







独立寒秋,湘江北去,橘子洲头。
看万山红遍,层林尽染;漫江碧透,百舸争流。
鹰击长空,鱼翔浅底,万类霜天竞自由。
怅寥廓,问苍茫大地,谁主沉浮?
携来百侣曾游,忆往昔峥嵘岁月稠。
.......(见结尾).........
大数据项目技术选型主要考虑因素如下:数据量大小、业务需求、行业内经验、技术成熟度、开发维护成本、总成本预算等。石头哥哥给大家罗列除了一些企业里常见的大数据技术选型:
-
数据采集传输:Flume、Kafka、Sqoop、Logstash、DataX
-
数据存储:MySQL、HDFS、HBase、Redis、MongoDB
-
数据计算:Hive、Tez、Spark、Flink、Storm
-
数据查询:Presto、Kylin、Impala、Druid
-
数据可视化:Echarts、Superset、QuickBI、DataV
-
任务调度:Azkaban、Oozie
-
集群监控:Zabbix
-
元数据管理:Atlas
其中最重要的技术选型要从业务需求出发、其次是技术成熟度高的(意思是不能选择最新的,处于孵化过程中的技术框架)、最后是选择行业经验多的(大家都在用,国内外相关技术论坛丰富的框架,出现问题可以能够找到解决方案,遇到的坑可以在网络上快速找到前辈的填坑经验)、开发维护成本也要着重考虑,否则后续coding中经费出现不足也会导致项目风险的增加。
(关注我,定期推送高品质文章)

上面提到了很多框架,可能有些人开始蒙圈了儿,没关系,接下来我们慢慢揭开他们的作用:
数据采集传输:Flume、Kafka、Sqoop、Logstash、DataX
Flume:采集日志
纯离线可以考虑:Flume——>HDFS
如果有实时或者离线和实时并存的需要,可以考虑:Flume——>Kafka——>实时|离线,此时kafka对离线操作来说还可以起到一个数据缓冲的作用。

Sqoop:多用于实现hive数据与mysql之间的数据转存,毕竟用于前端显示还得mysql等关系型数据库读写来的快。
DataX:阿里的一个采集工具,类似Sqoop,比Sqoop更灵活,Sqoop多用在HDFS与关系型数据库比如MySQL、Orcal等,而DataX既可以用在与关系型数据库,也可用在非关系型数据库的交互,比如:MongoDB、Redis等。
Logstash:多用于技术栈ELK中(ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件,稍后给大家详细介绍下ELK),Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
-
为什么用到ELK:
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
-
收集-能够采集多种来源的日志数据
-
传输-能够稳定的把日志数据传输到中央系统
-
存储-如何存储日志数据
-
分析-可以支持 UI 分析
-
警告-能够提供错误报告,监控机制
-

数据存储:MySQL、HDFS、HBase、Redis、MongoDB
MySQL:Hive元数据库存储在MySQL,处理完的报表数据存储在MySQL中,供前端显示,而数据本身多存储在HDFS等分布式文件系统上。
HBase:是一种构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。
-
HBase的特点:
大:一个表可以有上亿行,上百万列。
面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
数据类型单一:HBase中的数据都是字符串,没有类型。
-
HBase 与 HDFS都是存储数据,他们有啥区别呢:
HDFS适合批处理场景
不支持数据随机查找
不适合增量数据处理
不支持数据更新
到此处,是不是你就明白了他们之间的区别了,有点想win电脑下的文件存储与Mysql数据存储之间的关系。
数据计算:Hive、Tez、Spark、Flink、Storm
Hive:基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
-
为什么使用Hive
1.) 直接使用hadoop所面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
2.)操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
Tez:意在构建一个应用框架,能通过复杂任务的DAG来处理数据。它是基于当前的hadoop yarn之上,换句话就是yarn为其提供资源。

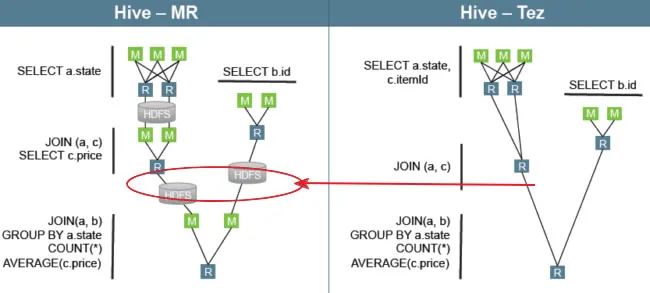
举个栗子:用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,下图中,绿色是Reduce Task,需要将中间结果持久化写到HDFS。
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
Spark vs Flink:Apache Flink是新一代通用大数据处理引擎,旨在统一不同的数据负载。听起来像Apache Spark吗?是的。Flink正试图解决Spark试图解决的同样问题。这两个系统都旨在构建单一平台,可以在其中运行批处理,流媒体,交互式,图形处理,机器学习等。因此,Flink与Spark的意识形态中介没有太大差别。但它们在实施细节方面确实存在很大差异。给大家介绍下两者最明显的区别:
-
Apache Spark将流式处理视为快速批处理。
-
Apache Flink将批处理视为流处理的特殊情况。
这两种方法都具有令人着迷的含义。
Apache Flink提供事件级处理,也称为实时流。它与Storm模型非常相似。
Spark只有不提供事件级粒度的最小批处理(mini-batch)。这种方法被称为近实时。Spark流式处理是更快的批处理,Flink批处理是有限的流处理。

数据查询:Presto、Kylin、Impala、Druid
数据查询,咱们这里指的是即席查询:主要就是SQL
Presto:是一个开源的分布式SQL查询引擎,数据量支持GB到PB字节,只要处理秒级查询的场景。它和mysql和oracle是不同的,不能处理带有事务的数据。基于内存计算,减少了IO,计算更快,支持跨数据源的连接,比如和mysql;它的聚合运算是边读数据边计算,边清理内存,这种处理方式对内存占用不高;但是表连接会产生大量临时数据,处理速度较慢。
Kylin:Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。

Impala:是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。它是一个用C ++和Java编写的开源软件。与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
换句话说,Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。

Druid:是一个专为大型数据集上的高性能切片和OLAP分析而设计的数据库。数据库是一个广泛的定义,一般意义上的定义为“按照数据结构来组织、存储和管理数据的仓库”。我们一般提到的MySQL Oracle之类的关系型数据库,优势是用于OLTP场景下的;Druid Kylin Clickhouse的优势是用于OLAP场景下。Druid最常用作为GUI分析应用程序提供动力的数据存储,或者用作需要快速聚合的高度并发API的后端。Druid的常见应用领域包括:
-
点击流分析
-
网络流量分析
-
服务器指标存储
-
应用性能指标
-
数字营销分析
-
商业智能/OLAP

数据可视化:Echarts、Superset、QuickBI、DataV
可视化展示:第一种公司内部自己开发,第二种使用开源第三方的,比如:Echarts、Superset等。
QuickBI:是阿里云上面向企业和个人提供的高效数据分析及展现服务平台,承载了数据连接、数据处理、数据分析及可视化的能力。
DataV:是阿里云的一款产品,可以轻松实现数据大屏,比如:天猫双11、阿里云城市大脑同款数据可视化应用、智慧城市、智慧交通、安全监控、商业智能等场景,地理飞线、热力分布、地域区块、3D地球等效果。
任务调度:Azkaban、Oozie
Azkaban:任务流调度器,先来说说为什么要使用任务流调度器,
-
一个完整的数据分析系统通常都是由大量任务单元组成:
shell脚本程序,java程序,mapreduce程序、hive脚本等
-
各任务单元之间存在时间先后及前后依赖关系
-
为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
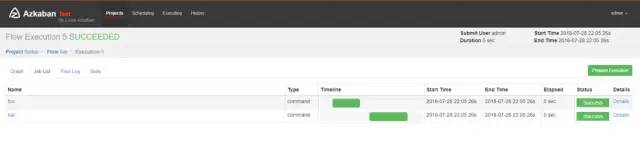
Oozie:也是一款基于Hadoop的任务流调度器,由多个Action组成的有向无环图(DAG)
Azkaban和oozie的区别:两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
如果觉得文章对你有用,动动手指分享一下吧,让更多的人学习更多的知识。奥里给~~~

~~~最近北京大雨来袭,阳光暴晒猛烈夹击,索性不如在家归纳一下技术,希望帮更多的人学习到更多的知识。
恰同学少年,风华正茂;书生意气,挥斥方遒。
指点江山,激扬文字,粪土当年万户侯。














 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









