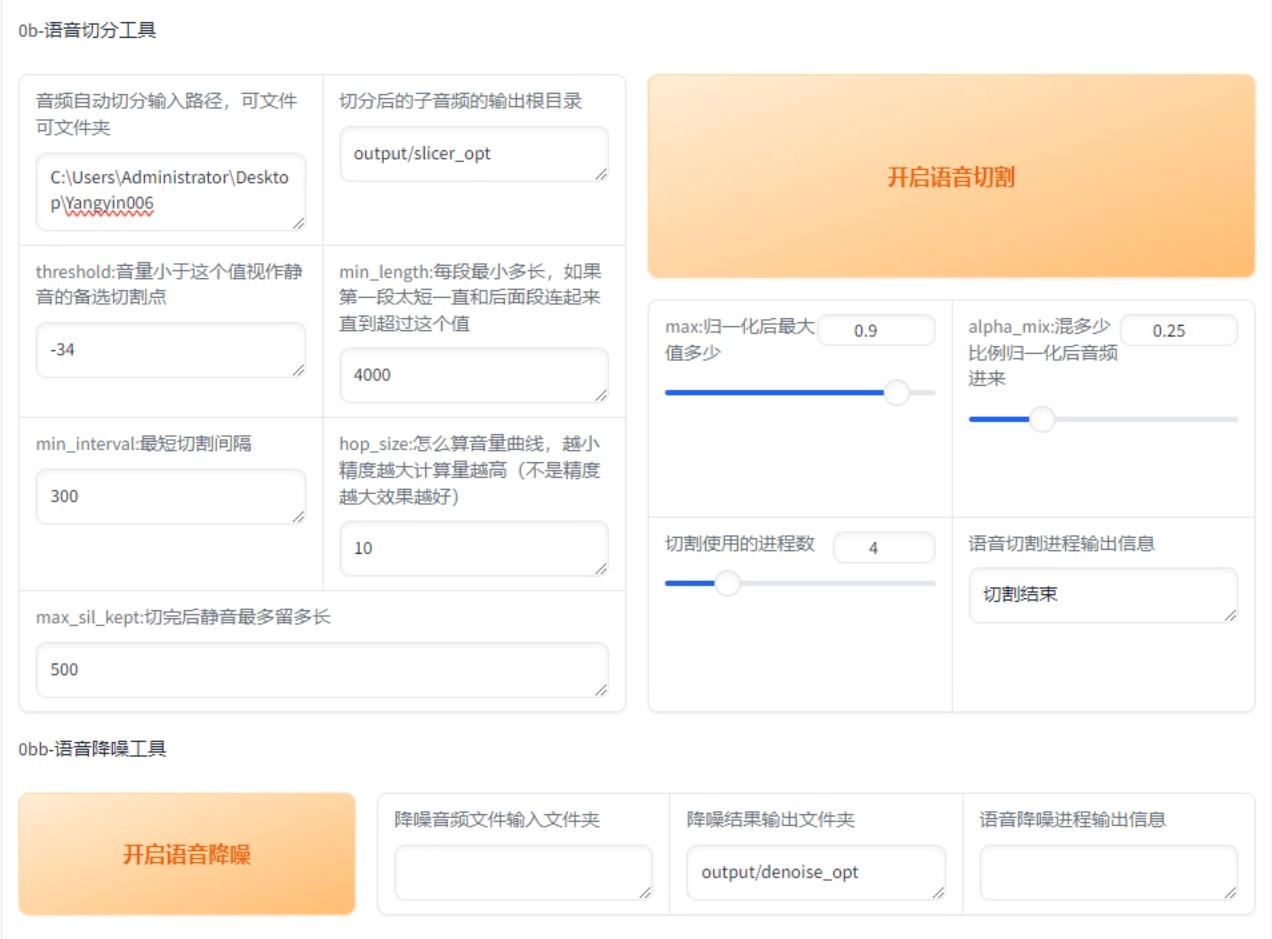
接下来,我们需要告诉软件哪些文件是需要训练的。在软件的设置界面中,找到训练文件的选项。通过勾选对应的文件或者文件夹,告诉软件我们希望使用哪些音频文件进行训练。这一步非常重要,因为它确定了训练的数据来源。
在设置完训练文件后,我们还可以调节训练的次数。一般来说,训练次数越多,模型库的准确性和逼真度越高。然而,过多的训练次数也会增加训练的时间和计算资源的消耗。因此,根据自己的需求和计算能力,选择一个合适的训练次数。
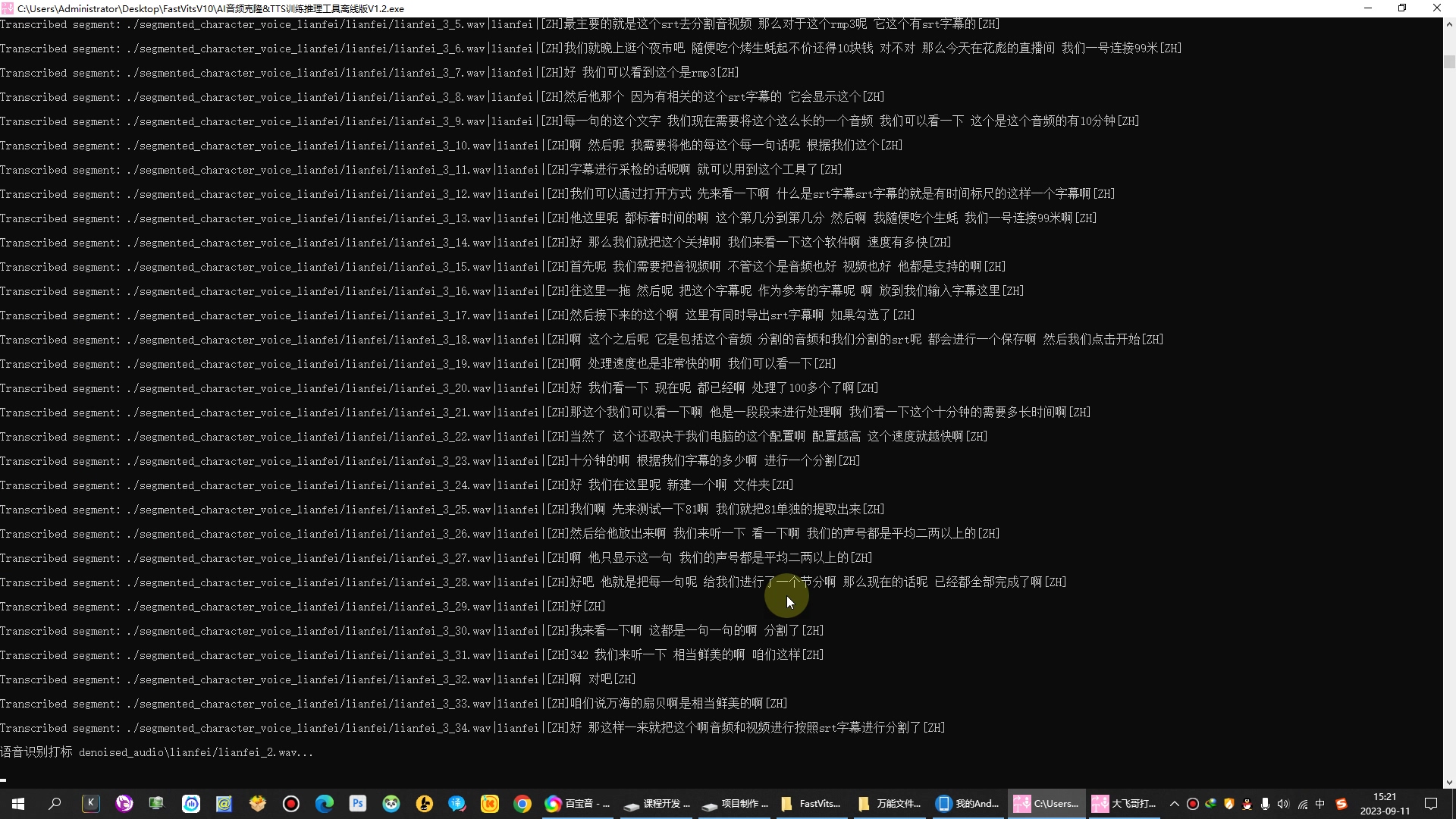
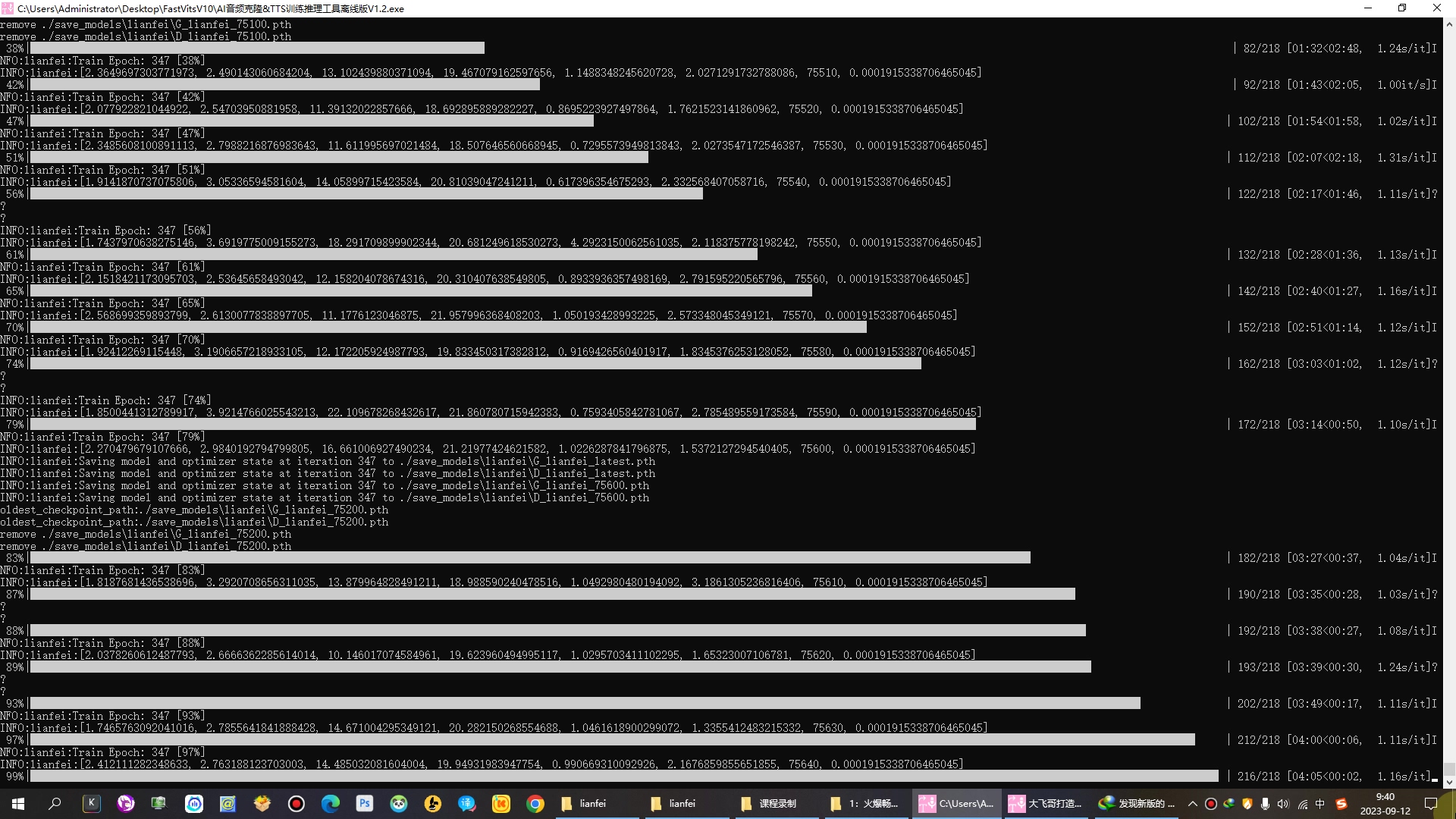
当设置好训练文件和训练次数后,我们只需要点击开始训练按钮,软件就会开始根据我们的音频文件训练TTS模型库了。在训练过程中,软件会不断调整模型以适应我们的声音特征。
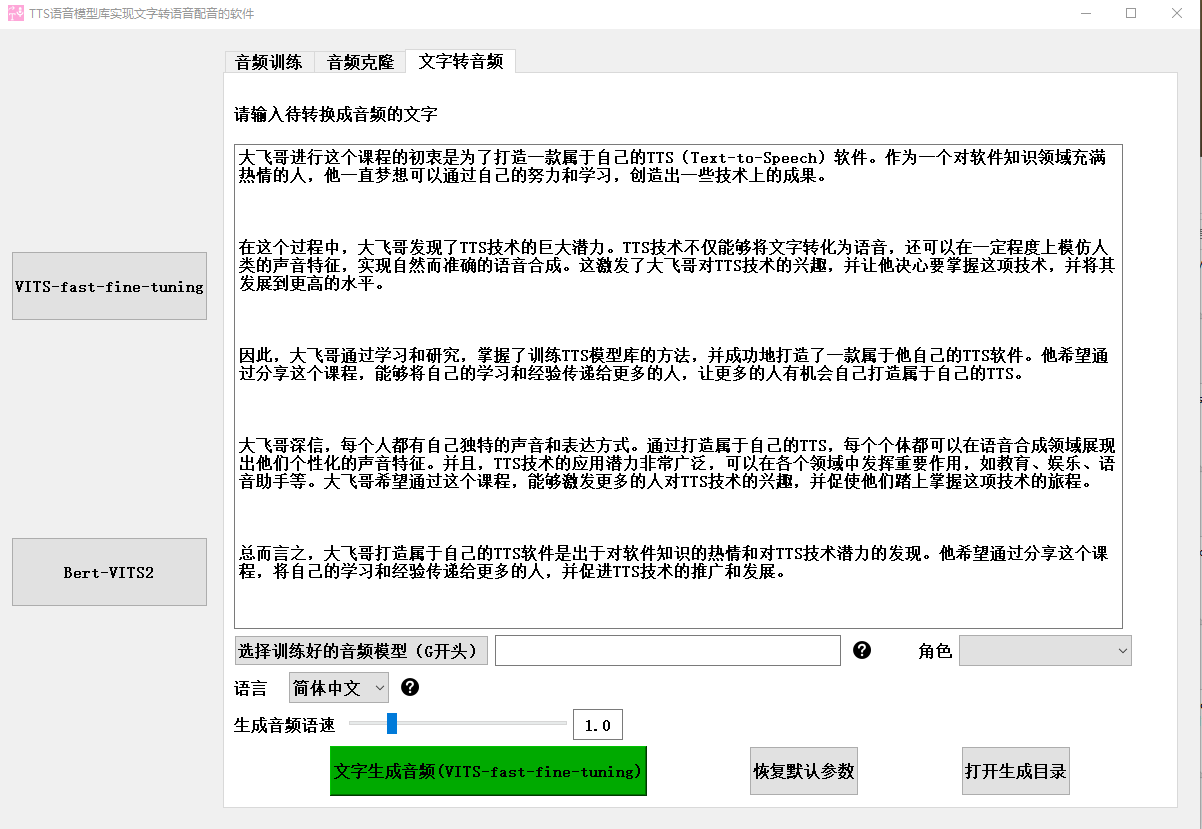
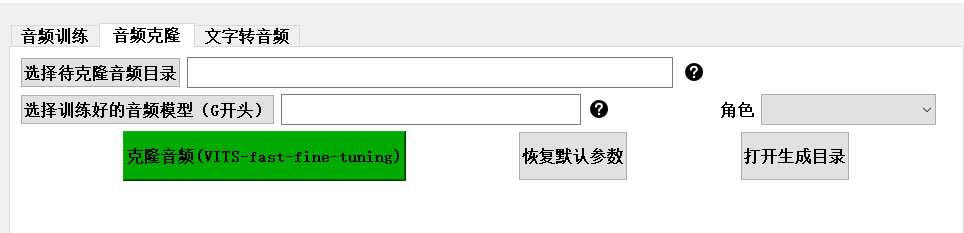
训练完成后,我们可以输入文字来测试我们的TTS模型库。软件会根据我们的音色特征,将文字转化为具有我们自己声音特点的语音。同时,我们也可以使用该软件来克隆别人的声音,通过输入别人的音频样本,软件可以生成与之相似的语音。同时,我们也可以使用该软件来克隆别人的声音。通过输入别人的音频样本,软件可以根据我们的音色特征生成与之相似的语音。

除了训练功能外,这个软件还提供了一些参数供我们调整。我们可以通过调整语速等参数来改变生成语音的效果。通过灵活地调整这些参数,我们可以实现更加个性化的语音合成效果。
提醒:仅支持win10、win11 英伟达显卡(至少需要4G显存)
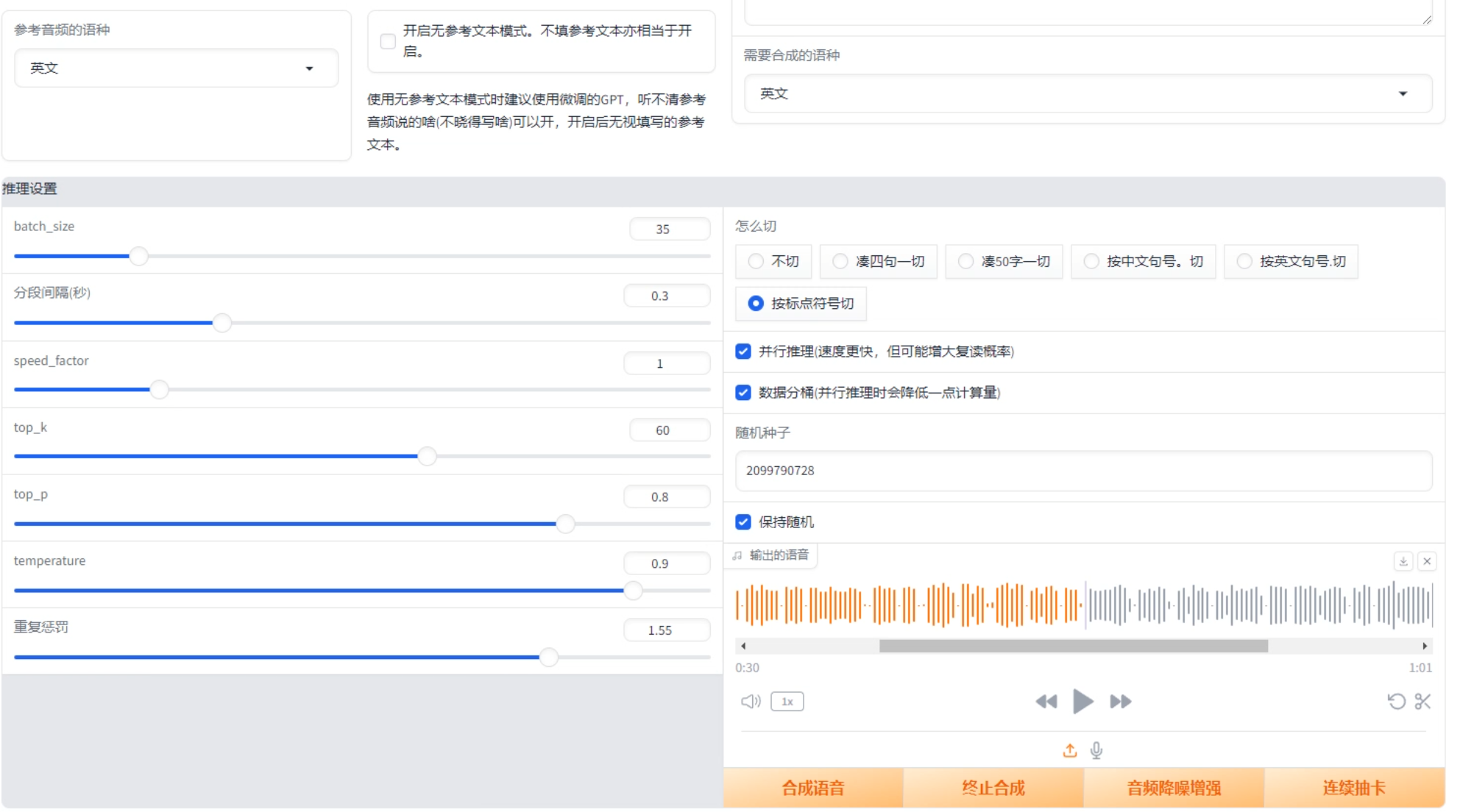
总结一下,本节课中我们学习了如何使用这款声音克隆软件,重点讲解了通过训练自己的TTS模型库来实现根据自己的音色将文字转化为语音,或者将别人的声音转化为自己音色的声音。同时,我们也介绍了软件的训练功能以及各种参数的调整方法。希望这节课程对大家有所帮助,谢谢大家的聆听!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









