







hadoop1.x中,map task分为4种,分别是 job-setup task、job-cleanup task、task-cleanup task和map task。其中,job-setup task 和job-cleanup task分别是作业运行时启动的第一个任务和最后一个任务,主要工作分别是进行一些作业初始化和收尾工作,比如创建和删除作业临时输出目录;而task-cleanup task则是任务失败或者被杀死后,用于清理已写入临时目录中数据的任务,本文中介绍第四种map task,它需要处理数据
map task 整体流程
map task的整体计算流程可以分为5个阶段
1、read 阶段:map task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value
2、map 阶段:该阶段主要是将解析出的key/value交给用户编写的map()函数处理,并产生一系列新的key/value
3、collect阶段:在用户编写的map()函数中,当数据处理完成后,一般会调用outputCollector.collect()输出结果,在该函数内部,它会将生成的key/value分片(通过调用partitioner),并写入一个环形内存缓冲区中。
4、split阶段:即 “溢写”,当环形缓冲区满后,mapreduce会将数据写到本地磁盘上,生成一个临时文件,需要注意的是,将数据写入本地磁盘前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作
5、combine阶段:当所有数据处理完成以后,map task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件
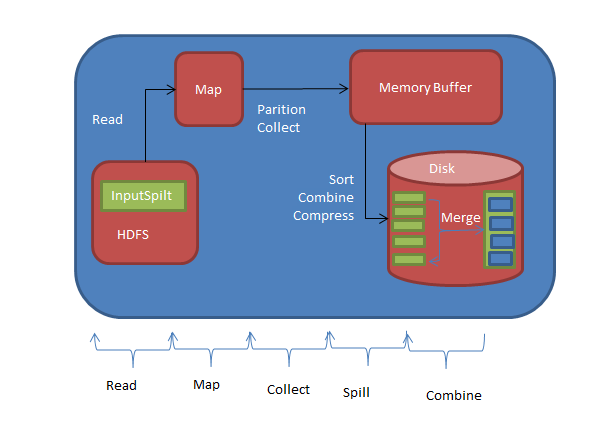
map task 计算流程
在map task中,最重要的部分是输出的结果在内存中和磁盘中的组织方式,具体涉及collect、spill和combine三个阶段,也就是用户调用OutputCollector.collect()函数之后依次经历的几个阶段,
collect过程分析
待map()函数处理完一对key/value,并产生新的key/value后,会调用OutputCollector.collect()函数输出结果,
跟踪进入map task的入口函数run(),可发现,如果用户选用旧API,则会调用runOldMapper函数处理数据,该函数根据实际的配置创建合适的MapRunnable以迭代调用用户编写的map()函数,而map()函数的参数OutputCollector正是MapRunnable传入的OldOutputCollector对象
OldOutputCollector根据作业是否包含Reduce task封装了不同的MapOutputCollector实现,如果Reduce Task数目为0,则封装DirectMapOutputCollector对象直接将结果写入HDFS中作为最终结果,否则封装MapOutputBuffer对象暂时将结果写入本地磁盘上以供Reduce Task进一步处理,接下来我们介绍reduce task数目非0的情况
用户在map()函数中调用OldOutputCollector.collect(key,value)后,在该函数内部,首先会调用Partitioner.getPartition()函数获取记录的分区号partition,然后将三元组
private int bufindex = 0; // marks end of collected
private int bufmark = 0; // marks end of record
private byte[] kvbuffer; // main output buffer
private static final int PARTITION = 0; // partition offset in acct
private static final int KEYSTART = 1; // key offset in acct
private static final int VALSTART = 2; // val offset in acct
private static  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1574
1574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









