- 简介
- 代码实现
- 总结
一.简介
在检索当中,主要涉及了两个核心问题:
I.相似度计算
II.索引的建立
索引建立参考链接:
http://blog.csdn.net/malefactor/article/details/7256305
这里我们重点讲解第一个问题
1.1整体流程如图:
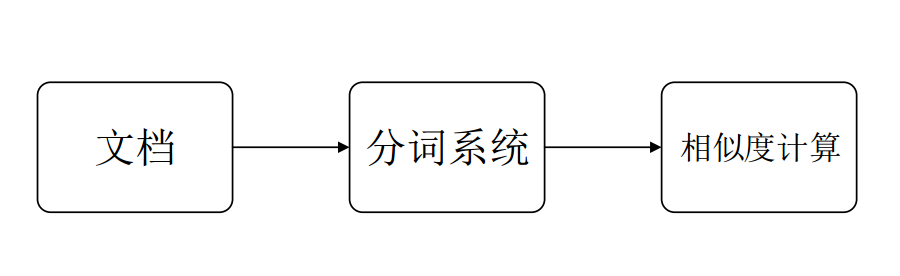
1.2在整个流程当中,第二步骤和第三步骤对于效果影响很多,故此很关键
相似度的vsm经典模型流程如图:

经过第三步骤处理后,文档在词典当中均有唯一的表示-表示为一个长向量的形式
第四步骤参考链接:
http://blog.csdn.net/u010598982/article/details/50876831
二.代码实现
import math
import ast
from collections import Counter
wordsCount=0
def CountKeyByWen(fileName1):
global wordsCount
f1=open(fileName1,'r')
f2=open(fileName2,'r')
table={}
for lines in f1:
for line in lines.split(' '):
if line!=' ' and table.has_key(line):
table[line]+=1
wordsCount+=1
elif line!=' ':
wordsCount+=1
table[line]=1
dic = sorted(table.iteritems(),key= lambda asd:asd[1], reverse=True)
return dic
def CreateVocabulary(dic1=None, dic2=None):
vocabulary=[]
for dicEle in dic1:
if dicEle[0] not in vocabulary:
vocabulary.append(dicEle[0])
for dicEle in dic2:
if dicEle[0] not in vocabulary:
vocabulary.append(dicEle[0])
return vocabulary
def ComputeVector(dic1=None,vocabulary=None):
dicVector = {}
for elem in vocabulary:
dicVector[elem]=0
dicTemp1,dicTemp2=Counter(dicVector), Counter(dic1)
dicTemp=dict(dicTemp1+dicTemp2)
return dicTemp
def ComputeSimlirity(dic1Vector=None,dic2Vector=None):
x=0.0
y1=0.0
y2=0.0
for k in dic1Vector:
temp1=(float)(float(dic1Vector[k])/float(wordsCount))
temp2=(float)(float(dic2Vector[k])/float(wordsCount))
x=x+ (temp1*temp2)
y1+=pow(temp1,2)
y2+=pow(temp2,2)
return x/math.sqrt(y1*y2)
if __name__=='__main__':
fileName1='amanda_all.txt';
fileName2='amanda_all.txt';
dic1 = CountKeyByWen(fileName1)
dic2 = CountKeyByWen(fileName2)
vocabulary = CreateVocabulary(dic1, dic2)
dic1Vector = ComputeVector(dic1, vocabulary)
dic2Vector = ComputeVector(dic2, vocabulary)
for elem in dic1Vector:
print "<"+elem[0],',',str(elem[1])+">"
sim=ComputeSimlirity(dic1Vector,dic2Vector)
print sim
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
tips:上面的code有人提示楼主有问题,遂做修改,欢迎大家批评指正哈!修改代码如下:
import math
import ast
from collections import Counter
wordsCount=0
def CountKeyByWen(fileName1):
global wordsCount
f1=open(fileName1,'r')
f2=open(fileName2,'r')
table={}
for lines in f1:
for line in lines.split(' '):
if line!=' ' and table.has_key(line):
table[line]+=1
wordsCount+=1
elif line!=' ':
wordsCount+=1
table[line]=1
return table
def CreateVocabulary(dic1=None, dic2=None):
vocabulary=[]
for dicEle in dic1:
if dicEle not in vocabulary:
vocabulary.append(dicEle)
for dicEle in dic2:
if dicEle not in vocabulary:
vocabulary.append(dicEle)
return vocabulary
def union_dict(*objs):
_keys = set(sum([obj.keys() for obj in objs],[]))
_total = {}
for _key in _keys:
_total[_key] = sum([obj.get(_key,0) for obj in objs])
return _total
def ComputeVector(dic1=None,vocabulary=None):
dicVector = {}
for elem in vocabulary:
dicVector[elem]=0
dicTemp=union_dict(dicVector,dic1);
return dicTemp
def ComputeSimlirity(dic1Vector=None,dic2Vector=None):
x=0.0
y1=0.0
y2=0.0
for k in dic1Vector:
temp1=(float)(float(dic1Vector[k])/float(wordsCount))
temp2=(float)(float(dic2Vector[k])/float(wordsCount))
x=x+ (temp1*temp2)
y1+=pow(temp1,2)
y2+=pow(temp2,2)
return x/math.sqrt(y1*y2)
if __name__=='__main__':
fileName1='a.txt';
fileName2='b.txt';
dic1 = CountKeyByWen(fileName1)
dic2 = CountKeyByWen(fileName2)
vocabulary = CreateVocabulary(dic1, dic2)
dic1Vector = ComputeVector(dic1, vocabulary)
dic2Vector = ComputeVector(dic2, vocabulary)
for elem in dic1Vector:
print "<"+elem,',',str(dic1Vector[elem])+">"
sim=ComputeSimlirity(dic1Vector,dic2Vector)
print "similarity="+str(sim)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
三.总结
I.任何事情均通于天道地道,都有一个积累的过程,努力是成功的必要前提条件II.让我们一同努力,明天会更好!
转载地址























 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









