







上一篇文中,介绍了IKS使用COS作为跨区域方案,这是一种快捷、方便和高效的方式,性价比也非常高。那如果要追求极致的性能就需要使用专注于Kubernetes平台的企业级存储方案。运行在Kubernetes上的企业应用程序有不可改变的业务需求,如高可用性、数据安全、备份和灾难恢复、严格的性能SLA和混合/多云操作。Portworx企业版正是为这些基于容器应用而设计的。它包含了面向Kubernetes的Portworx存储平台的最可扩展和最健壮的功能,能够为更高级别的数据保护和自动化添加容灾、备份和自动化容量管理。每个集群可扩展到1000个节点和100万个卷。
我们在上一篇文中创建IKS集群时,主机选择了SDS(软件定义存储)的类型,现在我们先了解一下为什么需要SDS。
SDS抽象了各种类型、大小的存储设备,或者来自于附加到集群中的工作节点上的不同厂商的存储设备。在硬盘上有可用存储空间的工作节点作为节点加入存储集群。在这个集群中,物理存储被虚拟化,并作为一个虚拟存储池呈现给用户。存储集群通过SDS软件进行管理。如果数据必须存储在存储集群上,则由SDS软件决定数据的存储位置,以实现最高的可用性。虚拟存储附带了一组通用的功能和服务,用户只需要使用这些功能和服务,而不必关心实际的底层存储架构。使用Kubernetes需要的工作节点类型取决于用户使用的基础设施提供者。如果用户想在IBM Cloud上有一个典型的集群,那么IBM Kubernetes Service可以提供裸金属类型的工作节点,它针对软件定义存储(SDS)的使用进行了优化,在经典集群中,当使用带有10 Gpbs网络速度的SDS工作节点主机时,Portworx能够提供最佳性能。
下来我们在现有的集群来搭建跨区域存储Portworx。

然后,我们可以进入目录或者直接从连接访问Portworx下单页面:https://cloud.ibm.com/catalog/services/portworx-enterprise

第一步我们需要选择区域,由于我的IKS集群建在达拉斯,如果追求最佳的性能,就需要在相同区域创建Portworx。
第二步需要选择套餐,两个都是企业版,不同的是第一个带有DR和IBM Key Protect功能,文本只是测试跨区域存储方案,仅选择企业版。
第三步我们要填入服务名称,比如我这里填写的Portworx Enterprise-den,也可以根据需要选择资源组。

第四步填一下Portworx的集群名,这个名在IKS集群中是唯一的,所以请保证唯一性,比如我在此处填写的是pxden。
第五步我们要填入管理员提供的或者自己的API key,通过下面的方式查看API Key
先进入IAM-用户:https://cloud.ibm.com/iam/users
选择自己的账号

创建新的API Key,复制并妥善保存好。

然后我们还是回到创建Portworx,第六步填入API key,然后会出现“Kubernetes or OpenShift cluster name”这栏,可以选择的现有的IKS集群,目前我只有一个集群,所以会自动填入:

第七步选择Portworx的键值数据库,为了方便测试,我仅选用内建的KVDB。如果是生产环境,建议先在账号下创建"IBM Database for Etcd",然后再创建Portworx时选择Etcd作为键值数据库,具体要求可以通过文档查看:https://cloud.ibm.com/docs/containers?topic=containers-portworx#portworx_database
第八步是指定Portworx的加密方式,可以使用Kubernetes原生的Secret,如果企业对加密有更高要求或者需要符合合规要求,可以使用IBM Key Protect或Hyper Protect Crypto服务,具体信息可以参考文档:https://cloud.ibm.com/docs/openshift?topic=openshift-portworx#encrypt_volumes
第九步,可以考虑是否启用Container Storage Interface(CSI)
最后,点击“创建”开始部署,Portworx集群的部署是由Helm构建的,整个过程需要挺长时间,大概10-15分钟后,我们能看到资源列表中部署完成。

看到“活动”后,我们用kubectl去查看一下部署情况:kubectl get pods -n kube-system | grep 'portworx\|stork'

可以发现部署了portworx和stork,分别是portworx,portworx-api,stork和stork-scheduler,每个组件有3个服务,共12个pods。
然后我们学习下怎么使用pxctl,选择一个portworx pod进去查看当前pod上portworx的状态:kubectl exec portworx-6b45b -it -n kube-system -- /opt/pwx/bin/pxctl status

可以看到状态是“PX is operational”,表示在运行,还有许可证信息。除了当前Pod所在主机的信息和存储位置和大小,还能看到整个存储集群的信息。
如果单独查看集群的信息,可以进pod执行命令:kubectl exec -it portworx-6b45b -n kube-system -- /opt/pwx/bin/pxctl cluster provision-status

既然已经装好Portworx,我们来看下如果使用这个跨区域存储吧。这次我们会集合Stork来使用,Stork是Portworx用于Kubernetes的存储调度程序,它有助于实现Portworx与Kubernetes的更紧密集成,它允许用户将pods与他们的数据放在一起,在存储错误的情况下提供无缝的pods迁移,并使创建和恢复Portworx卷的快照变得更容易。从刚才的部署的pod中可以看到Stork由两个组件组成,Stork调度程序和扩展程序,这两个组件都以HA模式运行,默认情况下有3个副本。
首先我们新建一个yaml文件mysql.ymal,将同时创建PX StorageClass,PVC和一个MySQL deployment,看下yaml构成。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-data
annotations:
volume.beta.kubernetes.io/storage-class: px-mysql-sc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: px-mysql-sc
provisioner: kubernetes.io/portworx-volume
parameters:
repl: "2"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
version: "1"
spec:
schedulerName: stork
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: password
ports:
- containerPort: 3306
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-data上述yaml规范将创建一个加载Portworx PVC的mysql deloyment有两个副本,其中mysql pod将在集群中一个副本所在的节点上调度,如果其中一个节点没有足够的资源,那么将在集群中的其他节点上调度它。为了使用Stork调度器来调度给定的pod,在pod规范中指定调度器的名称"schedulerName: stork"。
然后我们创建这个yaml文件: kubectl create -f mysql.yaml
创建完,我们查看下StorageClass,PVC,deployment和pod。

现在我们了解了如何使用Portworx建StorageClass和PVC来挂载到应用。
Stork除了调度以外,还能实现生成快照和从快照还原,接下来我们演示用Stork来给刚建mysql数据库做快照和还原。
首先我们新建一个snapshot.yaml,内容如下,然后创建:kubectl create -f snapshot.yaml
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: mysql-snapshot
namespace: default
spec:
persistentVolumeClaimName: mysql-data创建后查看下volumesnapshot和volumesnapshotdatas:
kubectl get volumesnapshot
kubectl get volumesnapshotdatas

有可以describe一下连带一起创建的快照数据volumesnapshotdatas:kubectl describe volumesnapshotdatas

由于在创建快照的yaml中指定了"persistentVolumeClaimName: mysql-data",所以在上图中能看到快照对应的PVC是挂在mysql上的PVC:persistentVolumeClaimName: mysql-data,还能看到存储快照的id,位置和时间等信息。
下一步我们做一下从快照恢复,新建一个recover.yaml文件,内容如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-snap-clone
annotations:
snapshot.alpha.kubernetes.io/snapshot: mysql-snapshot
spec:
accessModes:
- ReadWriteOnce
storageClassName: px-mysql-sc
resources:
requests:
storage: 2Gi我们务必要使用annotations,指定snapshot.alpha.kubernetes.io/snapshot为mysql-snapshot,就是刚才创建的snapshot中的name。storageClassName可以用刚才创建的px-mysql-sc,也可以用portworx默认的一些StorageClass。
接着执行命名:kubectl create -f recover.yaml。
然后再次查看PVC,可以看到新的PVC:mysql-snap-clone创建好了。

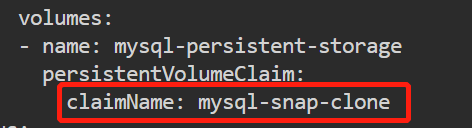
随后我们更新deployment mysql的volumes,执行kubectl edit deploy mysql
pvc把mysql-data替换成mysql-snap-clone并保存,最后再验证一下:kubectl get deploy mysql -oyaml
这样就实现了Stork对数据库存储创建快照和从快照还原的功能,使用Portworx+Stork就是如此简单。















 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









