






 论文提出了MoDem框架,通过策略预训练、种子数据集和交互学习阶段,利用少量演示提升基于模型的强化学习在视觉控制任务中的样本效率。这种方法在低数据条件下,相对于以前的方法,成功率提高了160%至250%。
论文提出了MoDem框架,通过策略预训练、种子数据集和交互学习阶段,利用少量演示提升基于模型的强化学习在视觉控制任务中的样本效率。这种方法在低数据条件下,相对于以前的方法,成功率提高了160%至250%。
之前看了一篇文章,浅浅(机器)翻译一下,关于强化学习的概念会加一些自己的理解,刚接触强化学习,对于文章的算法不做深入思考,请多批评指正。代码和视频链接:https://nicklashansen.github.io/modemrl论文https://arxiv.org/abs/2212.05698
论文整体理解
这篇论文的目的是:训练得到一个模型,可以提高完成视觉控制任务的成功率。前置条件:在低样本下
摘要
糟糕的样本效率仍然是为现实应用部署深度强化学习(RL)算法的主要挑战,特别是对于视觉运动控制。基于模型的RL通过同时学习世界模型和使用综合推出进行规划和政策改进,具有高度的样本效率。然而,在实践中,基于模型的RL的样本高效学习受到了探索挑战的瓶颈。在这项工作中,我们发现,仅利用少量的演示,就可以显著提高基于模型的RL的样本效率。然而,简单地向交互数据集附加演示程序是不够的。我们确定了利用模型学习中的演示的关键要素——策略预训练、有针对性的探索和演示数据的过采样——这形成了我们基于模型的RL框架的三个阶段。我们对三个复杂的视觉-运动控制领域进行了实证研究,发现我们的方法比之前在低数据条件下的方法完成稀疏奖励任务的成功率高出160% ~ 250%(100K个交互步骤,5个演示程序)。
理解:上述摘要说了本文的贡献是在训练模型的框架上做了改进,(1)先做了预训练 (2)针对性探索 (3)交互学习中采样演示数据
引言
强化学习(RL)为未知环境中的训练代理提供了一个有原则和完整的抽象。然而,现有算法的样本效率较低,使得它们无法适用于现实世界的任务,如机器人的对象操作。这在视觉-运动控制任务中进一步加剧,这些任务同时提出了视觉表征学习和运动控制的挑战。基于模型的强化学习(MBRL)原则上(布拉夫曼&田宁霍兹,2002年)可以通过同时学习世界模型和政策来提高RL的样本效率(Ha &施米德胡伯,2018年;施里特维瑟等人,2020年;Hafner等人,2020年;汉森等人,2022年)。使用学习模型的假想部署可以减少对真实环境交互的需求,从而提高样本效率。然而,一系列的实际挑战,如探索的困难,对有形奖励的需要,以及对高质量的视觉表现的需求,阻碍了MBRL实现其全部潜力。在这项工作中,我们试图从实际的角度来克服这些挑战,并且我们建议通过使用专家演示来加速MBRL。
理解:我们这篇文章应该知道强化学习的概念,强化学习是解决一类题,在交互中学习,提高完成任务的成功率。我们应该理解environment、agent、reward、action的概念。通过奖励机制,让agent不断迭代达到目的。
视觉-运动控制任务的专家演示可以使用人类远程操作、动觉教学或脚本策略来收集。虽然这些演示提供了学习复杂行为的直接监督,但由于人力成本和所需的专业知识程度,它们很难大量收集(Baker et al.,2022)。然而,即使是少量的专家演示也可以通过规避与探索相关的挑战来显著加速RL。先前的工作(Rajeswaran et al., 2018;Shah & Kumar, 2021; Zhan et al., 2020)已经在无模型RL(MFRL)算法的背景下研究了这一点。在这项工作中,我们提出了一个新的框架来加速基于模型的RL算法与演示。在一系列具有挑战性的视觉-运动控制任务中,我们发现我们的方法可以训练出近似的策略。比之前最先进的(SOTA)基线成功160% % 250%。
理解:在强化学习中分了两大类,model-free无模型和model-based基于模型的,论文针对后者做了训练策略的改进。无模型训练更慢,但是在学习改变的真实环境中更容易,有模型训练快,但是环境变化后效果不好。
off-policy非策略RL算法(Sutton & Barto,1998)——包括基于模型的和无模型的——原则上可以允许重放缓冲区中的任何数据集。因此,我们很容易地将演示附加到代理的重放缓冲区中。然而,我们证明了这是一个糟糕的选择(见第4节),因为agent仍然从一个随机策略开始,并且在环境中学习时必须慢慢地合并演示中固有的行为先验。简单地通过行为克隆来初始化策略(Pomerleau,1988),演示也是不够的。任何未来对政策的学习都直接受到世界模型和/或批评者的质量的影响——其中的训练需要足够的探索性数据集。为了克服这些挑战,并实现稳定、单调、但样本高效的学习,我们提出了基于模型的演示强化学习(MoDem),这是一个三阶段的基于视觉模型的RL框架,只使用少量的演示。我们的框架总结在图2中,它包括:
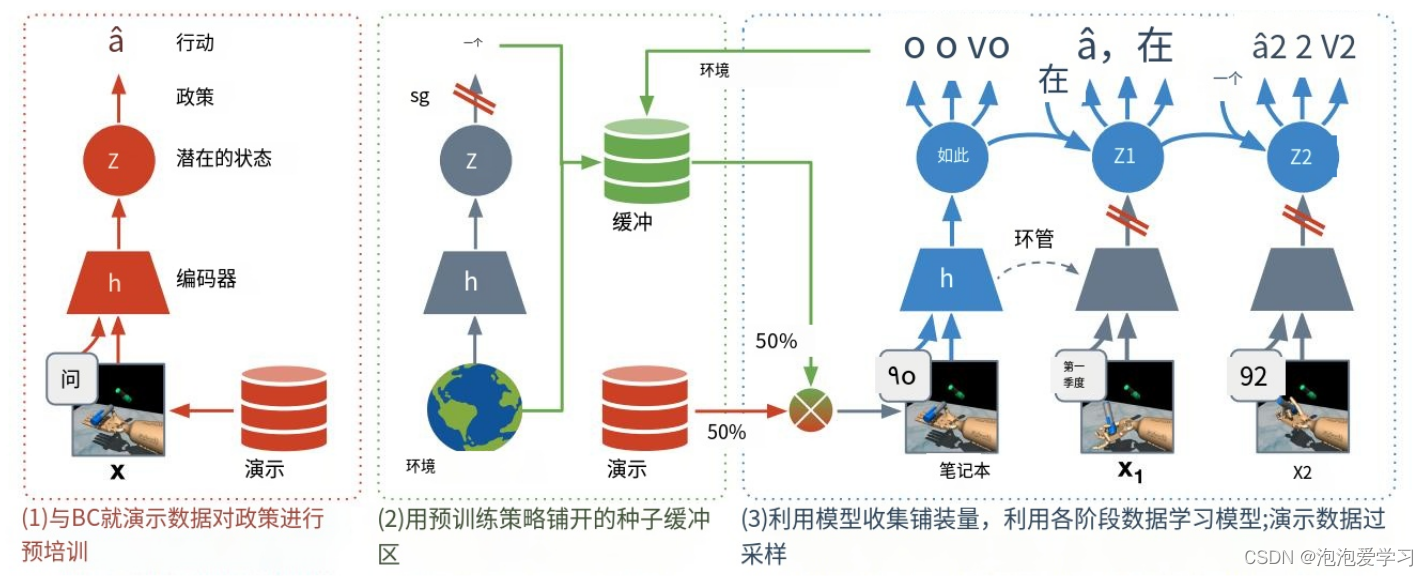
(1)阶段1:策略预训练,其中通过行为(BC)克隆在演示数据集上对视觉表示和策略进行预训练。虽然这种预训练本身并不能产生成功的策略,但它通过初始化提供了一个强大的先验。
理解BC: behavior cloning,简答的模仿学习,模仿专家的动作(演示)来学习policy。没有奖励机制。
(2)阶段2:播种,其中预先训练的策略,增加了探索,用于从环境中收集一个小的数据集。该数据集用于预先训练世界模型和批评者。经验上,预先训练的政策收集的数据比之前的随机策略更有用,也是我们工作成功的关键,因为它确保了世界模型和批评者从演示提供的归纳偏见中获益。如果没有这一阶段,交互式学习可能会在培训的前几次迭代后迅速导致政策崩溃,从而抹去政策预培训的好处。
理解探索-利用:探索:在智能体不断执行动作的到奖励的过程中,探索是指寻找寻新的动作-路径来获取最优的策略,但是不可能遍历所有,探索的代价很大。利用:是指利用当前反馈的信息选择最好的结果。两者需要平衡。
(3)阶段3:使用交互式学习进行微调,我们使用综合推出交织策略学习,使用来自所有三个阶段的数据,包括新环境交互的世界模型学习。至关重要的是,我们在世界模型学习过程中积极地对演示数据进行过度采样,并在所有阶段使用数据增强进行规范化。
我们的贡献我们在这项工作中的主要贡献是MoDem的开发,我们评估了来自Adroit (Rajeswaran等人,2018)和Meta-World (Yu等人,2019)套件的18个具有挑战性的视觉操作任务,这些任务只有稀疏奖励,以及来自DMControl (Tassa等人,2018)的运动任务,这些任务使用密集奖励。在100K交互步骤(仅使用5个演示)后,以策略成功来衡量,与强基线相比,MoDem的相对成功率提高了160% % 250%,绝对成功率提高了38% % 50%。通过在广泛的经验评估中,我们还阐明了调制解调器每个阶段的重要性,以及数据增强和预训练的视觉表示的作用。
准备工作
我们首先形式化我们的问题设置,然后介绍两种算法,TD-MPC和行为克隆(BC),这两种算法之前分别被提出用于在线RL和模仿学习,它们都是我们工作的核心。
问题设置:我们将和环境之间的相互作用建模为一个定义为元组的无限水平马尔可夫决策过程(MDP)M := <S, A, T , R, γ>, where S ∈ Rn, A ∈ Rm,是连续的状态和动作空间,, T : S × A → S是环境变迁的过程,R: S ×A → R 是一个标量奖励函数,γ ∈ [0, 1),是一个折扣参数(我理解是影响因子)。T和R假设是不知道的。智能体的目标是学习策略πθ:S→A实现较好的表现,同时使用跟环境较少的交互,这个指的是样本效率。
这项工作中,我们更具体地关注具有稀疏奖励的高维mdp。这是由机器人和体现智能的应用,其中状态不是直接观察到的,但可以通过组合很好地近似:s = (x, q),其中,x表示agent摄像机观察到的堆叠RGB图像,q表示本体感觉信息,如机器人的关节姿态。此外,现实世界应用程序的脚本(Singh等,2019),或导致不可取的人工制品或行为(Amodei等,2016;Burda等,2019年)(没太懂,不过不影响理解)。因此,我们希望用简单的稀疏奖励来学习,从而准确地捕获任务的完成情况。**在这种MDPs中,样本高效学习的主要挑战是由于稀疏奖励而进行的探索,以及学习高维状态空间(如图像)的良好表示。*为了帮助克服这些挑战,我们假设可以获得少量成功的演示轨迹Ddemo := {D1, D2, . . . , DN },通过人的远程操作、动觉教学或其他手段获得的(理解是预训练时使用的演示)*。我们的目标是通过使用所提供的演示轨迹来加速学习过程,从而使用最小的环境交互作用来学习一个成功的策略。
行为克隆(BC)是一个简单而广泛使用的模仿学习(IL)框架。这完全依赖于Ddemo,如果能够训练成功的策略,它将提供一个理想的场景——因为它导致的交互样本复杂度为零。BC训练一个参数化策略πθ:S→a来从相应的观察中预测所证明的行动(波莫洛,1988;Atkeson & Schaal,1997)。由于协变量转移而知,使用小数据集的行为克隆具有挑战性(Ross等人,2011a;拉杰斯瓦兰等人,2018年)和视觉表征学习的挑战(Parisi等人,2022年;Nair等人,2022年)。此外,由于需要人力成本和专业知识,收集大型演示数据集往往是不可行的(Baker等人,2022年)。更重要的是,BC不能超越演示者的能力,因为它缺乏任务成功的概念。总之,这些考虑促使我们需要将演示与样本高效RL结合起来。
TD-MPC(Hansen et al.,2022)是一种基于模型的RL算法,它结合了模型预测控制(MPC)、一个学习的潜在空间世界模型和一个通过时间差异(TD)学习学习的终端值函数。具体来说,TD-MPC学习了一个表示z = hθ(s),它将高维状态(s)映射为一个紧凑的表示,以及在这个潜在空间z0 = dθ(z,a)中的一个动力学模型。此外,TD-MPC还学习预测头,Rθ,Qθ,πθ,用于: (i)瞬时奖励r = Rθ(z,a),(ii)状态动作值Qθ(z,a),和(iii)动作a∼πθ(z)。政策πθ用于“指导”规划朝向高回报的轨迹,并被优化以最大化时间加权的q值。其余的组成部分被共同优化,以最小化td错误、奖励预测错误和潜在的状态预测错误。其目标是由
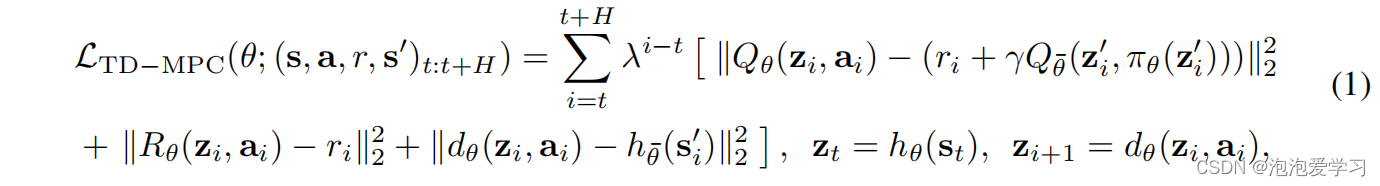
其中,θ¯是θ的指数移动平均数,s0t,z0t是时间t + 1时的(潜在)状态。在环境交互过程中,TD-MPC使用基于样本的规划器(Willimmsetal.,2015)结合学习的潜在世界模型和价值函数(评论家)进行行动选择。有关TD-MPC的其他背景信息,请参见附录B。我们使用TD-MPC作为我们选择的可视化MBRL算法,因为它的简单性和强大的经验性能(见附录D),但我们的框架,在原则上,可以用任何MBRL算法实例化。
理解TD-MPC就是整个训练框架的第二步
基于模型的强化学习与演示
在这项工作中,我们的目标是通过少量的演示来加速基于(可视化)模型的RL的样本效率。为此,我们提出了基于模型的演示强化学习(MoDem),这是一个在严格的环境交互预算下使用的简单而直观的视觉RL框架。图2提供了我们的方法的概述。MoDem由三个阶段组成: (1)政策预训练阶段政策训练一些演示通过行为克隆,(2)播种阶段预先训练的策略用于收集一个小数据集针对世界模型的学习,和(3)交互式学习阶段代理迭代收集新数据和改进使用所有阶段的数据,特别强调演示数据。下面我们将更详细地描述每个阶段。
第一阶段:策略预训练。我们首先从演示数据集Ddemo学习一个策略:={D1D2…其中每个演示Di由{s0,a0,s1,a1…sT,aT}。一般来说,演示可能是有噪声的或次优的——我们没有明确地做出任何最优性假设。设hθ:S→Rl表示编码器,πθ:Rl→A表示从潜在状态表示映射到动作空间的策略。在阶段1中,我们使用一个行为克隆目标对策略和编码器进行预训练,由
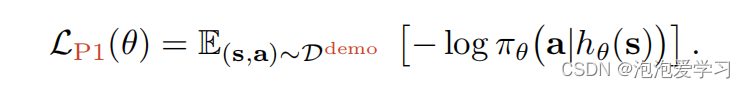
当πθ(·|z)由各向同性高斯分布参数化时,如实践中常用的,等式2.简化为标准的MSE损失。如第2节所述,使用小型演示数据集进行行为克隆是困难的,特别是从高维视觉观察中(Duan等人,2017;Jang等人,2021年;Parisi等人,2022年)。在第4节中,我们确实表明,行为克隆并不能单独为我们研究的环境和数据集训练成功的策略,即使使用预先训练的视觉表示(Parisi等人,2022;Nair等人,2022)。然而,政策预训练可以提供强大的归纳先验,从而促进在下面概述的后续阶段中的样本高效适应(Peters et al.,2010)。

第二阶段:seed播种。在上一个阶段,我们只对策略进行了预训练。在第二阶段中,我们的目标也是对批评者和世界模型进行预训练,这需要一个有充分探索的“播种”数据集。在TD-MPC等算法中,随机策略通常用于收集这样的数据集。然而,对于具有稀疏奖励的视觉RL任务,随机策略不太可能产生成功的轨迹或访问状态空间中与任务相关的部分。因此,我们使用阶段1中的策略收集了一个具有附加探索的小数据集。(贡献在这里)
具体地说,给定第一阶段的πθ P1和h P1 θ,我们通过推出πθ P1(h P1 θ (s))收集了一个数据集Dseed = {τ1,τ2,…τK}。为了确保轨迹有足够的可变性,我们在动作中添加了高斯噪声(Hansen et al.,2022)。让ξt =(si,ai,ri,s0i)t+H不是一个长度为=的通用轨迹片段。在这个阶段,我们通过最小化损失来学习πθ、hθ、dθ、Rθ、Qθ——策略、表示、动态模型和价值模型
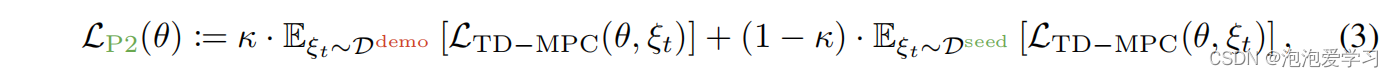
其中,κ是一个“过采样”率,它为演示数据集提供了更多的权重。综上所述,播种阶段通过数据收集和演示过采样,在环境的任务相关部分初始化世界模型、奖励和批评者方面起着关键作用。我们在第4节中发现,播种阶段对于样本高效学习是至关重要的,如果没有它,学习代理就无法在演示中最好地利用归纳先验。
第三阶段:交互学习。在对模型和策略进行初步的预训练后,我们继续使用与环境的新交互来改进代理。为此,我们从第二个阶段初始化重放缓冲区,即B←Dseed。使用演示的一种简单方法是简单地将它们附加到重放缓冲区中。然而,我们发现这在实践中是无效的,因为在线交互数据的数量很快就超过了演示。根据播种阶段,我们建议在整个训练过程中积极地对演示数据进行过采样,但在训练过程中逐步消除过采样。具体地说,我们将损失最小化
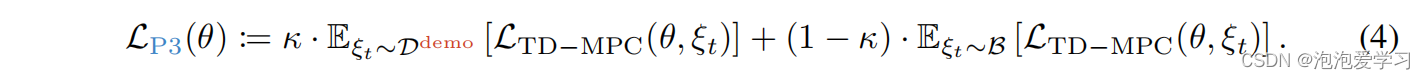
最后,我们发现使用数据增强来规范视觉表示是非常有效的,我们应用于所有阶段。我们在算法1中详细介绍了我们提出的算法。
结果和讨论
在我们的实验评估中,我们考虑了21个具有挑战性的视觉控制任务。这包括来自Adroit套件的3个灵巧的手操作任务(Rajeswaran等人,2018年),来自元世界的15个操作任务,以及来自DMControl的、涉及高维实施例的3个运动任务(Tassa等人,2018年)。图3提供了来自其中一些任务的说明性框架。对于Adroit和元世界,我们使用稀疏的任务完成奖励,而不是人类形状的奖励。我们使用DM-Control来说明MoDem提供了显著的样本效率收益,即使是对于具有密集奖励的视觉RL任务。在Meta-World中,我们研究了Seo等人(2022)分类的中等、困难和非常困难的任务。我们非常强调样本效率和评估方法,在预算只有5个演示1和100K在线交互下评估方法,这意味着Adroit中大约一个小时的真实机器人时间。我们在表1中总结了我们的实验设置。我们将开源所有在此工作中使用的所有代码、环境和演示。通过实验评价,我们旨在研究以下问题:
1.MoDem是否可以通过演示有效地加速基于模型的RL,并在具有稀疏奖励的复杂视觉RL任务中实现相同效率的学习? 是
2.现代发展每个阶段的相对重要性和贡献是什么?
3.MoDem对演示数据的来源有多敏感?
4.MoDem是否受益于使用预先训练过的视觉表征?是
结果理解:具体的实验结果就不翻译了,感兴趣可以看paper,总结就会用论文所述方法在更少的交互步骤中就得到了,更高的成功率。
回顾工作
(之前的研究工作)模仿学习、强化学习样本效率、强化学习和演示
结论
在这项工作中,我们研究了MBRL算法的加速与专家演示,以提高样本效率。我们证明,天真地将演示数据附加到MBRL代理的重放缓冲区并不能有意义地加速学习。我们开发了MoDem,一个三阶段的框架,以充分利用演示和加速MBRL。通过广泛的实验评估,我们发现MoDem在低数据机制(100K在线交互,5个演示)的稀疏奖励视觉RL任务中训练的策略成功率为250% % 350%。在这个过程中,我们还阐明了MoDem中不同阶段的重要性,数据增强对视觉MBRL的重要性,以及预先训练过的视觉表示的效用。
(翻译不易,希望有用~)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









