









向量空间模型(Vector Space Model)是一个常用的相似度计算模型,lucene排序模型中使用了向量空间模型,下面结合搜索引擎排序过程中query和文档相关性计算来说明向量空间模型。
搜索引擎可以为搜索请求的query返回一大堆相关的文档(通常是关键字匹配了的文档),但是需要对这些文档按与query的相关性进行排序。对于文档d,和query q,我们需要把它们表示成方便后续计算的一个向量,我们以搜索引擎索引词典为基准,将词典中所有的词作为一个标准向量T=(t1,t2,...,tN),我们把文档d表示成d=(m1,m2,...,mN),query q表示成向量q=(n1,n2,...,nN),mi和ni分别表示d和q中ti出现的频率。有很多种方法计算d和q的相关性,包括:

其中计算内积(dot)的方法直接利用频率来计算,没有进行规范化,计算的相关性值范围很广,其他几个进行了规范化,结果值在0-1之间。向量空间模型采用Cosine的计算方法。但是还有一个问题,如果我们直接拿向量d和q来计算它们的cosine值,由于d和q都使用的是频率。这样,如果d是一篇长文档,里面几乎包含了q中所有的关键字,而且频率比较高,这样d和q的相似度就比较高了;相反,如果d是一篇短文档,与q中关键字重叠的频率比较低,那样q和d的相关性就不高了。实际上,这是不合理的,例如文档I中含有10000个词,而词a出现了10次;文档II中含有100个词,而a出现了5次。这样在相似度计算时,文档I中a对最后结果的影响比文档II中的a要大。这显然是不合理的,因为a只点文档I的0.1%而却占文档II的5%。为了解决这类问题,我们引入词频(TF)和反词频(IDF)两个概念,给文档和query中词加权重。
tf-idf是基于这样的一个基本思路的:如果词t在文档中出现的次数比较高,并且文档库中包含词t的文档数比较少,这样词t的权重就比较大。
文档d的权重向量表示成 ,其中
,其中
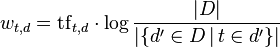
并且
 是t在文档d中出现的词频(局部变量)
是t在文档d中出现的词频(局部变量) 反转文档词频(Inverse document frequency) (全局变量).
反转文档词频(Inverse document frequency) (全局变量).  是文档库中文档总数;
是文档库中文档总数; 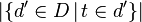 是包含词t的文档数.
是包含词t的文档数.
使用consine 计算文档dj 和query q的相似度:

需要讨论的问题——向量维度为什么要以语料库中的所有词为基准,这样维度势必很高,计算复杂度不就非常高吗?
这样维度确实很高,但是我们反过来想一下,如果不以语料库中的所有词为基准,有三种标准:以query中的词为基准、以文档d中的词为基准和以query和文档词的并集为基准。前两种情况很明显是不合理的,因为q中词d中不一定有,反之,d中的词q中不一定有,这样单方面考虑维度是不合理的。第三种方法看似合理,但是实际操作起来很不合理,因为每次query请求都要计算每篇文档d和query的并集,显然不切实际。因此需要以语料库中的所有词为基准,如前面看到的,可以事先计算好idf。
并且我们可以按照如下方法来降维:
去停用词
英文单词转词根形式
只选取名词
选择次数较多的词作为term














 3312
3312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









