







re模块
1.compile 使用任何可选的标记来编译正则表达式的模式,然后返回一个正则表达式对象
2.match 如果匹配成功,就返回匹配对象;如果失败,就返回 None
3.search 使用可选标记搜索字符串中第一次出现的正则表达式模式。如果匹配成功,则返回匹
4.findall 查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表
4.finditer 返回一个迭代器,多用于遍历内容,校验返回内容,进而做其他操作
5.split(pattern,string,max=0) 根据正则表达式的模式分隔符,split 函数将字符串分割为列表,然后返回成功匹配的 列表,分隔最多操作 max 次
6. sub(pattern,repl,string,count=0) 使用 repl 替换所有正则表达式的模式在字符串中出现的位置,除非定义 count,否则就 将替换所有出现的位置(另见 subn()函数,该函数返回替换操作的数目)
7. group(num=0) 返回整个匹配对象,或者编号为 num 的特定子组
示例:
match:
m = re.match('foo', 'food on the table') # 匹配成功
m = re.match('foo', 'seafood') # 匹配失败
m = re.match('(\w\w\w)-(\d\d\d)', 'abc-123') #匹配子组,一个()代表一个子组,结合group()查看返回
search:
m = re.search('foo', 'seafood') # 使用 search() 代替,serch只能搜索第一个

findall:
相比于search,findall()适用于查询所有匹配的字符串

忽略大小写: ?! 相当于re.I
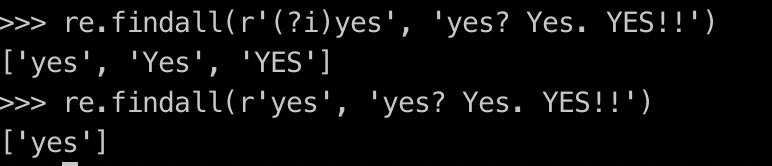
re.M/MULTILINE 实现多行混合 ?m
?:... 取...之后匹配的值

?=...取...之前的配置

finditer()

import re
s = 'this is that'
for g in re.finditer(r'(th\w+)',s,re.I):
print(g.group(1))
if g.group(1)=='that':
print('hello:',g.group(1))

sub和subn区别:subn会返回替换的个数

split使用
















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









