








大模型已经成为人工智能领域的前沿核心。当下,模型规模正以前所未有的速度膨胀,新的模型架构与算法如雨后春笋般不断涌现,集群规模和训练数据也随之不断增长,它们为人工智能的发展注入了源源不断的强劲动力。然而,这一蓬勃发展的态势也对分布式训练技术提出了更为严苛的要求,促使着相关技术不断迭代升级,以适应日益复杂与庞大的模型训练需求。
为了高效地进行大模型训练,业界通常采用多维混合并行训练技术,涉及数据并行、张量并行、流水线并行、分组切片并行、序列分片并行和专家并行等多种并行策略的不同组合。然而,多维混合并行方案的开发过程往往很复杂,开发者需要面对一系列精细且相互关联的挑战:
- 张量切分难度高:开发者必须显式处理张量切分策略(如张量并行维度的矩阵分块),并深入理解整个模型中各算子的依赖关系,以确保切分的正确性。
- 通信策略需精细调优:开发者需要设计高效的通信策略,这包括决定何时通信、通信的方式(如点对点、广播、归约等)以及如何处理通信中的同步问题。错误的通信策略可能导致数据不一致、死锁或性能严重下降。
- 计算与通信协调难度大:计算和通信往往是交织进行的。开发者需要确保计算任务在通信完成之前不会因等待数据而阻塞,同时也要避免通信任务在计算任务完成之前过早启动而浪费资源。
- 代码可维护性差:底层并行逻辑需大量手写代码,显著增加调试难度。复杂依赖关系使代码如蛛网般难以维护,后续优化迭代成本呈指数级增长。
针对这些挑战,飞桨框架3.0提出了动静统一自动并行技术,通过原生动态图的编程界面与自动并行能力,保障了灵活性、易用性,大幅降低了大模型分布式训练的开发成本;同时,利用框架动静统一的优势,一键转静使用静态优化能力,提供极致的大模型并行训练性能。具体来说,自动并行引入统一的分布式张量表示,用户仅需通过轻量级 API 进行张量切分标记,框架即可自动推导出所有张量和算子的分布式切分状态、并插入高效的通信算子,实现不同的分布式并行策略。

在飞桨框架3.0架构中,自动并行是核心特性之一
使用自动并行后,在简单的情况下,开发者仅需3行代码(声明拓扑→切分张量→分布式运行),即可实现分布式训练。例如,只需要在单卡程序中加入第4、7、17这3行代码即可实现数据并行训练,不需要自己考虑通信的逻辑:
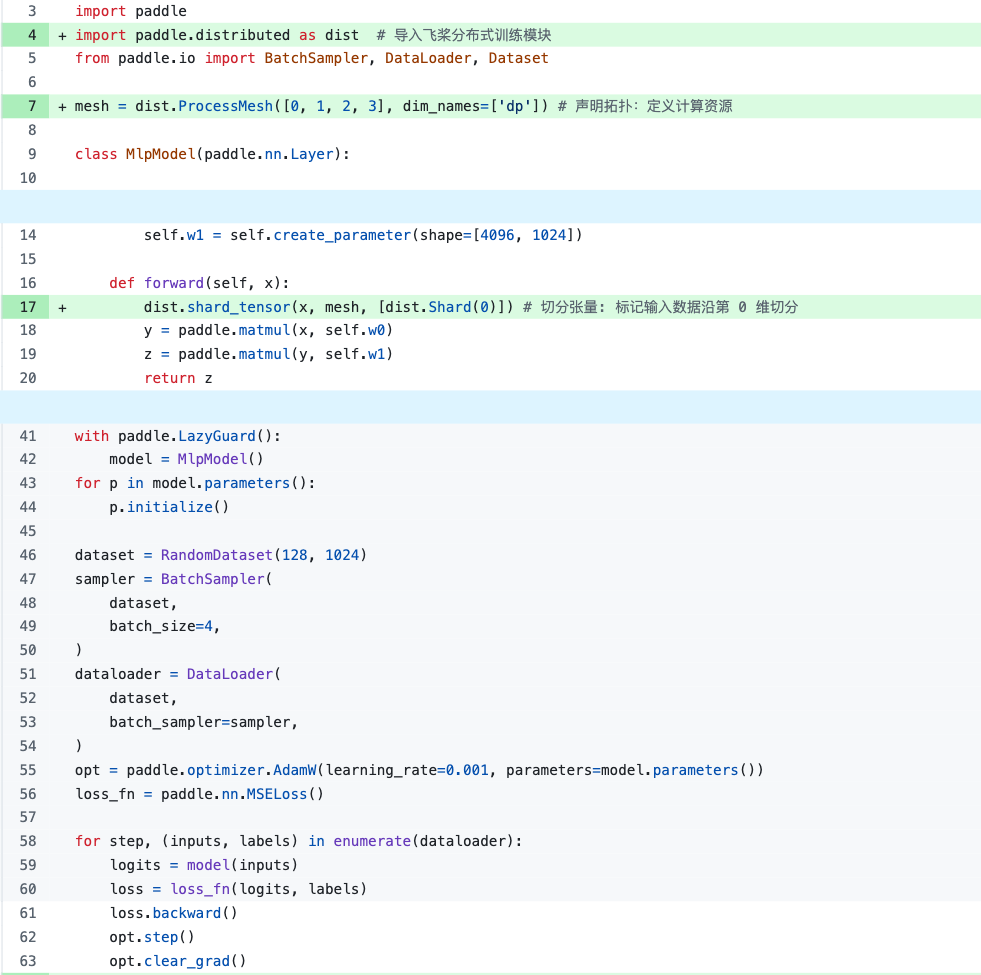
仅需 3 行代码实现分布式训练
一、自动并行原理介绍
接下来我们将揭秘飞桨框架3.0自动并行架构的原理与核心实现。自动并行的设计理念遵循“开发者友好,框架自动化”原则,开发者仅需以单卡的逻辑视角完成模型构建,借助少量切分标记API调用,即可将模型转换为并行训练程序,显著简化开发过程。
自动并行流程包含五个主要阶段:
- 分布式表示:将开发者标记的模型组网用分布式张量进行表示。
- 切分推导:为组网中的所有张量推导出一个合理高效的切分状态。
- 切分转换:根据张量切分状态自动插入AllReduce/AllGather等通信原语。
- 静态编译优化:在静态图模式下基于静态图进行图优化提升训练性能。
- 模型保存:保存或转换训练好的模型 checkpoint。
该框架实现了动态图开发与静态图执行的统一范式:在动态图模式下提供即时反馈,在静态图模式下生成优化后的计算图,仅需一键调用 paddle.distributed.to_static 实现无缝转换,并兼顾开发效率与运行性能。后续章节将深入解析各技术细节。
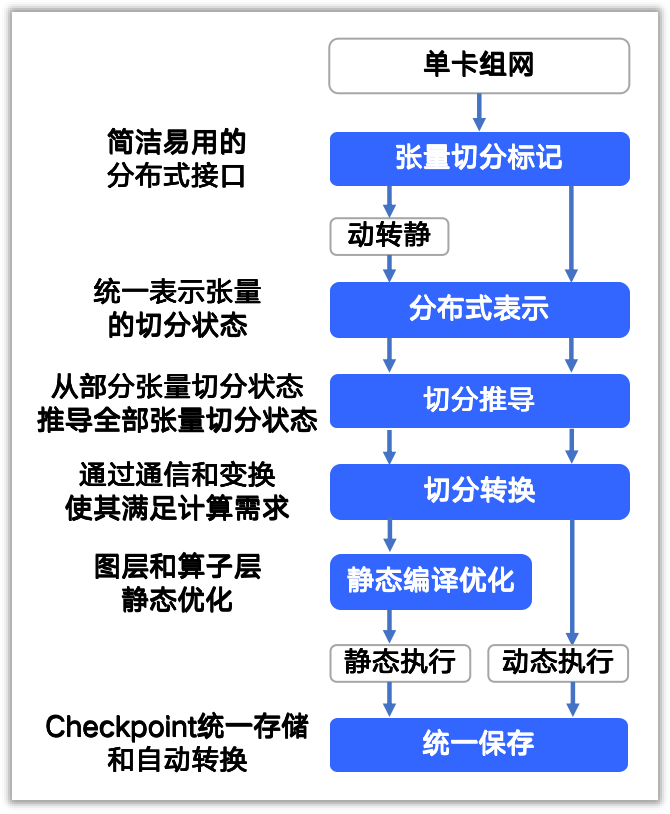
飞桨框架3.0自动并行流程图
PART01 分布式张量表示
现有的分布式并行策略(数据并行/张量并行/流水线并行等)都是通过(1)切分输入/输出(2)切分模型参数 (3)切分计算 这三种方式,满足在多计算设备上加速大模型训练的需求。为了提供更易用的分布式接口,飞桨框架自动并行架构提出“分布式张量”这一概念,描述由多个计算设备上的局部物理张量共同组成的全局逻辑张量。开发者仅需进行语义标注,飞桨框架便会自动处理底层分布逻辑。为精确描述分布式张量和计算设备之间的映射关系,飞桨框架3.0引入两个核心分布式概念:
1. ProcessMesh:指用于大模型训练或推理的多个硬件设备拓扑结构。将一个设备(比如一块 GPU 卡)映射为一个进程,将多个设备映射为多个进程组成的一维或多维数组,下图展示了由 4个设备构成的 2*2 ProcessMesh 抽象表示。
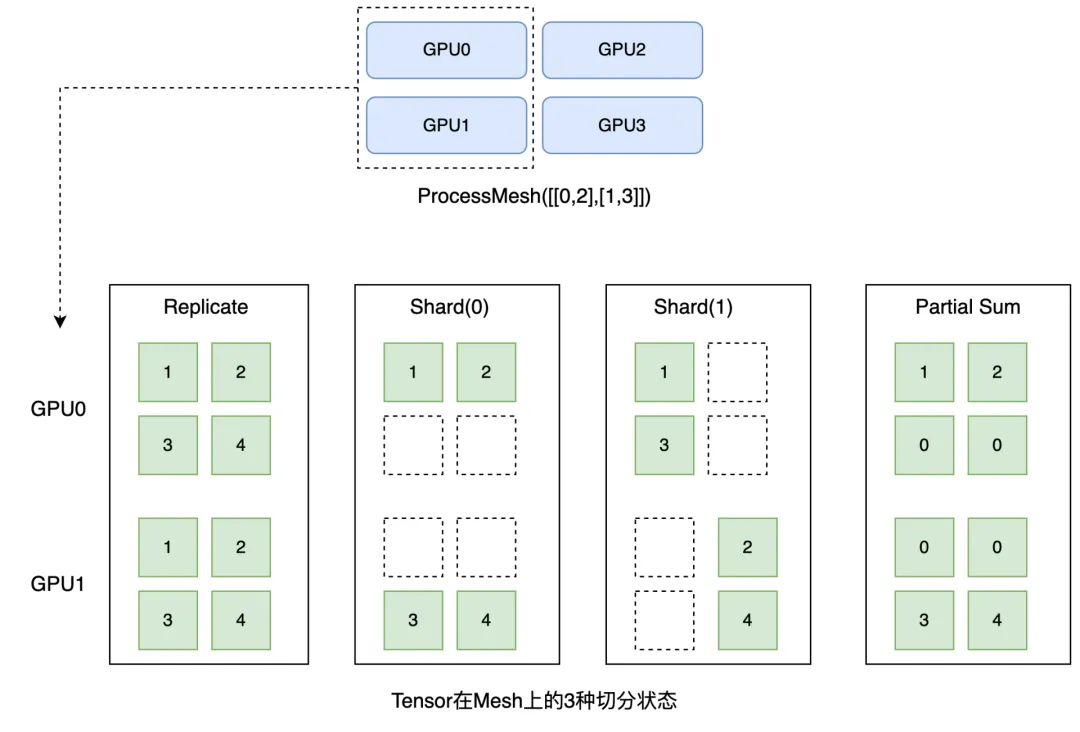
2. Placements:定义张量在不同设备上的分布式切分状态,是由 Replicate、Shard、Partial 三种分布式标记组成的列表,长度和 ProcessMesh 的维度一致,⽤于表示分布式张量在对应计算设备的维度上,按照哪种分布式标记做切分,这三种分布式标记的详细描述如下:
- Replicate():指张量在所有计算设备上保持全复制状态。
- Shard(axis):指张量沿 axis 维度进行切片,不同的分片放在不同的计算设备上。
- Partial(reduce_type):指每个计算设备只拥有部分值,需要通过 allreduce_sum 或其它指定的规约操作才能恢复成全量数据。Partial 状态往往在网络运算过程中产生,很少显式标记 Partial 状态。
示例:我们在 6 个计算设备上,创建形状为(4, 3)的分布式张量,沿着计算设备的 x 维,切分张量的第 0 维;沿着计算设备的 y 维,切分张量的第 1 维。最终,每个计算设备实际拥有大小为(2, 1)的实际张量,如图所示:
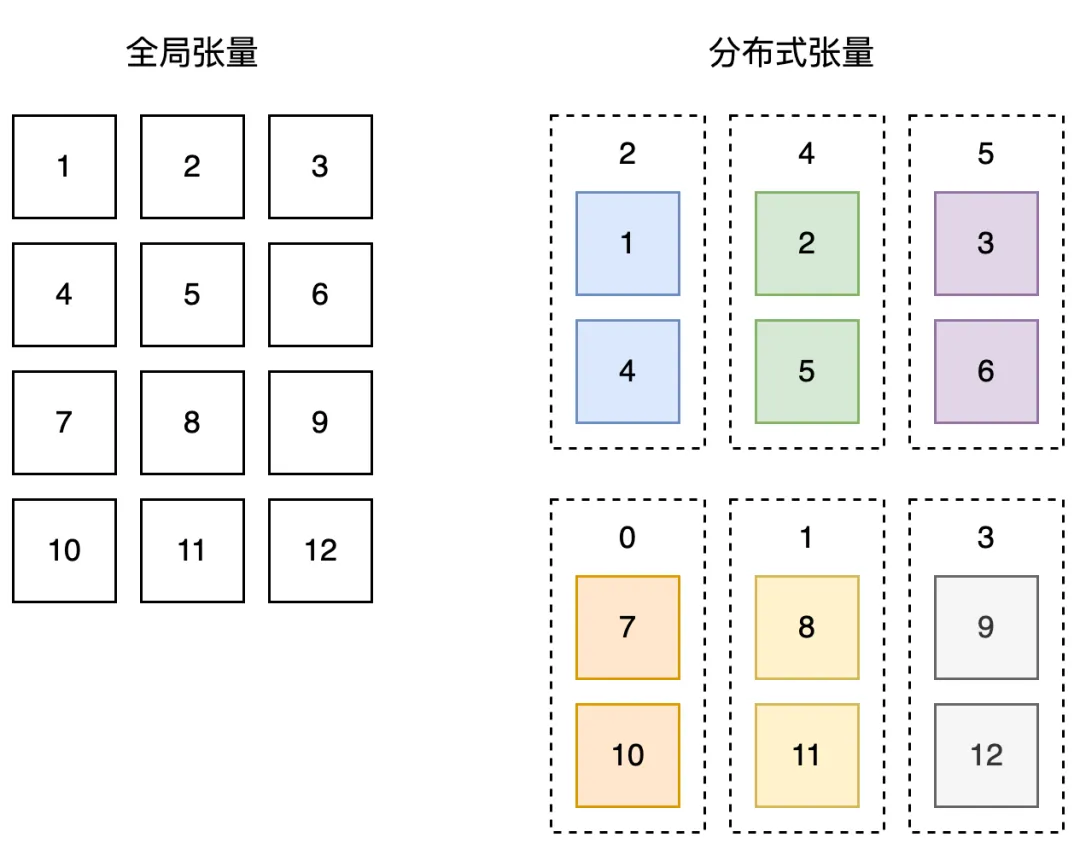
全局张量和分布式张量
对应的代码如下:
- mesh = dist.ProcessMesh( [ [ 2 , 4 , 5 ] , [ 0 , 1 , 3 ] ] , dim_names= [ ‘x’ , ‘y’ ] ) 定义了6个设备的拓扑结构,并定义了 ProcessMesh 2个轴的名称分别为 x 和 y,分别对应设备的第 0 维和第 1 维;
- dense_tensor 是全局张量;
- placements 定义了该张量在各个设备上的切分状态,沿设备的 x 维切分张量的第 0 维(行切),沿设备的 y 维切分张量的第 1 维(列切);
- dist_tensor 为最终的分布式张量;
import paddle
import paddle.distributed as dist
mesh = dist.ProcessMesh([[2, 4, 5], [0, 1, 3]], dim_names=['x', 'y'])
dense_tensor = paddle.to_tensor([[1,2,3],
[4,5,6],
[7,8,9],
[10,11,12]])
placements = [dist.Shard(0), dist.Shard(1)]
dist_tensor = dist.shard_tensor(dense_tensor, mesh, placements)
此外,飞桨框架支持重切分的功能。例如,支持跨 ProcessMesh 的分布式张量转换,将设备 [0,1] 上的 Replicate 张量迁移至设备 [2,3] 并转为 Shard 状态。如图所示:
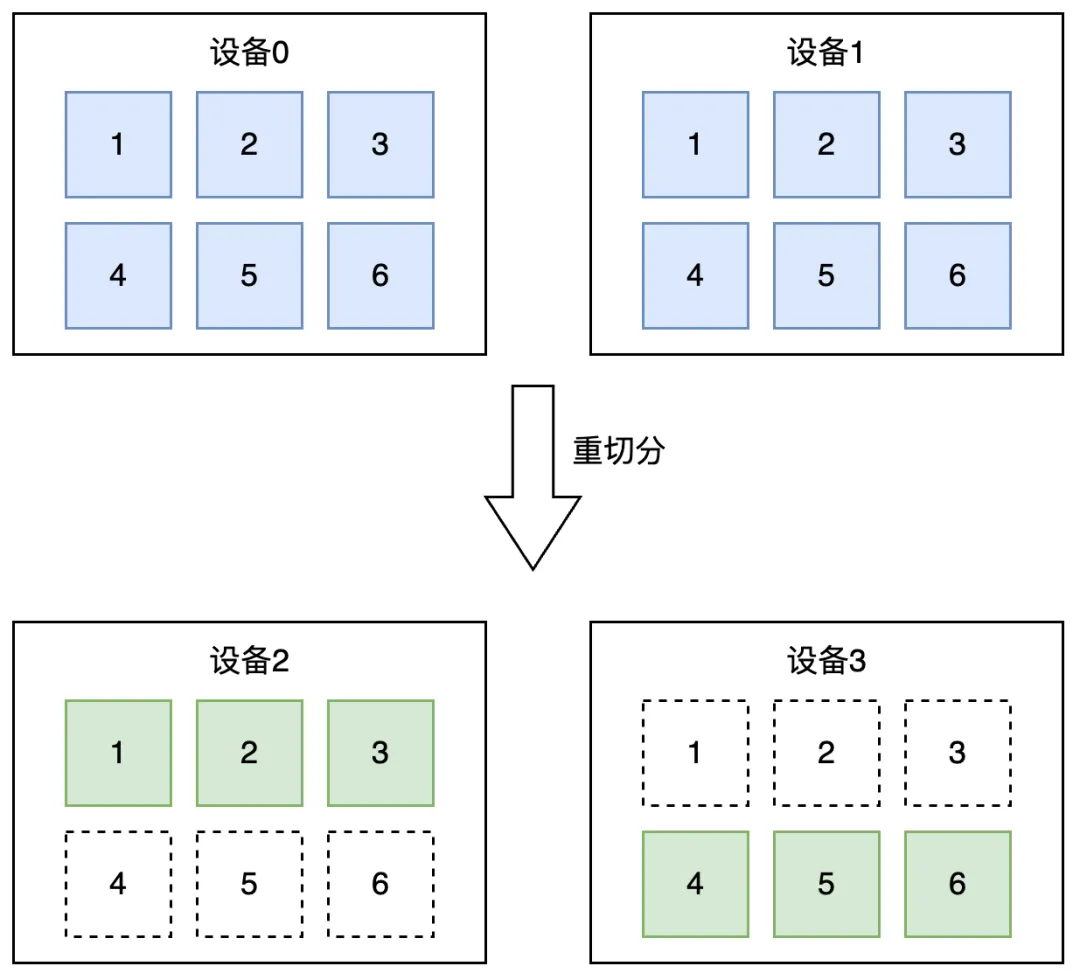
重切分
对应的代码如下,通过调用 paddle.distributed.reshard(dist_tensor, mesh, placements) API,实现跨 ProcessMesh 的分布式张量转换:
reshard:
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/distributed/reshard_cn.html
import paddle
import paddle.distributed as dist
mesh0 = dist.ProcessMesh([0, 1], dim_names=['x'])
mesh1 = dist.ProcessMesh([2, 3], dim_names=['x'])
dense_tensor = paddle.to_tensor([[1,2,3],
[4,5,6]])
placements0 = [dist.Replicate()]
placements1 = [dist.Shard(0)]
dist_tensor = dist.shard_tensor(dense_tensor, mesh0, placements0)
dist_tensor_after_reshard = dist.reshard(dist_tensor, mesh1, placements1)
PART02 自动并行核心流程
有了上述的分布式张量表示之后,用户仅需给模型中的少数张量做切分标记,框架就会自动推导出其余全部张量和算子的切分状态,并在需要的地方插入正确且高效的通信操作,保证结果的正确性。
如图,在单卡逻辑视角下我们希望完成计算 C = Matmul(A, B),D = Relu©。假设用户对 Matmul 算子的输入张量 A 和 B 进行了标记,将 A 标记成 Replicate(),表示所有计算设备上都有完整 A 副本,将 B 标记成 Shard(0),表示在实际分布式集群中 B 被按行切分到不同的计算设备上。然后飞桨框架会自动推导出 A、B、C 和 D 的正确切分状态,并按需要插入通信操作,以完成分布式计算。
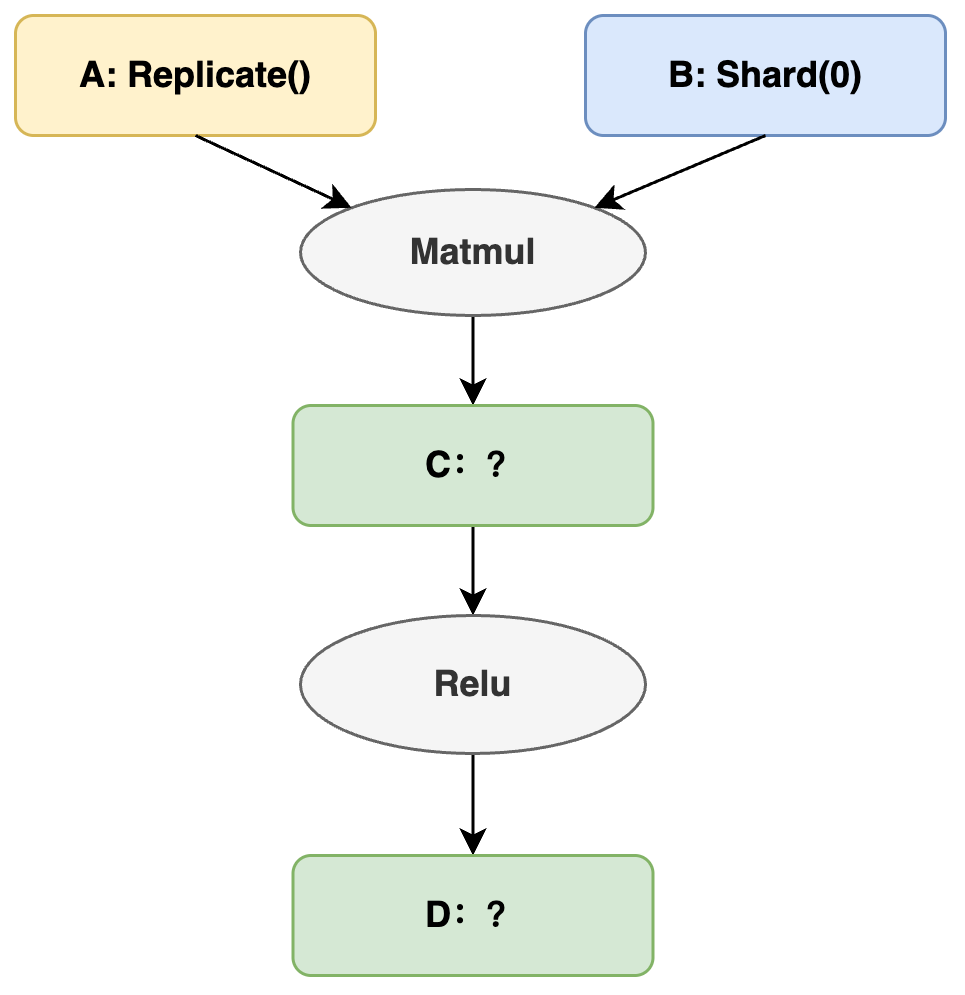
切分推导之前:C和D的切分状态未知
框架是如何完成整个过程的呢?这就涉及到切分推导和切换转换两个核心流程。
1. 切分推导(InferSPMD)
当前标记的输入切分状态是无法被 Matmul 算子实际计算的 (张量 A 的第 0 维和张量 B 的第 1 维不匹配)。此时自动并行架构会使用当前算子的切分推导规则(e.g. MatmulSPMD Rule) ,根据输入张量的切分状态,推导出一套合法且性能较优的 输入-输出 张量的切分状态:
- 张量 A 需调整为按列切分(与张量 B 的行切分对齐)
- 张量 B 保持切分状态不变
- 张量 C 的切分状态被推导出是 Partial
Relu 算子因非线性特性,输入不能是 Partial 状态,所以框架会根据 ReluSPMD Rule 将张量 C 输入 Relu 前的切分状态推导成 Replicate。
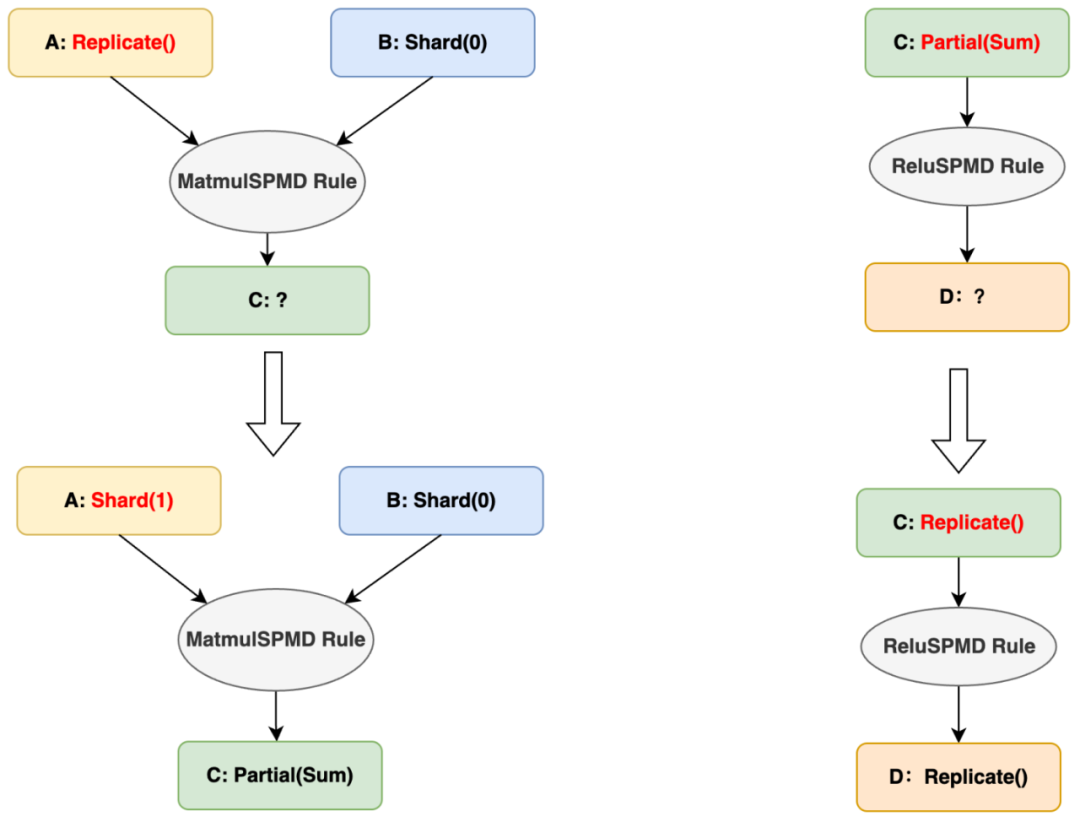
切分推导之后:C和D的切分状态已知
2. 切分转换(TransformSPMD)
在有了所有张量的切分状态后,框架会基于张量当前的切分状态、切分推导规则推导出的算子计算需要的目标切分状态,插入对应的通信/张量维度变换算子。
- 在 Matmul 算子前插入 Split 算子:将张量 A 从 Replicate 转为 Shard(1) (按列切分);
- 在 Relu 算子前插入 AllReduce 算子:将张量 C 的 Partial 状态转换为 Replicate。
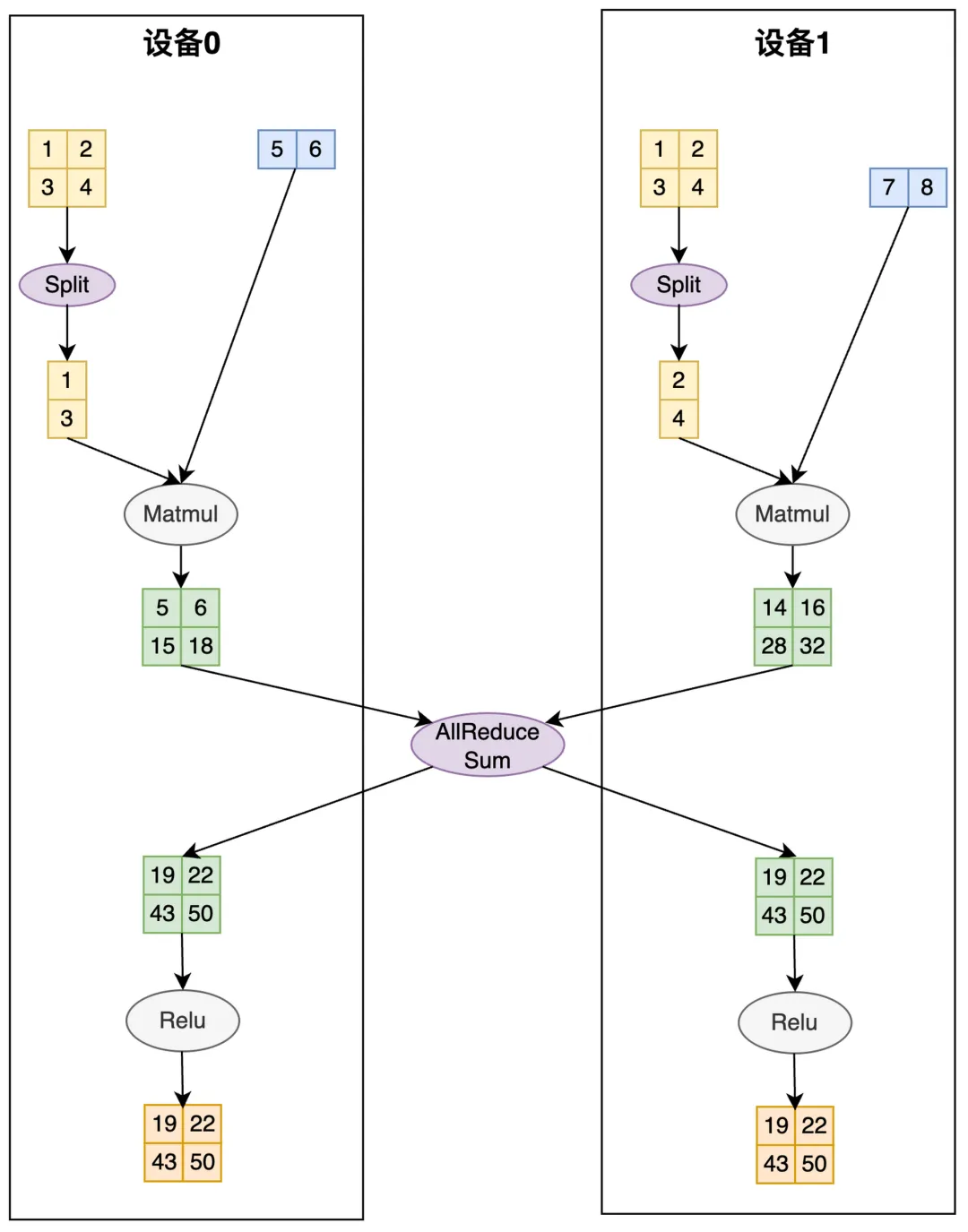
切分转换:执行合适的通信操作
二、混合并行实践
基于前述内容,飞桨框架3.0自动并行功能已能完整支持大模型训练所需的各类并行策略。以下展示一个融合数据并行、张量并行与流水并行三种策略的综合示例:
硬件配置采用8块GPU(编号0-7),组成 ProcessMesh,其分布为 [[[0, 1], [2, 3]], [[4, 5], [6, 7]]],组织成(2, 2, 2)的矩阵,对应的维度名称为 pp, dp, mp。模型由两个 Linear 层构成,通过跨 mesh 传输中间结果实现流水线并行。输入数据沿 ProcessMesh 的 dp 维进行切分,实现数据并行;两个 Linear 的参数分别沿 ProcessMesh 的 mp 维按列和按行进行切分,实现张量并行。具体架构示意如下:
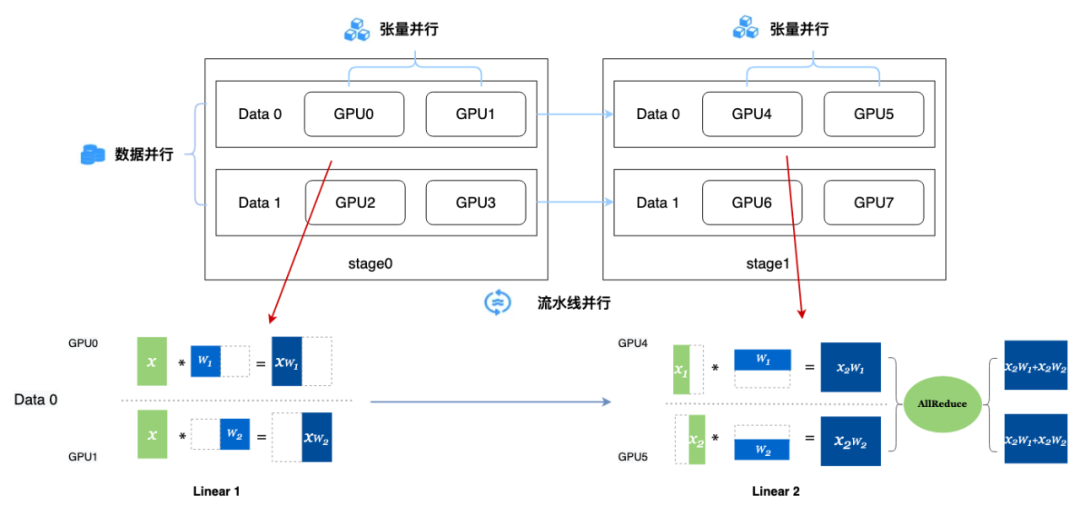
8卡混合并行示例
按照上面的模型定义,对应的自动并行代码实现如下。其中自动并行的核心代码是第45-49行,这里第49行飞桨提供了一个 paddle.distributed.parallelize 接口,它内部会自动调用 paddle.distributed.shard_tensor 来对模型进行张量切分标记,用户可以通过 parallel_config(第46-49行)来配置需要切分的张量及其切分方式。
# 运行方式: python -m paddle.distributed.launch --device=0,1,2,3,4,5,6,7 train.py
import numpy as np
import paddle
import paddle.distributed as dist # 导入飞桨分布式训练模块
from paddle.io import BatchSampler, DataLoader, Dataset
# 声明拓扑:定义计算资源,8张卡组织成(2, 2, 2)的矩阵
mesh = dist.ProcessMesh([[[0, 1], [2, 3]], [[4, 5], [6, 7]]], dim_names=['pp','dp', 'mp'])
dist.set_mesh(mesh)
def _get_mesh(pp_idx=0):
return mesh.get_mesh_with_dim("pp")[pp_idx]
class RandomDataset(Dataset):
def __init__(self, seq_len, hidden, num_samples=100):
super().__init__()
self.seq_len = seq_len
self.hidden = hidden
self.num_samples = num_samples
def __getitem__(self, index):
input = np.random.uniform(size=[self.seq_len, self.hidden]).astype("float32")
label = np.random.uniform(size=[self.seq_len, self.hidden]).astype('float32')
return (input, label)
def __len__(self):
return self.num_samples
class MlpModel(paddle.nn.Layer): # 模型组网中无需任何分布式代码,算法策略与分布式策略分离
def __init__(self):
super(MlpModel, self).__init__()
self.linear1 = paddle.nn.Linear(1024, 4096, bias_attr=False)
self.linear2 = paddle.nn.Linear(4096, 1024, bias_attr=False)
def forward(self, x):
y = self.linear1(x)
z = self.linear2(y)
return z
with paddle.LazyGuard():
model = MlpModel()
opt = paddle.optimizer.AdamW(learning_rate=0.001, parameters=model.parameters())
# 配置需要切分的张量及其切分方式
parallel_config = {
"mp_config": {"parallelize_plan": {"linear1": dist.ColWiseParallel(), "linear2": dist.RowWiseParallel()}},
"pp_config": {"split_spec": {"linear1": dist.SplitPoint.END}},
}
dist_model, dist_opt = dist.parallelize(model, opt, config=parallel_config)
for p in dist_model.parameters():
p.initialize()
dataset = RandomDataset(128, 1024)
sampler = BatchSampler(
dataset,
batch_size=4,
)
dataloader = DataLoader(
dataset,
batch_sampler=sampler,
)
dataloader = dist.shard_dataloader(dataloader, meshes=[_get_mesh(0), _get_mesh(1)], shard_dims="dp")
loss_fn = paddle.nn.MSELoss()
for step, (inputs, labels) in enumerate(dataloader()):
logits = dist_model(inputs)
loss = loss_fn(logits, labels)
loss.backward()
dist_opt.step()
dist_opt.clear_grad()
为助力开发者聚焦模型创新而非分布式工程难题,飞桨提供了完整的自动并行大模型实现,包括 LLaMA、QwenVL、GPT-3等主流大模型,覆盖自然语言处理、多模态等不同场景。开发者可通过飞桨大模型开发套件(PaddleNLP、PaddleMIX)直接获取经过全面验证的自动并行训练方案!
PaddleNLP:
https://github.com/PaddlePaddle/PaddleNLP
PaddleMIX:
https://github.com/PaddlePaddle/PaddleMIX
三、自动并行性能优化
在实际的大模型业务训练场景中,训练吞吐量是衡量性能的关键指标。飞桨框架提供动态图与静态图两种执行模式。动态图可以即时得到执行结果,方便开发和调试,静态图会做性能优化和调度编排,充分发挥硬件性能。为了兼顾易用性和性能,飞桨框架3.0支持动态图自动并行向静态图自动并行的一键转换,并自动集成多种性能优化策略,支持计算图的全局优化,实现最佳的执行性能。这一特性正是飞桨框架3.0动静统一自动并行的特色优势。
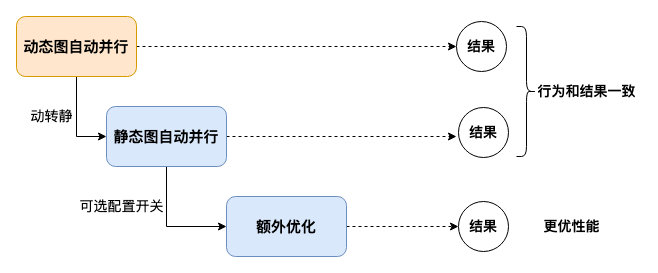
动静统一自动并行
自动并行内置了多种性能优化策略,包括:重计算、算子融合优化、参数切片并行优化、张量并行优化等,这些策略协同作用,显著提升分布式训练的整体吞吐量。用户仅需简单配置 paddle.distributed.Strategy 中的相关参数,即可启用静态图自动并行模式下的性能优化策略。
在自动并行模式下,可以通过如下代码开启性能优化策略:
import paddle.distributed as dist
# ... model, dataloader, loss_fn, opt 定义,与动态图自动并行一致...
# 配置 strategy 以应用各类性能优化策略
strategy = dist.Strategy()
# ...配置 strategy 开启各个优化...
strategy._recompute.enable = True
# ...
# 一键动转静
dist_model = dist.to_static(model, dataloader, loss_fn, opt, strategy=strategy)
dist_model.train()
for step, inputs in enumerate(dataloader):
loss = dist_model(inputs)
使用 strategy 来应用各类性能优化策略,具体优化策略和用法如下:
重计算:
- recompute:重计算技术是一种时间换空间的策略,在前向计算中舍弃一些中间变量不进行保存,反向计算时再重新计算这些变量。
- refined recompute:精细化重计算,指定重计算网络层中部分算子不进行重计算,最大化重计算的收益。
strategy._recompute.enable = True
# 应用重计算策略时需要使用 recompute 接口对需要进行重计算的模型层进行装饰
算子融合:
- fused_linear_param_grad_add:将模型中的参数梯度计算和加法操作融合为一个算子,以减少计算开销。
- fuse_linear:将 Linear 中的 matmul 和 add 算子融合为一个 fused_linear 算子,以减少计算开销和调度开销。
- fuse_allreduce_split_to_reducescatter:将 allreduce 通信和 split 切分操作融合为 reduce_scatter,以减少通信开销。
strategy.fused_passes.fused_passes_list.append("fused_linear_param_grad_add_pass")
strategy.fused_passes.fused_passes_list.append("fused_gemm_epilogue_pass")
strategy.fused_passes.fused_passes_list.append("fuse_allreduce_split_to_reducescatter_pass")
分组切片并行优化:
- tensor_fusion:将多个小的通信操作(如梯度或参数的传输)合并为一个大通信操作,以减少通信开销。
- 通信计算overlap:将分组切分并行中的计算与通信操作重叠,提升训练效率。
- release_gradients:释放梯度显存,以降低训练过程中的显存开销。
strategy.sharding.enable_tensor_fusion = True
strategy.sharding.enable_overlap = True
strategy.sharding.release_gradients = True
张量并行优化:
- replace_with_c_embedding:将列切的embedding算子替换为行切的c_embedding算子,并自动插入通信。
- replace_with_parallel_cross_entropy:将 cross_entropy_with_softmax 算子替换为带通信的算子 c_softmax_with_cross_entropy,以降低显存开销并加速计算。
strategy._mp_optimization.replace_with_c_embedding = True
strategy._mp_optimization.replace_with_parallel_cross_entropy = True
以Llama2的预训练为例,充分利用静态优化策略后,飞桨自动并行训练性能领先20%!
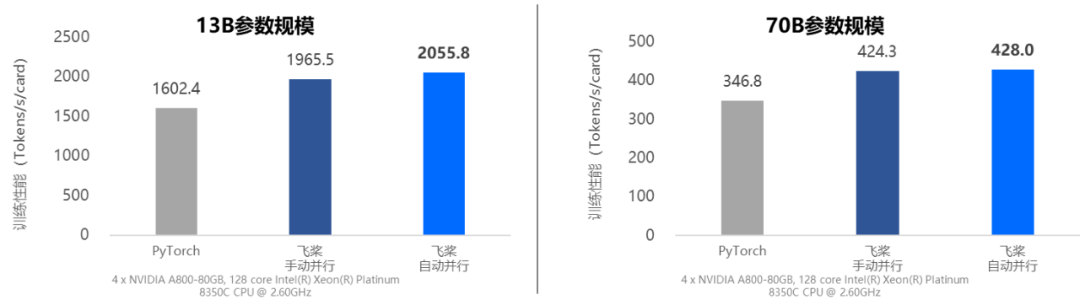
动静统一自动并行训练速度对比
四、总结
飞桨框架3.0通过自动并行开发范式革新,彻底重构大模型分布式训练体验:
- 开发者体验升级:开发者无需深入掌握手动并行编程的复杂原理及API调用,仅需对张量切分进行简单标注,即可高效构建混合并行模型。以 Llama2的预训练为例,传统实现方式需要开发者精细调整通信策略,以确保正确高效执行,而自动并行实现方式相比传统方式减少80%的分布式核心代码,极大降低了开发复杂度。
- 全面技术验证:基于PaddleNLP+PaddleMIX大模型开发套件,飞桨已完成 Llama、QwenVL 从预训练到SFT、LoRA、DPO等精调的全流程自动并行验证,支持自然语言处理、多模态生成等核心场景。
- 极致性能优化:得益于飞桨框架独特的动静统一设计,用户仅需简单添加一行代码,即可轻松实现从动态图到静态图的转换,并充分利用多种静态优化技术,实现持平甚至超越经过极致优化的动态图训练性能。
未来,飞桨将持续迭代和优化自动并行的使用体验,聚焦高可用、高易用、高性能三维升级:
- 基础能力覆盖:拓展更多并行策略、适配国产硬件生态、实现自动并行推理。
- 易用性突破:提供更灵活易用的流水并行接口、基于 cost-model 自动搜索和选择最优的并行策略。
- 性能优化:提升动态图自动并行性能、结合编译器技术实现更极致和通用的性能优化。
官方课程与实测活动
直播课程:4月23日20:30,技术解析加代码实战,一线研发大佬为大家详细解析飞桨新一代框架3.0大模型自动并行强大能力,现场coding带你开箱体验,轻松实现分布式训练!
实测活动:官方case开源代码直给、官方驻群答疑为你护航、不同难度任务体系任你自选,更有现金奖学金等实用奖励加成,快来上手实测吧!
测评征集:飞桨框架3.0正式版现已全面开放,诚邀广大用户体验使用!在技术网站发布本人真实的测评报告/使用tips/实际场景应用实例等经验帖,并提交到官方(详情请见直播课程及官方社群),通过验收的高质量测评可获得最高千元激励金。
更多学习资源
飞桨开源代码库自动并行目录:
https://github.com/PaddlePaddle/Paddle/tree/develop/python/paddle/distributed/auto_parallel
飞桨社区源码读书会:
https://github.com/PaddlePaddle/community/tree/master/pfcc/paddle-code-reading


















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









