



一、安装及配置
1、slowfast 源码下载
2、创建虚拟环境,一定要装python3.8,不然后面会报错。
conda create -n slowfast python=3.8
conda activate slowfast3.安装pytorch等,pytorch版本一定不要用最新版,会报很多错,用老一点的更好。我一开始用了最新版,后面装着装着就一堆错,经过多次卸载安装再卸载再安装,终于调试出适合我的配方。没有别的办法,多尝试就行。
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.1 pytorch-cuda=11.8 -c pytorch -c nvidia4.安装别的包,其中要连github的需要连外网,此处教程较多,可以多搜索,多尝试。
pip install -U torch torchvision cython
pip install -U git+https://github.com/facebookresearch/fvcore.git
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
git clone https://github.com/facebookresearch/detectron2 detectron2_repo
pip install -e detectron2_repo5.构建SlowFast,用pycharm 打开工程文件,在terminal 中输入以下代码,需关闭外网
python setup.py build develop 6. 修改setup.py,主要是替换 PIL 和 sklearn,否则也会有报错
#!/usr/bin/env python3
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
from setuptools import find_packages, setup
setup(
name="slowfast",
version="1.0",
author="FAIR",
url="unknown",
description="SlowFast Video Understanding",
install_requires=[
"yacs>=0.1.6",
"pyyaml>=5.1",
"av",
"matplotlib",
"termcolor>=1.1",
"simplejson",
"tqdm",
"psutil",
"matplotlib",
"detectron2",
"opencv-python",
"pandas",
"torchvision>=0.4.2",
# "PIL",
"pillow",
# "sklearn",
"scikit-learn",
"tensorboard",
"fairscale",
],
extras_require={"tensorboard_video_visualization": ["moviepy"]},
packages=find_packages(exclude=("configs", "tests")),
)
7.继续安装包
pip install scikit-learn
pip install pillow8. 在工程下新建两个文件夹 vinput 和voutput ,把测试视频放到vinput下
E:\abnormal action detect\slowfast\SlowFast-main\vinput
E:\abnormal action detect\slowfast\SlowFast-main\output
9.下载预训练权重
https://github.com/facebookresearch/SlowFast/blob/main/MODEL_ZOO.md
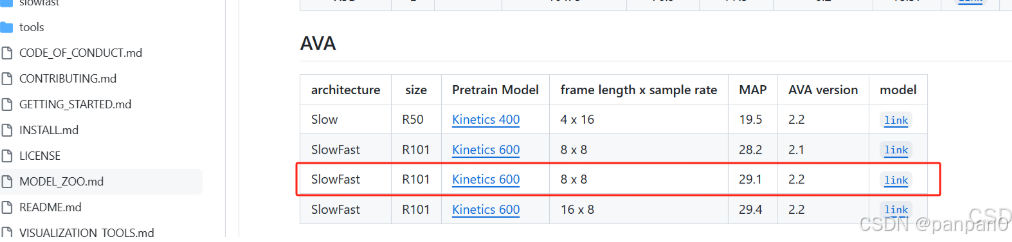
10.新建一个my.json文件,
放到E:\abnormal action detect\slowfast\SlowFast-main\demo\my.json下,即你的工程目录下
{
"bend/bow (at the waist)": 0,
"crawl": 1,
"crouch/kneel": 2,
"dance": 3,
"fall down": 4,
"get up": 5,
"jump/leap": 6,
"lie/sleep": 7,
"martial art": 8,
"run/jog": 9,
"sit": 10,
"stand": 11,
"swim": 12,
"walk": 13,
"answer phone": 14,
"brush teeth": 15,
"carry/hold (an object)": 16,
"catch (an object)": 17,
"chop": 18,
"climb (e.g., a mountain)": 19,
"clink glass": 20,
"close (e.g., a door, a box)": 21,
"cook": 22,
"cut": 23,
"dig": 24,
"dress/put on clothing": 25,
"drink": 26,
"drive (e.g., a car, a truck)": 27,
"eat": 28,
"enter": 29,
"exit": 30,
"extract": 31,
"fishing": 32,
"hit (an object)": 33,
"kick (an object)": 34,
"lift/pick up": 35,
"listen (e.g., to music)": 36,
"open (e.g., a window, a car door)": 37,
"paint": 38,
"play board game": 39,
"play musical instrument": 40,
"play with pets": 41,
"point to (an object)": 42,
"press": 43,
"pull (an object)": 44,
"push (an object)": 45,
"put down": 46,
"read": 47,
"ride (e.g., a bike, a car, a horse)": 48,
"row boat": 49,
"sail boat": 50,
"shoot": 51,
"shovel": 52,
"smoke": 53,
"stir": 54,
"take a photo": 55,
"text on/look at a cellphone": 56,
"throw": 57,
"touch (an object)": 58,
"turn (e.g., a screwdriver)": 59,
"watch (e.g., TV)": 60,
"work on a computer": 61,
"write": 62,
"fight/hit (a person)": 63,
"give/serve (an object) to (a person)": 64,
"grab (a person)": 65,
"hand clap": 66,
"hand shake": 67,
"hand wave": 68,
"hug (a person)": 69,
"kick (a person)": 70,
"kiss (a person)": 71,
"lift (a person)": 72,
"listen to (a person)": 73,
"play with kids": 74,
"push (another person)": 75,
"sing to (e.g., self, a person, a group)": 76,
"take (an object) from (a person)": 77,
"talk to (e.g., self, a person, a group)": 78,
"watch (a person)": 79
}
11.修改yaml文件
E:\abnormal actiondetect\slowfast\SlowFastmain\demo
\AVA\SLOWFAST_32x2_R101_50_50.yaml
主要有以下几个地方:
(1)CHECKPOINT_FILE_PATH: 预训练权重路径
(2)LABEL_FILE_PATH:
(3)INPUT_VIDEO:
(4)OUTPUT_FILE:
(5)注释以下三行代码:
#TENSORBOARD: # MODEL_VIS: # TOPK: 2 (6)注释以下代码 # WEBCAM: 0
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 16
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
#CHECKPOINT_FILE_PATH: ./SLOWFAST_32x2_R101_50_50.pkl #path to pretrain model 预训练模型的路径
CHECKPOINT_FILE_PATH: E:\abnormal action detect\slowfast\SlowFast-main\SLOWFAST_32x2_R101_50_50.pkl
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
#TENSORBOARD:
# MODEL_VIS:
# TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: "E:\\abnormal action detect\\slowfast\\SlowFast-main\\demo\\my.json " # Add local label file path here.
INPUT_VIDEO: "E:\\abnormal action detect\\slowfast\\SlowFast-main\\vinput\\2.mp4"
OUTPUT_FILE: "E:\\abnormal action detect\\slowfast\\SlowFast-main\\voutput\\2out.mp4"
#WEBCAM: 0
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: detectron2://COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl
12. 运行
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50.yaml新手要注意,此处在pycharm 终端运行时,一定要将终端切换到虚拟环境下,具体切换方法见
PyCharm的终端(terminal)中进入指定conda虚拟环境_pycharm配置conda终端-CSDN博客
如果此时能跑通,那你将是幸运儿,不过大概率是跑不通的,会有很多莫名其妙的问题,好在大多数bug网上都能搜到解决办法,感谢辛苦写经验贴的技术达人们。
接下来我也分享几个我碰到的比较麻烦的bug:
二、Bug大修复
1、第一个大天坑 :No module named 'torch._six'
这个问题耗费了我大量时间,解决办法分为几步:
(1)一开始安装环境时,pytorch版本不能太高,并且要和torvision 匹配,匹配问题见前人分享的经验贴
PyTorch中torch、torchvision、torchaudio、torchtext版本对应关系_torch2.0.1对应的torchvision-CSDN博客
(2)但很快你会发现,就算版本匹配好后,运行还是出现No module named ‘torch._six ‘
解决办法,将build/lib/slowfast/datasets/multigrid_helper.py文件中的from torch._six import int_classes as _int_classes修改为from torch import int_classes as _int_classes (对我没用)
或者直接注释掉from torch._six import int_classes as _int_classes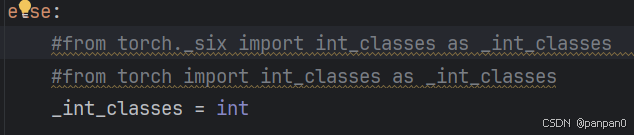
(3)完成上一步后会悲催的发现,问题还是没有解决,原因是报错的不在本地工程文件下,而是虚拟环境下。在本地工程下进行第二步修改,并不能解决这个bug,比如我安装时就一直提示下面这个文件出错
D:\miniconda3\envs\slowfast\Lib\site-packages\ slowfast-1.0-py3.8.egg!\slowfast\datasets\multigrid_helper.py
这个文件不好找,并且用pycharm打开后,发现slowfast-1.0-py3.8.egg这个文件夹下的文件不能编辑,以为是权限问题,找了半天还是不能解决。
冥思苦想,又借助kimi, 想到了一个粗暴的解决办法。slowfast-1.0-py3.8.egg其实是一个压缩文件,用7-zip 打开后,将ultigrid_helper.py复制出来,然后用Pycharm打开,修改该文件下的from torch._six import int_classes as _int_classes语句,保存。此时一定要把pycharm关闭,然后将修改后ultigrid_helper.py文件拖进slowfast-1.0-py3.8.egg压缩包里,覆盖掉原文件,便可完成修改。
2、No module named ‘vision’
解决:这就是二个天坑,他的模块放置的位置不在他写的这个地址,需要手动去修改.
而且有几个地方
第一个地方,run_net.py下
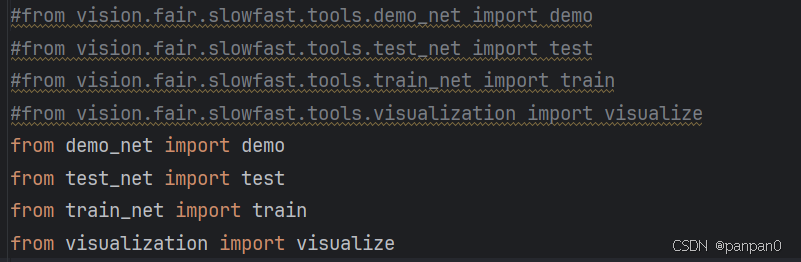
第二个地方,
将vision.fair.slowfast.ava_evaluation替换为‘ava_evaluation’就可以了,这个地方也有在虚拟环境下的,不过此处可以在pycharm中直接修改
import slowfast.utils.distributed as du
from slowfast.utils.env import pathmgr
from vision.fair.slowfast.ava_evaluation import (
object_detection_evaluation,
standard_fields,
)
#修改为
import slowfast.utils.distributed as du
from slowfast.utils.env import pathmgr
from ava_evaluation import (
object_detection_evaluation,
standard_fields,
)3. 一运行就出现AttributeError: 'NoneType' object has no attribute 'loader'
这个bug不影响运行,但是影响观感,参考pip install pyomo 损坏了 python3 virtualenv ·问题 #95 ·Pyomo/pyomo ·GitHub的
将虚拟环境下 D:\miniconda3\envs\slowfast\Lib\site-packages\vision-1.0.0-py3.7-nspkg.pth
原本只有一行代码 在 import 代码后添加一个回车,变成两行后即解决,原因未知。具体见下图
import sys, types, os;
has_mfs = sys.version_info > (3, 5);p = os.path.join(sys._getframe(1).f_locals['sitedir'], *('vision',));importlib = has_mfs and __import__('importlib.util');has_mfs and __import__('importlib.machinery');m = has_mfs and sys.modules.setdefault('vision', importlib.util.module_from_spec(importlib.machinery.PathFinder.find_spec('vision', [os.path.dirname(p)])));m = m or sys.modules.setdefault('vision', types.ModuleType('vision'));mp = (m or []) and m.__dict__.setdefault('__path__',[]);(p not in mp) and mp.append(p)
3、总是提示以下信息
"The 'torchvision.transforms._functional_video' module is deprecated since 0.12 and will be removed in the future. " "Please use the 'torchvision.transforms.functional' module instead."
解决方法
切换到D:\miniconda3\envs\slowfast\Lib\site-packages\torchvision\transforms\_transforms_video.py文件下的
将from . import _functional_video as F手动修改为
from . import functional as F
花了整整一天的时间终于搞定了第一个demo。其中遇见的bug不下20个,只能耐心一个个上网查寻解决办法,很多问题还是一知半解,不过能成功运行就是胜利,希望我的经验能给需要的人一点帮助,同时也方便自己后续查找。这也是我写这篇博客的初衷。


















 1101
1101







 到【灌水乐园】发言
到【灌水乐园】发言







