






题目描述
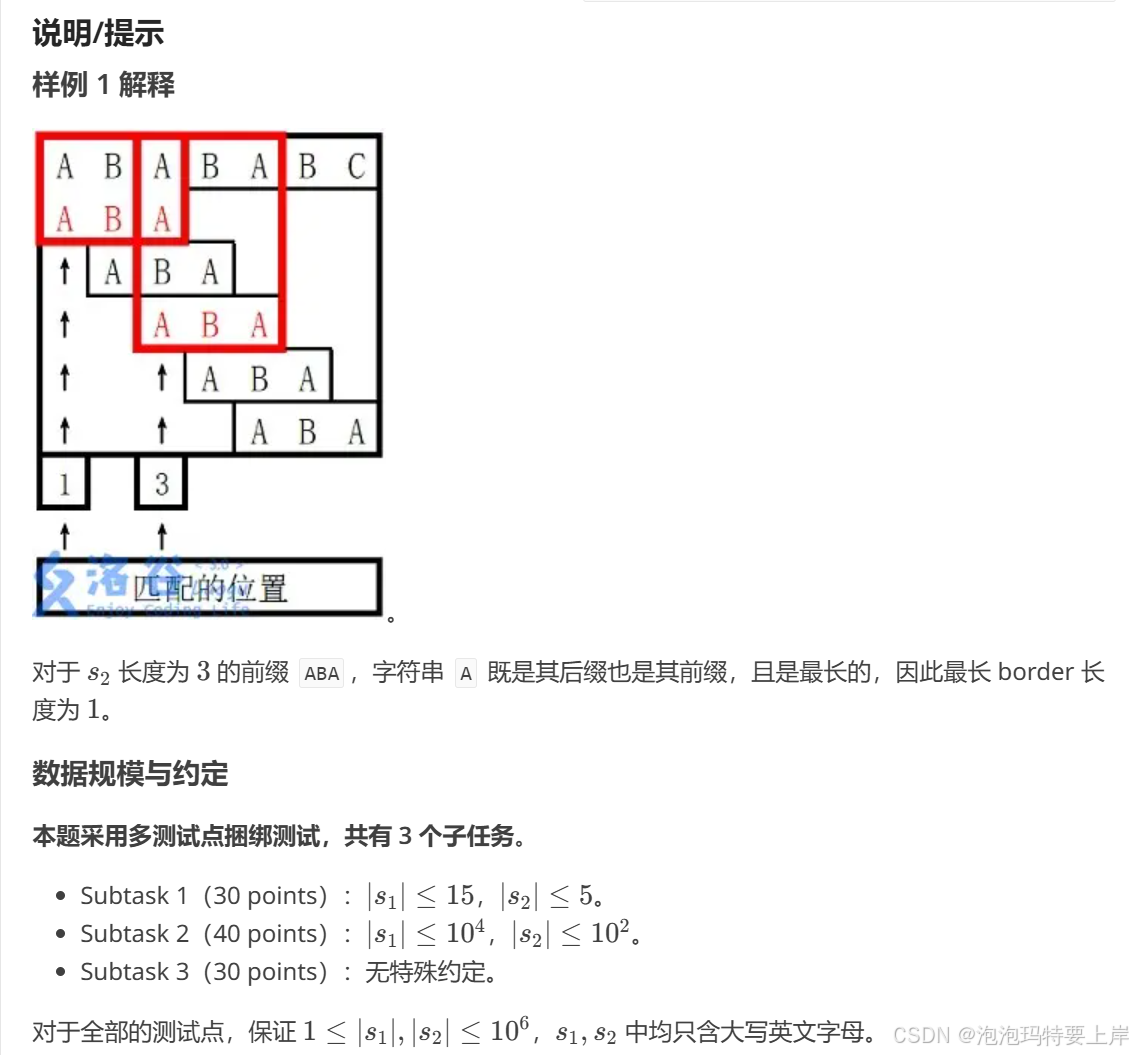
给出两个字符串 s1 和 s2,若 s1 的区间 [l,r] 子串与 s2 完全相同,则称 s2 在 s1 中出现了,其出现位置为 l。
现在请你求出 s2 在 s1 中所有出现的位置。定义一个字符串 s 的 border 为 s 的一个非 s 本身的子串 t,满足 t 既是 s 的前缀,又是 s 的后缀。
对于 s2,你还需要求出对于其每个前缀 s′ 的最长 border t′ 的长度。输入格式
第一行为一个字符串,即为 s1。
第二行为一个字符串,即为 s2。输出格式
首先输出若干行,每行一个整数,按从小到大的顺序输出 s2 在 s1 中出现的位置。
最后一行输出 ∣s2∣ 个整数,第 i 个整数表示 s2 的长度为 i 的前缀的最长 border 长度。输入输出样例
输入
ABABABC ABA输出
1 3 0 0 1
#include <bits/stdc++.h>
using namespace std;
// 计算 next 数组
void getNext(int* next, const string& s) {
int j = -1;
next[0] = j;
for (int i = 1; i < s.size(); i++) {
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不匹配
j = next[j]; // 向前退
}
if (s[i] == s[j + 1]) { // 匹配,前后缀增加
j++;
}
next[i] = j; // 保存当前匹配的前后缀长度
}
}
// KMP 主算法,查找所有匹配位置
vector<int> strStr(const string& haystack, const string& needle) {
vector<int> next(needle.size());
getNext(&next[0], needle); // 计算 needle 的 next 数组
int j = -1;
vector<int> result;
for (int i = 0; i < haystack.size(); i++) {
while (j >= 0 && haystack[i] != needle[j + 1]) {
j = next[j]; // 不匹配时,回退
}
if (haystack[i] == needle[j + 1]) {
j++; // 匹配时,j 向后移
}
if (j == needle.size() - 1) { // 完全匹配时
result.push_back(i - needle.size() + 1); // 记录匹配位置
j = next[j]; // 继续查找下一个可能的匹配
}
}
return result;
}
// 计算所有前缀的最大 border 长度
vector<int> getBorders(const string& s) {
vector<int> next(s.size());
getNext(&next[0], s); // 计算 next 数组
vector<int> borders(s.size());
for (int i = 0; i < s.size(); i++) {
borders[i] = next[i] + 1; // 记录前缀的最长 border 长度
}
return borders;
}
int main() {
string s1, s2;
cin >> s1 >> s2;
// 获取 s2 在 s1 中所有的出现位置
vector<int> positions = strStr(s1, s2);
for (int pos : positions) {
cout << pos + 1 << endl; // 题目要求输出位置从 1 开始
}
// 获取 s2 所有前缀的最长 border 长度
vector<int> borders = getBorders(s2);
for (int i = 0; i < borders.size(); i++) {
cout << borders[i] << " ";
}
cout << endl;
return 0;
}
总结反思:
KMP算法好复杂啊啊啊啊
KMP算法主要用于字符串的匹配,它的主要思想就是当出现字符不匹配时,可以知道一部分已经匹配的文本内容,可以利用这些信息避免从头再去做匹配;
基础知识:
前缀:不包括最后一个字符的所有字符的所以以第一个字符为开头的字符串
后缀:不包括第一个字符的所有字符的所以以最后一个字符为开头的字符串
前缀表:next数组
getNext()函数计算的是统一减一的next数组,比如aabaaf 前缀表为0,1,0,1,2,0
计算之后的 getNext() 计算的next数组为:-1,0,-1,0,1,-1
j:指向前缀末尾的位置,用来表示当前前缀的匹配长度
i:指向后缀末尾的位置
由于第一个字符没有前后缀,next[0]=j;next[i] 表示的是当前位置前后缀的长度;
for循环开始遍历原字符串,当它不匹配的时候 ,则回到next[j]即上一个匹配的位置;匹配时,就++,表示前后缀的长度加1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









