







聚合数据样本展示
1)聚合报告
官方介绍:
聚合报告为测试中的每个不同命名的请求创建一个表行。对于每个请求,它总计响应信息并提供请求计数,最小值,最大值,平均值,异常率,近似吞吐量(请求/秒)和每秒千字节吞吐量。测试完成后,吞吐量是整个测试期间的实际吞吐量。
吞吐量是从取样器目标(例如,HTTP样本的远程服务器)的角度计算的。JMeter考虑了生成请求的总时间。如果其他取样器和定时器位于同一线程中,则会增加总时间,从而降低吞吐量值。因此,具有不同名称的两个相同的取样器将具有两个具有相同名称的取样器的吞吐量的一半。正确选择取样器名称以从聚合报告中获得最佳结果非常重要。
计算中位数和90%线(第90百分位数)值需要额外的内存。JMeter现在将相同经过时间的样本相结合,因此使用的内存更少。但是,对于花费时间超过几秒的样本,或者另一种可能性是很少的样本具有相同的时间,在这种情况下需要更多的内存。注意您可以使用此监听器在测试结束后重新加载CSV或XML结果文件,这是避免性能影响的推荐方法。请参阅汇总报告了解类似的监听器,它不存储单个样本,因此需要恒定的内存。
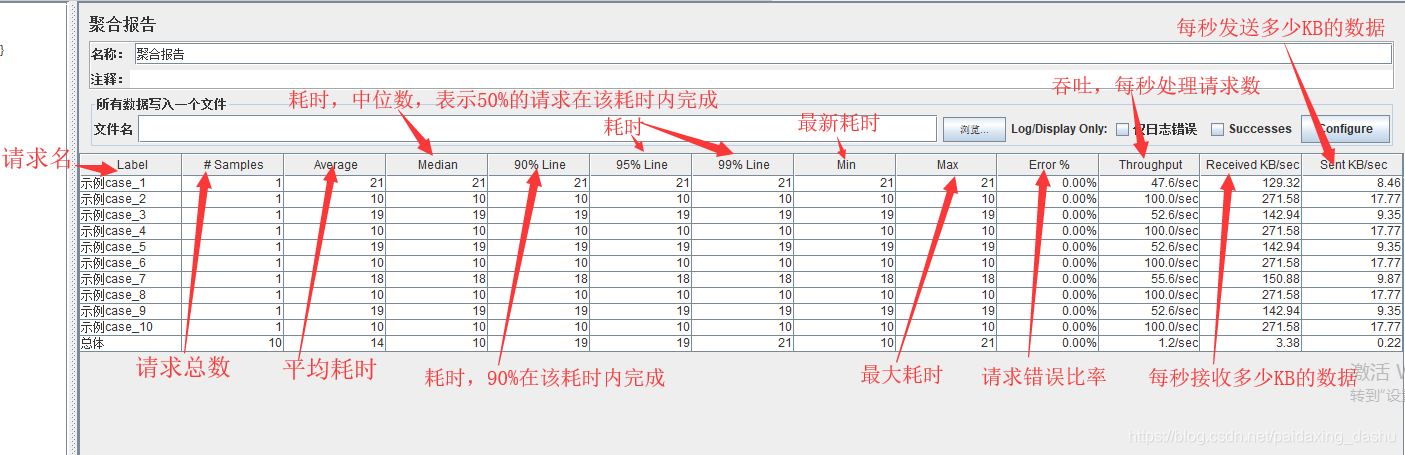
- Label:样本的标签。
- #Samples:具有相同标签的样本数
- Average:一组结果的平均时间
- Median:中位数是一组结果中间的时间。50%的样本不超过这个时间;其余的至少花了这么长时间。
- 90%Line:90%的样本不超过这个时间。剩下的样本至少花了这么长时间。
- 95%Line:95%的样本不超过这个时间。剩下的样本至少花了这么长时间。
- 99%Line:99%的样本不超过这个时间。剩下的样本至少花了这么长时间。
- Min:具有相同标签的样本的最短时间
- Max:具有相同标签的样本的最长时间
- Error%:异常请求的百分比
- Throughput:吞吐量以每秒/分钟/小时的请求来衡量。
- Received KB/sec:以每秒收到的千字节为单位测量的吞吐量
- Sent KB/sec:以每秒发送的千字节为单位测量的吞吐量
- Include group name in label?:标签名字是否加上线程组的名字,勾选了就加上。
时间单位是毫秒
2)Summary Report(汇总报告)
这是为测试中的每个不同名字的请求创建一个表行。和聚合报告类似,只是它使用更少的内存。也就是说相同名字的请求会被统计在同一行。
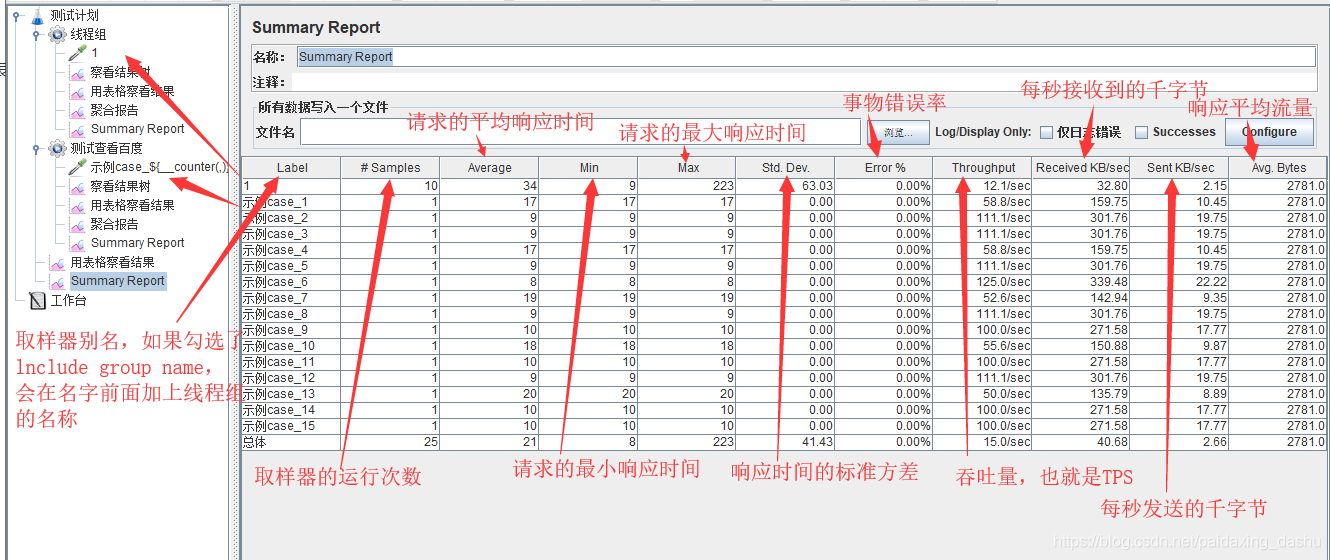
- Label:样本标签。
- #Samples:具有相同标签的样本数
- Average:一组结果的平均经过时间,单位毫秒
- Min:具有相同标签样本的最短经过时间,单位毫秒
- Max:具有相同标签样本的最长经过时间,单位毫秒
- Std.Dev.:样本经过时间的标准偏差,单位毫秒
- Error%:异常请求的百分比
- Throughput:吞吐量以每秒/分钟/小时的请求来衡量。自动选择时间单位,使显示的速率至少为1.0。当吞吐量保存到CSV文件时,它以请求/秒表示,即30.0请求/分钟保存为0.5。
- Received KB/sec:以千字节/秒为单位测量的吞吐量,接收的
- Sent KB/sec:以千字节/秒为单位测量的吞吐量,发送的
- Avg. Bytes:样本响应的平均大小(以byte为单位)
- Include group name in label?:是否包含组名(线程组的名称)
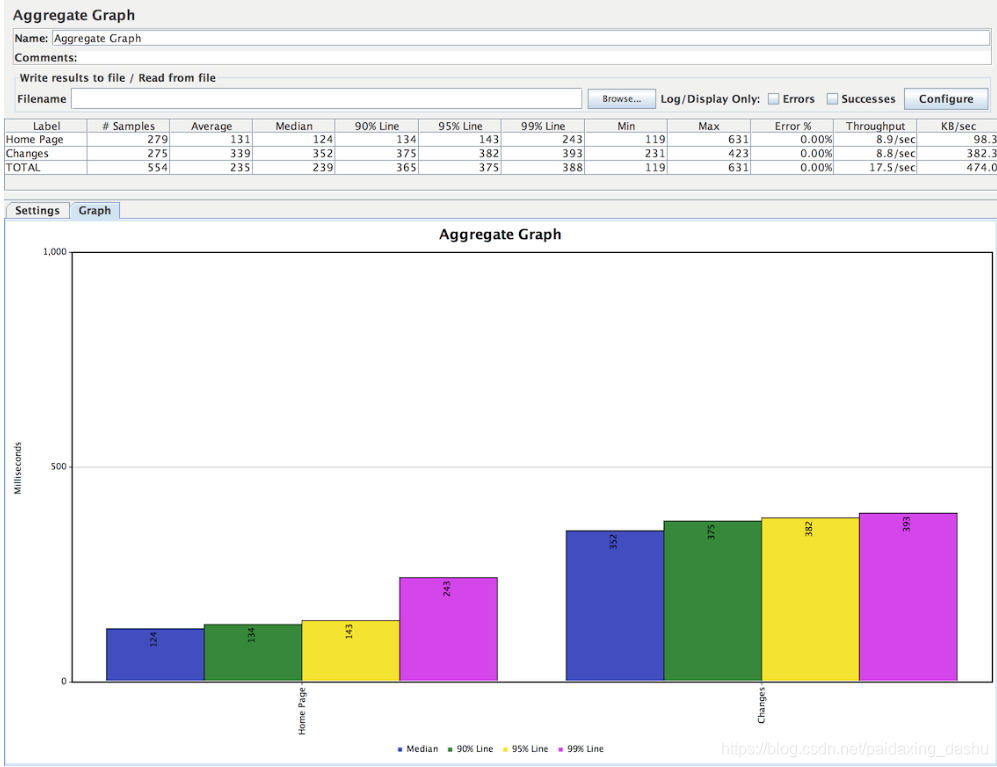
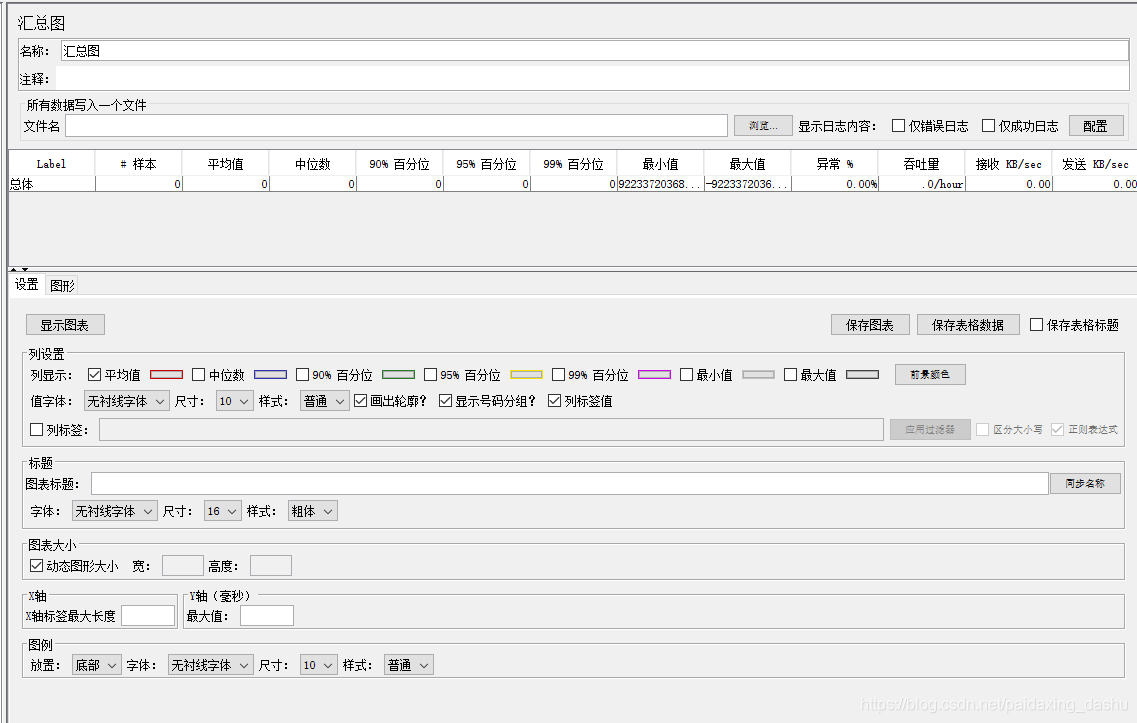
3)Aggregate Graph(汇总图)
汇总图与聚合报告类似。主要区别在于汇总图提供了一种生成条形图并将图形保存为PNG文件的简便方法。
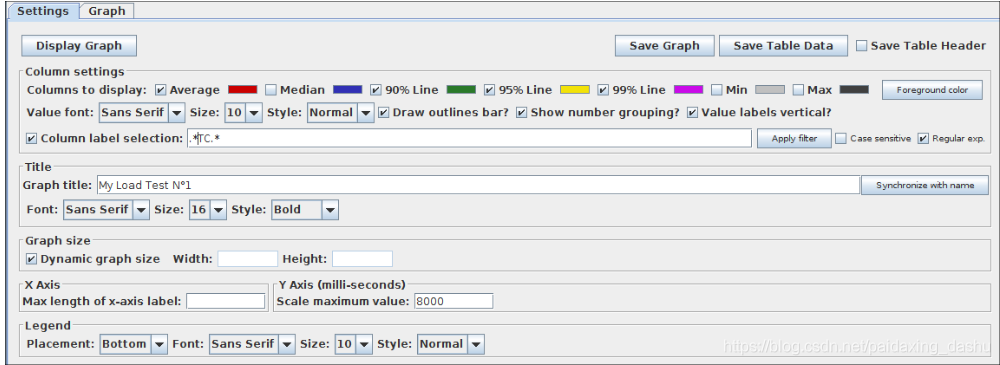
Column settings:
- Columns to display:选择要在图中显示的列
- Rectangles color:单击右侧颜色矩形打开弹出对话框,选择自定义颜色。
- Foreground color:允许更改文本颜色
- Value font:允许定义文本的字体设置
- Draw outlines bar?:是否在条形图上绘制边界线
- Show number grouping?:是否显示Y轴标签中的数字分组
- Value labels vertical?:是否更改标签的方向(默认为水平)
- Column label selection:按结果标签过滤
Title:
- 在图表的头部定义图表的标题
Graph size:
- 根据当前JMeter窗口大小的宽度和高度计算图形大小。使用“宽度”和“高度”字段定义自定义大小。单位是像素
X Axis settings:
- 定义X轴标签的最大长度(像素为单位)
Y Axis settings:
- 定义Y轴标签的最大长度(像素为单位)
Legend:
- 定义图表图例的放置和字体设置
5.1版本的:
4)图形结果
在压力测试期间不得使用图形结果,因为它消耗了大量资源(内存和CPU)。仅用于功能测试或测试计划调试和验证期间。
图形结果监听器生成一个简单的图形,用于绘制所有取样时间。
颜色:
- 黑色:以毫秒为单位显示当前样本
- 蓝色:所有样本的当前平均值
- 红色:当前标准差
- 绿色:当前吞吐量
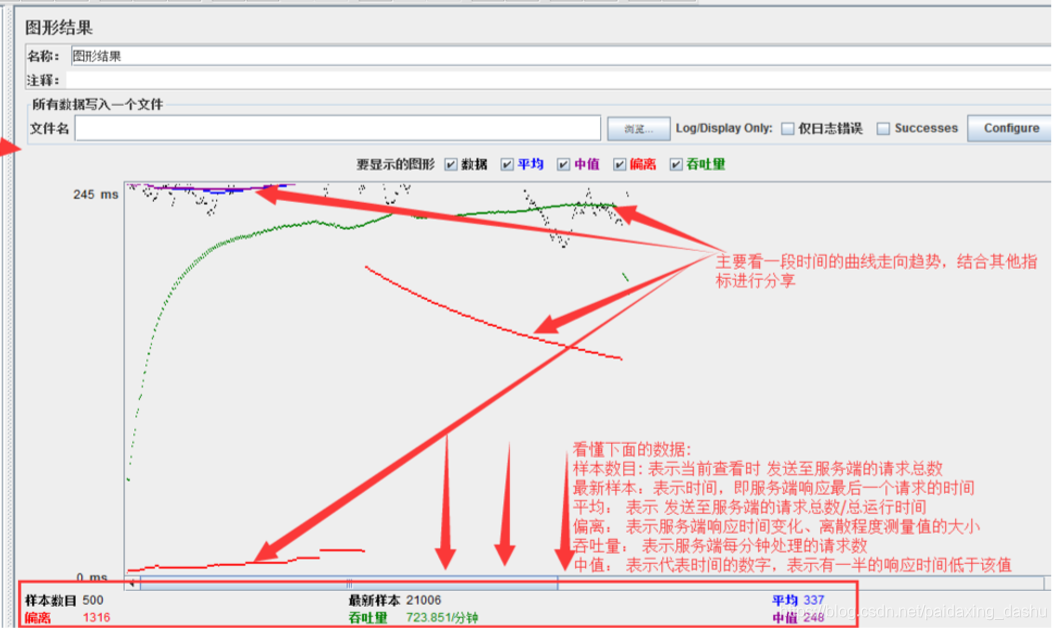
- 样本数目:表示当前查看时,总共发送到服务器的请求数。
- 最新样本:代表时间的数字,是服务器响应最后一个请求的时间。
- 平均:表示发送至服务端的,请求总数/总运行时间
- 偏离:表示服务器响应时间变化、离散程度测量值的大小。
- 吞吐量:服务器每分钟处理的请求数。
- 中间值:有一半的服务器响应时间低于改值而另一半高于该值。
- 图表左上角显示的值是响应时间第90百分位数的最大值。
官方介绍:
吞吐量数字表示服务器处理的实际请求数/分钟数。此计算包括您添加到测试中的任何延迟以及JMeter自身的内部处理时间。像这样进行计算的优点是这个数字代表了一些真实的东西 - 你的服务器实际上每分钟处理了多少请求,你可以增加线程数和/或减少延迟来发现服务器的最大吞吐量。然而,如果您的计算考虑了延迟和JMeter的处理时间,那么您可能不清楚从该数字可以得出什么结论。
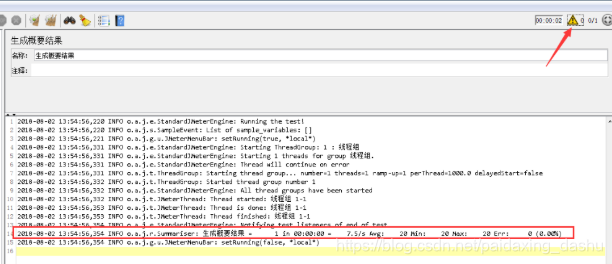
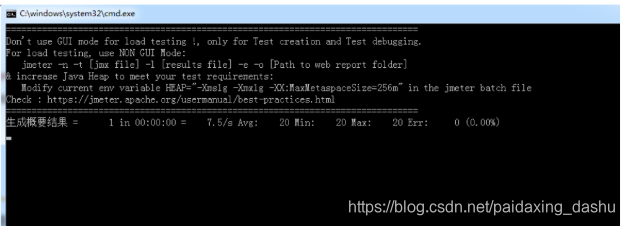
5)Generate summary results(生成概要结果)
在GUI方式执行性能测试计划时,太多的监听器会比较消耗系统资源,一般会选择在非GUI方式运行。但是在非GUI方式运行时,无法察看到测试过程中的结果。该组件可以让结果在CMD(Windows 系统下)窗口显示。
在测试计划中添加该组件,在线程组下任意地方都可以。该组件在CMD窗口默认刷新频率是30秒。
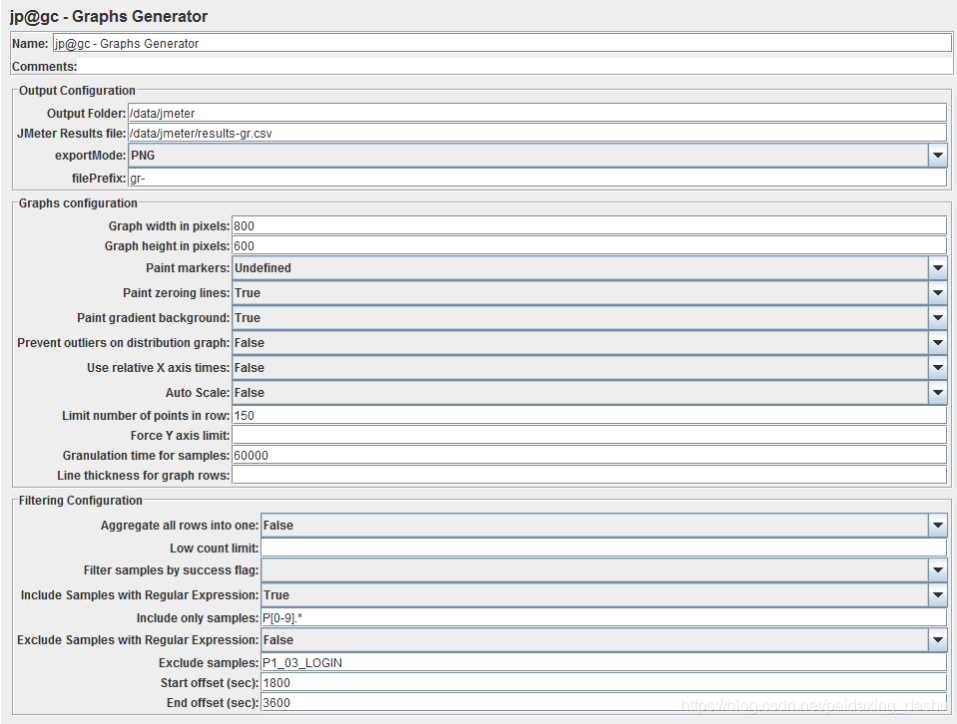
5)jp@gc - Graphs Generator 图形生成器
图形生成器侦听器在测试结束时生成以下图形:
- 随着时间的推移活动线程
- 随着时间的响应时间
- 每秒交易
- 每秒服务器点击数
- 每秒响应码
- 随着时间的响应延迟
- 随着时间推移的字节吞吐量
- 响应时间与线程
- 事务吞吐量与线程
- 响应时间分布
- 响应时间百分比
- 包含汇总报告数据的CSV文件
- 包含摘要报告数据的CSV文件
为当前测试结果生成CSV / PNG
为此,您必须确保将结果刷新到文件中,以便在运行Graphs Generator Listener时,它会对完整文件起作用。
您有2个选项:
#选项1:
配置视图结果树,以便将结果输出到文件(仅出于性能目的,仅在NON-GUI模式下使用此侦听器)
确保“查看结果树”侦听器为 之前 图生成器监听器
#选项2:
更改user.properties中的JMeter设置以确保使用了自动刷新:
jmeter.save.saveservice.autoflush = true
在这种情况下,您只需要将Graphs Generator Listener设置为仅侦听器并在NON-GUI模式下运行
为现有/先前的测试结果生成CSV / PNG
为此,您将必须创建“假”测试以触发现有文件上的侦听器。
这很简单:
用1个线程和1个迭代创建一个线程组
将调试采样器作为其子级
运行测试
PNG或CSV或两者都将为您在Graphs Generator Listener中配置的结果文件生成















 1394
1394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









