









ECCV 2022 | MaxViT: Multi-Axis Vision Transformer

主要内容
本文是针对Attention操作的一种改进。思路上来说之前的卷积方法中已经使用过类似的策略,但是作者们将这种思路用在Attention中,也展现出了良好的效果。
提出的结构Multi-Axis Attention有效改善了原始Attention在实际应用中所欠缺的可放缩性,能够更有效的处理高分辨率特征。具体而言,就是通过完全借助局部注意力实现了局部交互和全局交互的形式(全局交互的实现思想其实值得借鉴),在有效降低计算复杂度的情况下,仍然获得了良好的表现。
本文核心关注的是如何有效的将全局和局部交互集成在一起,从而在有限计算资源的情况下,更好的平衡模型容量和泛化能力。
本文实际上有两篇在设计上非常相关的Transformer的工作,即:
- Maxim: Multi-axis mlp for image processing
- Improved transformer for high-resolution gans
在核心模块的设计上本文主要是使用了串行结构,而这两篇是并行结构。串行结构更加简洁和灵活的特性,串行结构中的模块可以很方便的拿出来作为独立的解耦股,或者按照其他的顺序进行组合,而并行的结构则无法很便捷的享受这样的优点。
Multi-Axis Attention

提出的结构的设计以Coat中pre-normalized relative self-attention作为计算中涉及到的self-attention操作。
提出的结构应用multi-axis方法,简单拆解空间轴,从而将全尺寸的注意力拆解为两种稀疏的形式,即局部和全局。
具体流程如下:
- Block Attention:将输入分成不重叠的局部块,CxHxW -> Cx(H/PxW/P)x(PxP)。在局部空间PxP上执行自注意力操作,从而实现了局部交互。计算后恢复原始的形状。这里的超参数是P。
- Grid Attention:将输入按照全局扩张的形式聚合城不同的局部块,即CxHxW -> Cx(GxG)x(H/GxW/G)。在对应着全局的局部空间H/GxW/G上执行自注意力操作,从而间接地实现了全局交互。计算后恢复原始形状。这里的超参数是G。
实际结构中,作者们延续了Swin的形式,选择P=G=7。这样的设计每次的Attention计算都是局部的,实现了线性的复杂度。
这里提出的multi-axis attention,实现起来很容易,交换坐标轴就行。这一思路与shufflenet的操作非常相似。
相较于Swin,有着相同的计算量(相同大小窗口的局部Attention),但是这里全局交互从概念上、实现上都更加简单,不再需要使用padding、循环移位等操作。
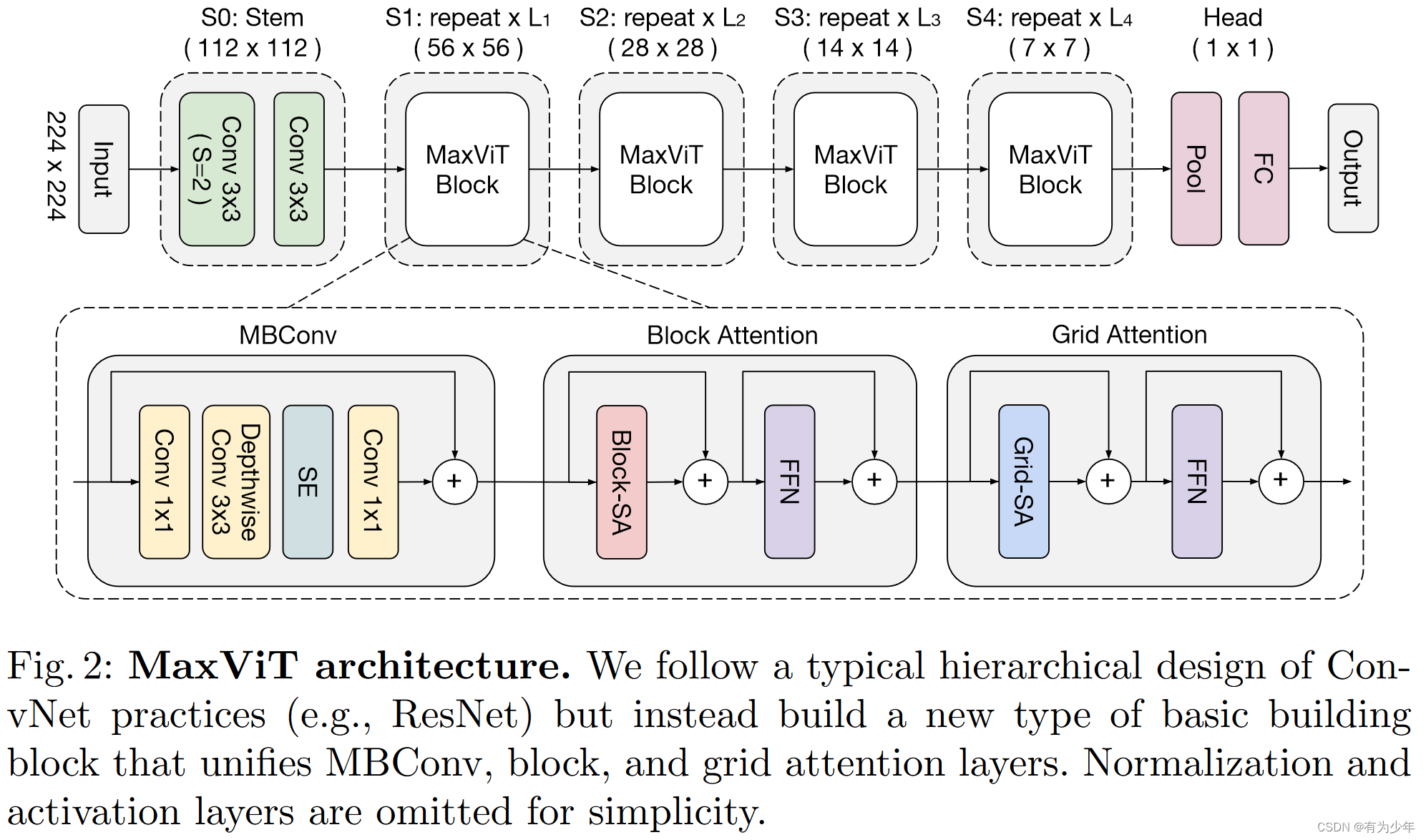
MaxViT Block
基于提出的multi-axis attention和现有的带SE Block的MBConv Block得到了模型的基本构建组件MaxViT Block。这里的attention和MBConv Block都使用pre-norm形式。
MBConv被放到注意力层之前,其本身可以增加模型的泛化性和可训练性,同时其中的深度卷积也可以被看作是一种条件位置编码(CPE),从而使得模型最终不再需要额外的显式的位置编码层,但是模型本身会使用相对位置嵌入。
这里顺序排列的block attention和grid attention具有良好的可拔插性。既可以一起使用,也可以独立使用分别用于局部交互和全局交互。
对比实验

- 最终的模型使用了重叠的3x3卷积实现了stem,这里下采样2被倍,之后分别跟了四个独立的阶段。其中每个阶段都由MaxViT Block构成。每个阶段都在各自的第一个MBConv中使用3x3的深度卷积实现2倍下采样,其中的shortcut branch也会同时应用池化层和通道调整。每个阶段通道数量也会扩张为两倍。
- 分类头是基于全局平均池化层的。
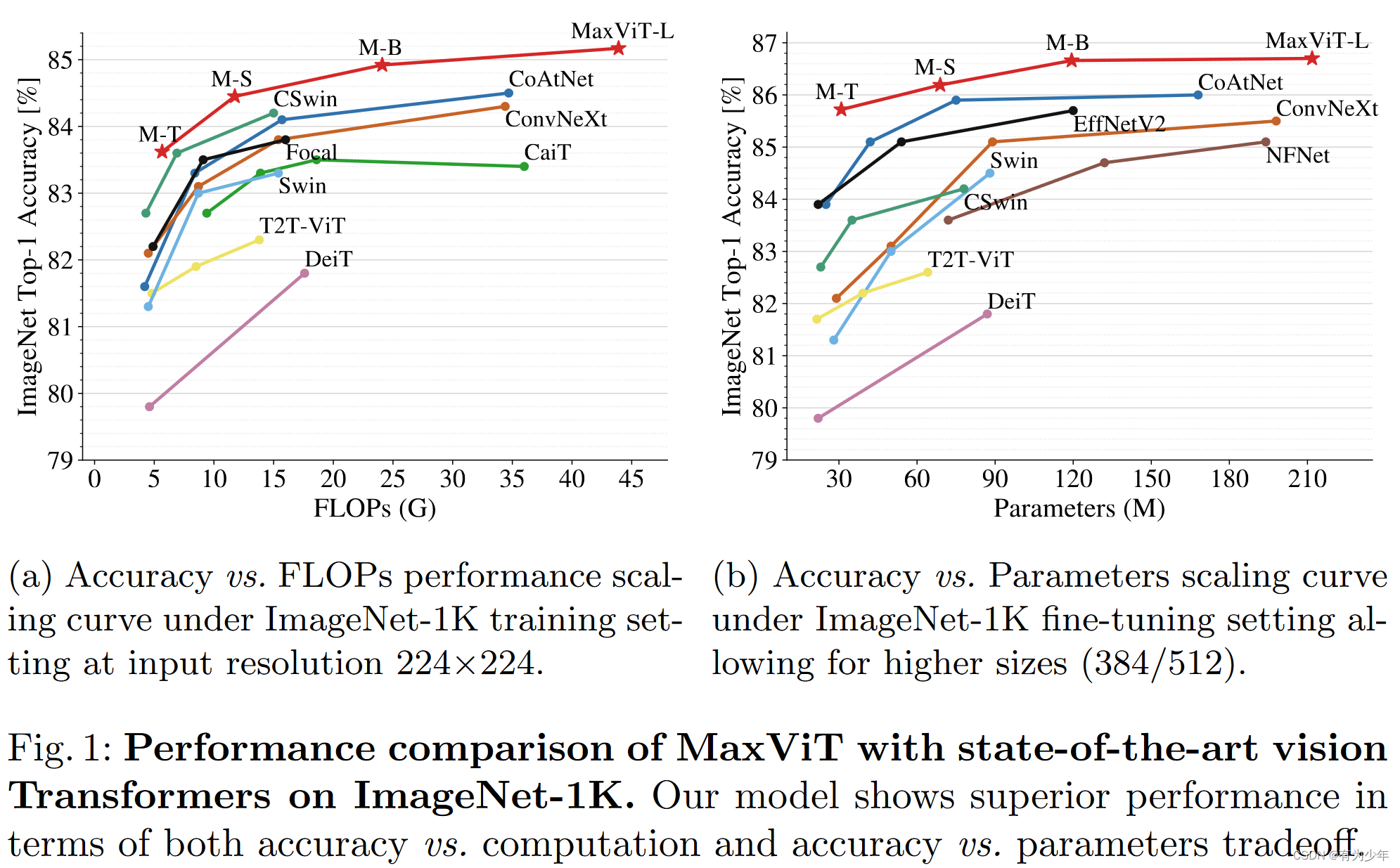
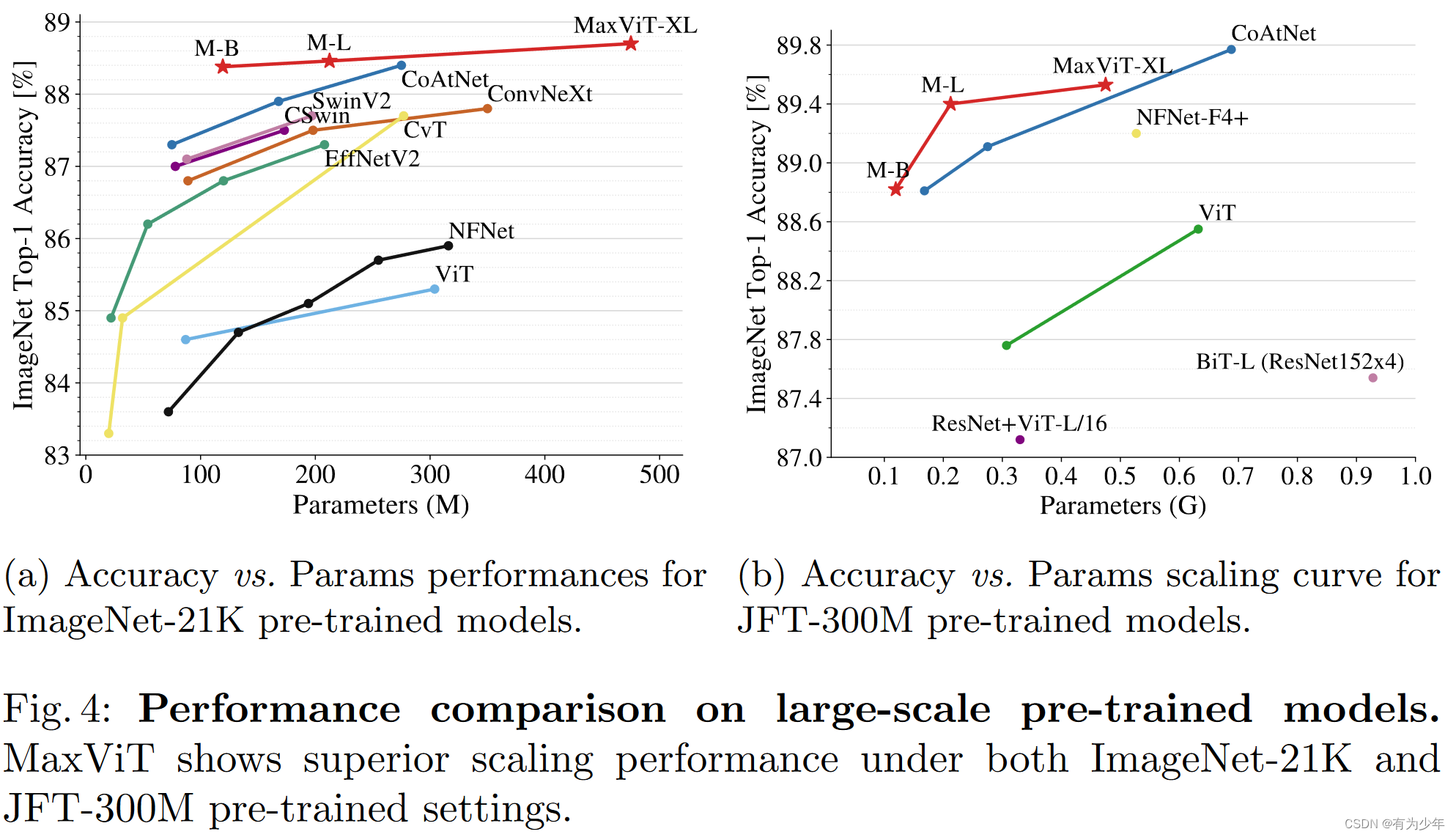
这里的实验中除了传统的分类、检测和分割,比较有意思的是还扩展了图像美学评估Image Aesthetic Assessment和图像生成Image Generation两个比较特殊的任务。都展现出了良好的效果。
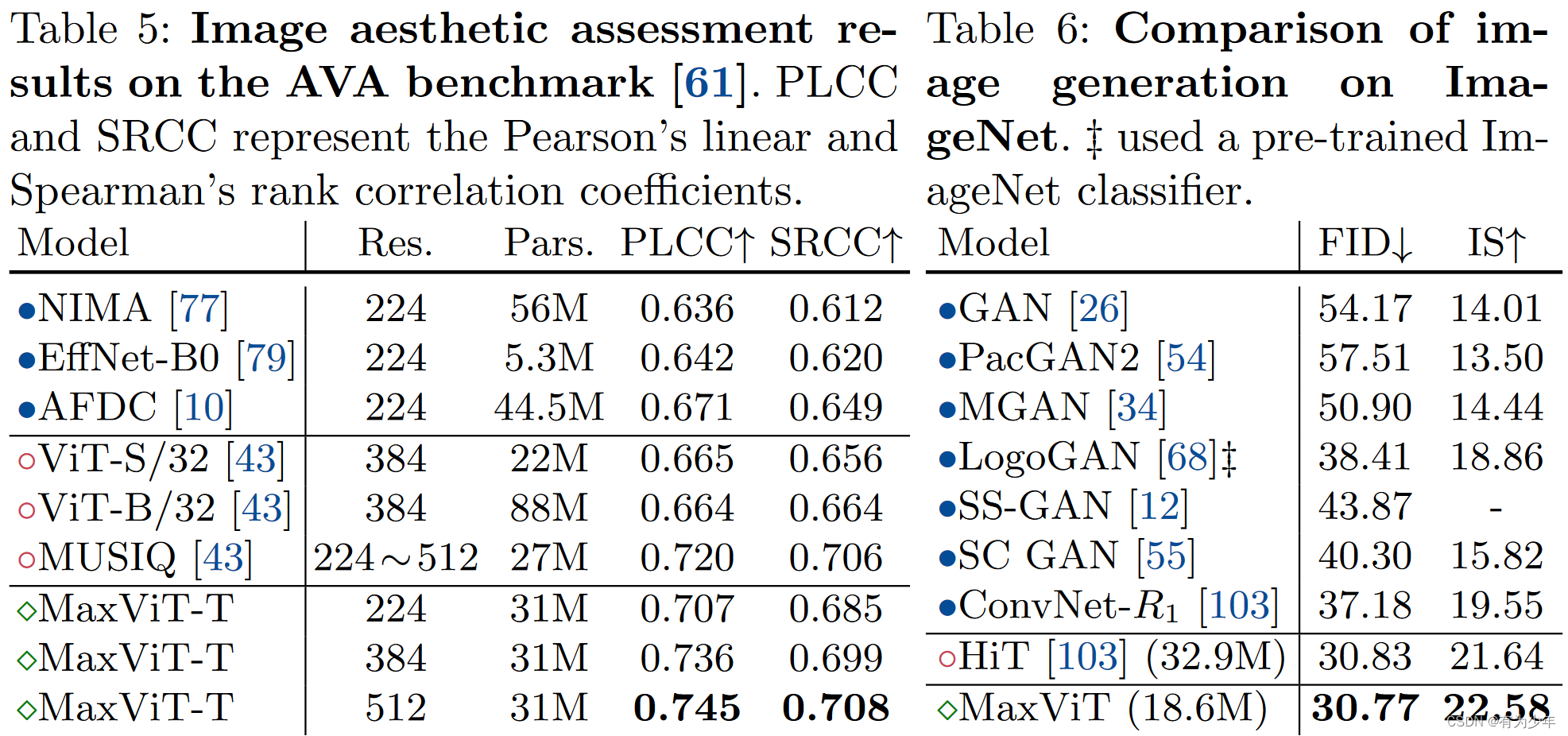
 对于图像生成,结构使用时有所调整。
对于图像生成,结构使用时有所调整。
- MaxViT Block中使用了和原始模型相反的排列顺序,即Grid Attn->Block Attn->MBConv。
- 由于BN在图像生成中展现出了更好的效果,所以在结构中使用BN替换了LN。
消融实验
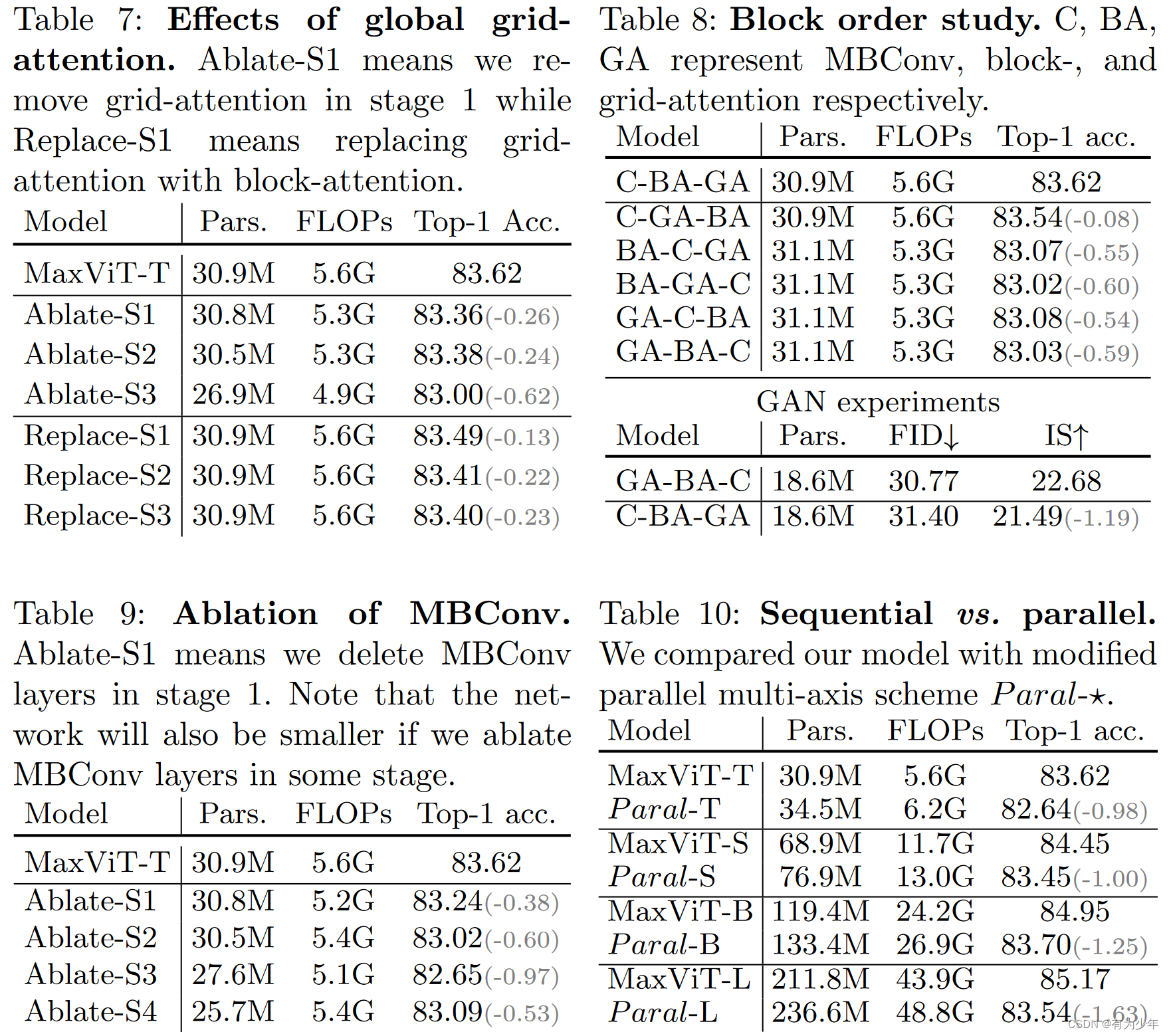
对Global Grid Attention的试验里,作者们发现,早期的全局注意力的存在,相较于只使用局部注意力或者卷积来说,可以进一步提升性能。
实验中也消融了模块内子结构的顺序:
- 在分类任务中,卷积结构放在前面有着更好的表现,作者们认为这应该是这种结构在早期层中更加适合去捕获局部特征或模式,然后全局集成,这和现有的混合结构也是类似的,他们都在注意力之前放置的卷积层。
- 生成模型的实验中,却发现最好的是GA-BA-C结构。作者们假设这可能是因为生成任务首先需要使用grid attention获得完整的结构,然后再使用mbconv填充细节信息。
作者们也对比了串行结构和并行结构。最终的结果时串行效果更好,作者觉得可能是因为并行结构缺少了二者之间的交互,因而串行结构可以学习到局部和全局操作之间更强力的融合形式。
在将本文的注意力MA与Axial Attention(AA)的比较中,主要强调了这样的差异:
- AA使用了基于单轴的注意力操作,先列后行。这实现了全局感受野。实现了N的3/2次方的复杂度,N为像素数量。
- MA首先使用局部注意力,之后是稀疏的全局注意力,这只使用关于像素数量N的线性复杂度。而且,提出的MA是一种对视觉任务更加自然的选择,因为这种设计考虑了图像的二维结构。

伪代码
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









