







1.基本介绍
- 赫夫曼编码也翻译为 哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式, 属于一种程序算法
- 赫夫曼编码是赫哈夫曼树在电讯通信中的经典的应用之一。
- 赫夫曼编码广泛地用于数据文件压缩。其压缩率通常在 20%~90%之间
- 赫夫曼码是可变字长编码(VLC)的一种。Huffman 于 1952 年提出一种编码方法,称之为最佳编码
2.原理剖析
通信领域中信息的处理方式 1-定长编码
通信领域中信息的处理方式 2-变长编码

通信领域中信息的处理方式 3-赫夫曼编码
步骤如下;
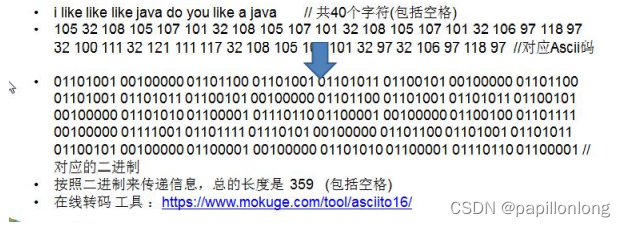
传输的 字符串
-
i like like like java do you like a java
-
d:1 y:1 u:1 j:2 v:2 o:2 l:4 k:4 e:4 i:5 a:5 :9 // 各个字符对应的个数
-
按照上面字符出现的次数构建一颗赫夫曼树, 次数作为权值
步骤:
构成赫夫曼树的步骤:
-
从小到大进行排序, 将每一个数据,每个数据都是一个节点 , 每个
节点可以看成是一颗最简单的二叉树 -
取出根节点权值最小的两颗二叉树
-
组成一颗新的二叉树, 该新的二叉树的根节点的权值是前面两颗二叉树根节点权值的和
-
再将这颗新的二叉树,以根节点的权值大小 再次排序, 不断重复 1-2-3-4 的步骤,直到数列中,所有的数据都被处理,
就得到一颗赫夫曼树
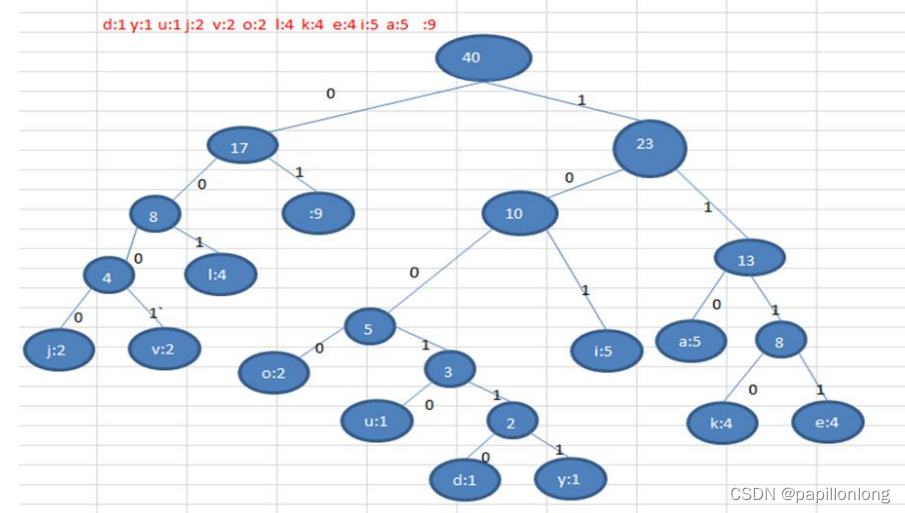
4 根据赫夫曼树,给各个字符,规定编码 (前缀编码), 向左的路径为 0 向右的路径为 1 , 编码
如下:
o: 1000 u: 10010 d: 100110 y: 100111 i: 101
a : 110 k: 1110 e: 1111 j: 0000 v: 0001
l: 001 : 01
5 按照上面的赫夫曼编码,我们的"i like like like java do you like a java" 字符串对应的编码为 (注
意这里我们使用的无损压缩)
10101001101111011110100110111101111010011011110111101000011000011100110011110000110
01111000100100100110111101111011100100001100001110 通过赫夫曼编码处理 长度为 133
6 长度为 : 133
说明:
原来长度是 359 , 压缩了 (359-133)
此编码满足前缀编码, 即字符的编码都不能是其他字符编码的前缀。不会造成匹配的多义性
赫夫曼编码是无损处理方案
注意事项
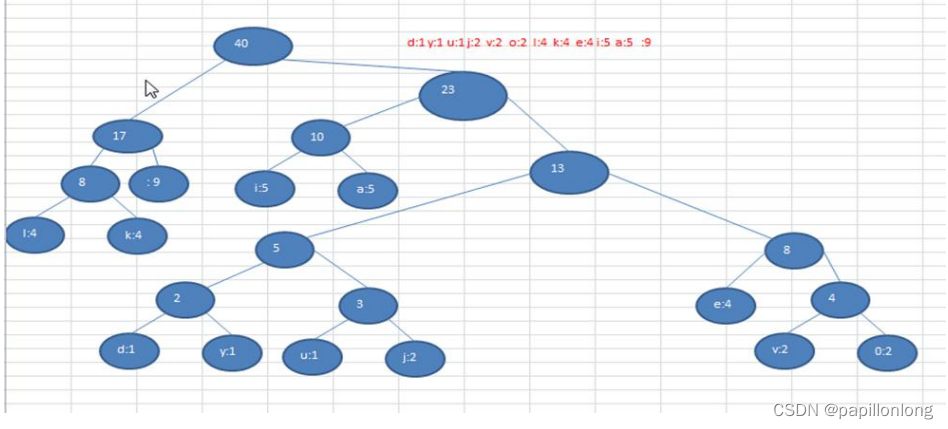
注意, 这个赫夫曼树根据排序方法不同,也可能不太一样,这样对应的赫夫曼编码也不完全一样,但是 wpl 是
一样的,都是最小的, 最后生成的赫夫曼编码的长度是一样,比如: 如果我们让每次生成的新的二叉树总是排在权
值相同的二叉树的最后一个,则生成的二叉树为:
3.最佳实践-数据压缩(创建赫夫曼树)
将给出的一段文本,比如 “i like like like java do you like a java” , 根据前面的讲的赫夫曼编码原理,对其进行数
据 压 缩 处 理 , 形 式 如
"1010100110111101111010011011110111101001101111011110100001100001110011001111000011001111000100100100
110111101111011100100001100001110
"步骤 1:根据赫夫曼编码压缩数据的原理,需要创建 "i like like like java do you like a
思路:前面已经分析过了,而且我们已然讲过了构建赫夫曼树的具体实现。
代码实现:
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class HuffmanCode {
public static void main(String[] args) {
String content = "i like like like java do you like a java";
byte[] contentBytes = content.getBytes();
System.out.println(contentBytes.length);
List<Node> nodes = getNodes(contentBytes);
System.out.println("nodes=" + nodes);
//测试
System.out.println("赫夫曼树");
Node huffmanTreeRoot = createHuffManTree(nodes);
System.out.println("前序遍历");
huffmanTreeRoot.preOrder();
}
//前序遍历方法
public static void preOrder(Node root) {
if(root != null) {
root.preOrder();
}else {
System.out.println("赫夫曼树为空");
}
}
/**
*
* @param bytes 接收字符
* @return 返回的就是List形式
*/
private static List<Node> getNodes(byte[] bytes) {
// 1创建一个ArrayList
ArrayList<Node> nodes = new ArrayList<Node>();
// 遍历bytes,统计每一个byte出现的次数 ->map[key ,value]
Map<Byte, Integer> counts = new HashMap<>();
for (byte b : bytes) {
Integer count = counts.get(b);
if (count == null) {// Map还没有这个字符数据,第一次
counts.put(b, 1);
} else {
counts.put(b, count + 1);
}
}
// 把每一个键值对转成一个Node对象,并加入到nodes集合
// 遍历map
for (Map.Entry<Byte, Integer> entry : counts.entrySet()) {
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
// 可以通过List创建对应的赫夫曼树
private static Node createHuffManTree(List<Node> node) {
while (nodes.size() > 1) {
// 排序, 从小到大
Collections.sort(nodes);
// 取出第一颗最小的二叉树
Node leftNode = nodes.get(0);
// 取出第二颗最小的二叉树
Node rightNode = nodes.get(1);
// 创建一颗新的二叉树,它的根节点 没有 data, 只有权值
Node parent = new Node(null, leftNode.weight + rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
// 将已经处理的两颗二叉树从 nodes 删除
nodes.remove(leftNode);
nodes.remove(rightNode);
// 将新的二叉树,加入到 nodes
nodes.add(parent);
}
// nodes 最后的结点,就是赫夫曼树的根结点
return nodes.get(0);
}
}
//创建Node,待数据和权值
class Node implements Comparable<Node> {
Byte data;// 存放数据(字符)本身,比如'a' => 97 '' = 32
int weight;// 权值,表示字符出现的次数
Node left;
Node right;
public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
// 从小到大排序
return this.weight - o.weight;
}
public String toString() {
return "Node [data=" + data + " weight=" + weight + "]";
}
// 前序遍历
public void preOrder() {
System.out.println(this);
if (this.left != null) {
this.left.preOrder();
}
if (this.right != null) {
this.right.preOrder();
}
}
}
最佳实践-数据压缩(生成赫夫曼编码和赫夫曼编码后的数据)
我们已经生成了 赫夫曼树, 下面我们继续完成任务
- 生成赫夫曼树对应的赫夫曼编码 , 如下表: =01 a=100 d=11000 u=11001 e=1110 v=11011 i=101 y=11010 j=0010 k=1111 l=000 o=0011
- 使用赫夫曼编码来生成赫夫曼编码数据 ,即按照上面的赫夫曼编码,将"i like like like java do you like a java" 字符串生成对应的编码数据, 形式如下. 10101000101111111100100010111111110010001011111111001001010011011100011100000110111010001111001010
00101111111100110001001010011011100 - 思路:前面已经分析过了,而且我们讲过了生成赫夫曼编码的具体实现。
- 代码实现:看老师演示:
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class HuffmanCode {
public static void main(String[] args) {
String content = "i like like like java do you like a java";
byte[] contentBytes = content.getBytes();
System.out.println(contentBytes.length);
List<Node> nodes = getNodes(contentBytes);
System.out.println("nodes=" + nodes);
// 测试
System.out.println("赫夫曼树");
Node huffmanTreeRoot = createHuffManTree(nodes);
System.out.println("前序遍历");
huffmanTreeRoot.preOrder();
}
// 前序遍历方法
public static void preOrder(Node root) {
if (root != null) {
root.preOrder();
} else {
System.out.println("赫夫曼树为空");
}
}
/**
*
* @param bytes 接收字符
* @return 返回的就是List形式
*/
private static List<Node> getNodes(byte[] bytes) {
// 1创建一个ArrayList
ArrayList<Node> nodes = new ArrayList<Node>();
// 遍历bytes,统计每一个byte出现的次数 ->map[key ,value]
Map<Byte, Integer> counts = new HashMap<>();
for (byte b : bytes) {
Integer count = counts.get(b);
if (count == null) {// Map还没有这个字符数据,第一次
counts.put(b, 1);
} else {
counts.put(b, count + 1);
}
}
// 把每一个键值对转成一个Node对象,并加入到nodes集合
// 遍历map
for (Map.Entry<Byte, Integer> entry : counts.entrySet()) {
nodes.add(new Node(entry.getKey(), entry.getValue()));
}
return nodes;
}
// 可以通过List创建对应的赫夫曼树
private static Node createHuffManTree(List<Node> node) {
while (nodes.size() > 1) {
// 排序, 从小到大
Collections.sort(nodes);
// 取出第一颗最小的二叉树
Node leftNode = nodes.get(0);
// 取出第二颗最小的二叉树
Node rightNode = nodes.get(1);
// 创建一颗新的二叉树,它的根节点 没有 data, 只有权值
Node parent = new Node(null, leftNode.weight + rightNode.weight);
parent.left = leftNode;
parent.right = rightNode;
// 将已经处理的两颗二叉树从 nodes 删除
nodes.remove(leftNode);
nodes.remove(rightNode);
// 将新的二叉树,加入到 nodes
nodes.add(parent);
}
// nodes 最后的结点,就是赫夫曼树的根结点
return nodes.get(0);
}
}
//创建Node,待数据和权值
class Node implements Comparable<Node> {
Byte data;// 存放数据(字符)本身,比如'a' => 97 '' = 32
int weight;// 权值,表示字符出现的次数
Node left;
Node right;
public Node(Byte data, int weight) {
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(Node o) {
// 从小到大排序
return this.weight - o.weight;
}
public String toString() {
return "Node [data=" + data + " weight=" + weight + "]";
}
// 前序遍历
public void preOrder() {
System.out.println(this);
if (this.left != null) {
this.left.preOrder();
}
if (this.right != null) {
this.right.preOrder();
}
}
}















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









