







最近看RocketMQ的时候,了解到v4.5.0之后,broker采用遵循raft协议的复制组来实现数据一致性。虎躯一震,raft协议在现在的脑子里变的熟悉又陌生…
问题不大,重新刷一遍raft。
先贴官网:The Raft Consensus Algorithm
再贴动画演示:Raft: Understandable Distributed Consensus
ps:里边的动图挺有意思😈
简介
ps:来自维基百科
Raft是一种用于替代Paxos的共识算法。相比于Paxos,Raft的目标是提供更清晰的逻辑分工使得算法本身能被更好地理解,同时它安全性更高,并能提供一些额外的特性。[1][2]:1Raft能为在计算机集群之间部署有限状态机提供一种通用方法,并确保集群内的任意节点在某种状态转换上保持一致。Raft算法的开源实现众多,在Go、C++、Java以及 Scala中都有完整的代码实现。Raft这一名字来源于"Reliable, Replicated, Redundant, And Fault-Tolerant"(“可靠、可复制、可冗余、可容错”)的首字母缩写。[3]
Raft使用选举领袖的方式做共识算法。一个典型的Raft cluster一般有5台服务器,这可以应对两次故障。
在一个Raft cluster里,服务器有三种身份:
- 领袖(leader)
- 跟随者(follower)
- 候选人(candidate)
leader在同一时间只会有一个,但不是一成不变的。剩下的服务器都是follower。
leader会处理所有的外部请求,如果一个服务器不是leader,那么这个请求会被转发到leader处理。
leader会在一个固定的时间段里给follower发送心跳(heartbeat),告诉follower:hi boys ! I am alive ! 💋
每个follower都有自己的超时窗口(每个follower的timeout可能不一样),当超过一定时间没有收到leader的heartbeat之后,集群就会进入选举状态。🙋
从下边三个方面来了解raft
- 领袖选举(Leader Election)
- 记录复写(Log Replication)
- 安全性(Safety)
领袖选举(leader election)
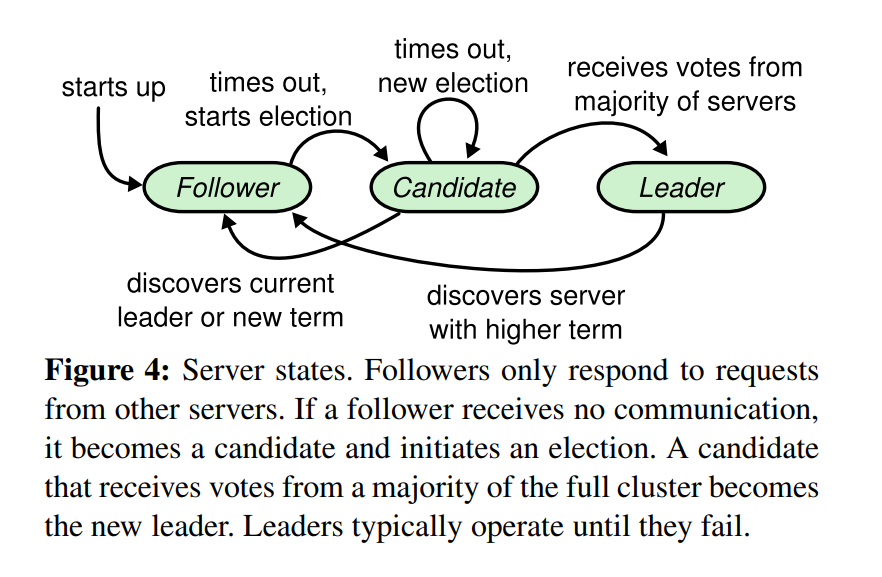
上图可以看出,所有的节点期初都是follower角色,如果在一段时间内没有收到leader的心跳(times out),那么便切换到candidate角色,然后发起选举(starts election);如果收到大多数的投票,那么切换成leader角色;
有两个超时时间(timeout)会影响leader election:
election timeout
follower等待成为candidate的时间,这个时间在150ms~300ms的范围内是随机的。
如果超过了这个timeout时间还没有收到leader的心跳,那么这个follower会做下边两件事:
- 切换成candidate的角色
- 它的Term : 0->1 and Vote Count : 0 ->1
然后,它会向其它所有节点(nodes)发送一个投票请求(Request Vote)。如果接受这个请求的节点在此任期(Term)内还没有投过票,那么就会投这个Request Vote的发起方,并且将自己的election timeout重置。
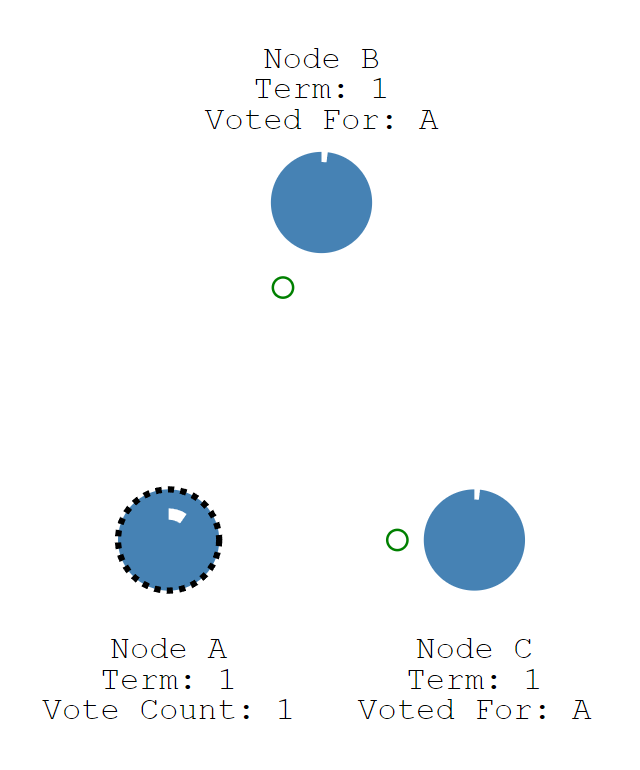
当一个candidate节点有大多数的投票的时候,那么和这个节点切换为leader节点。
heartbeat timeout
leader节点开始发送Append Entries信息到所有的follower节点,这些信息按照heartbeat timeout指定的时间间隔去发送。followers收到Append Entries请求后会重置自己的election timeout并且做出响应。
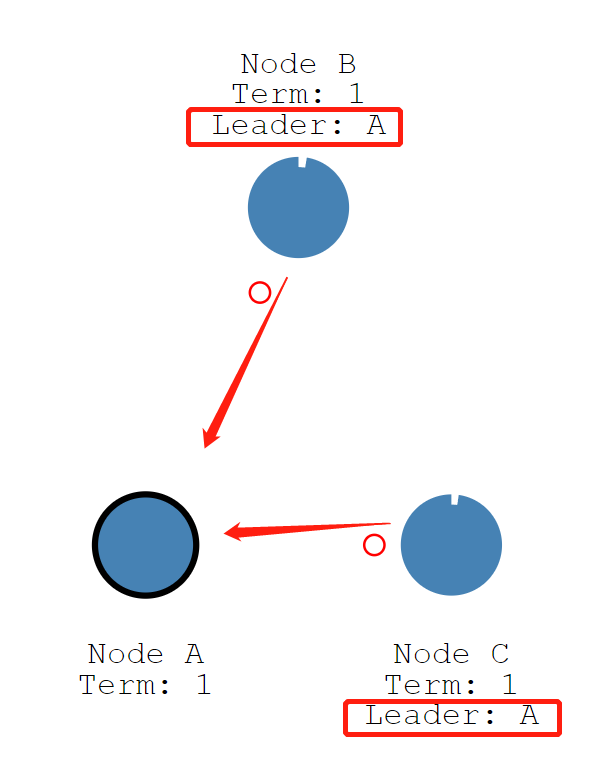
至此,这个任期(Term)将会一直存在,直到某一个follower收不到leader的心跳并且切换成了candidate角色。
NOTE
- 在一个偶数的raft cluster中一旦leader不可用,剩下的几个candidate在同一时间可能有“脑裂”(split vote)的风险。当然这种case发生的概率还是极低的,只有在leader不可用时,剩下的candidate中有两个节点的剩余election time完全一致时才会发生。所以官方建议一个raft cluster最少要有五个节点。
- 为了避免
split vote,raft引入了randomized election timeouts避免平票的case发生。 - raft是一个
leader-based共识算法,节点的数据尽量是奇数个,这样可以尽量保证majority的出现。
记录复写(log replication)
当集群中的leader被选举出来之后,客户端的所有请求都会发送到leader,leader来调度这些请求的顺序,并且要保证leader与followers状态的一致性。
Replicated state machines
共识算法一般是基于复制状态机(Replicated state machines)实现的。
ps:不展开了,有时间再专门写一篇🏃♀️🏃♂️
raft中,leader将客户端请求(command)封装成一个个log entry,然后将这些log entries复制(replicate)到所有的follower节点,然后所有节点按照顺序应用log entry中的command,那么大家最终的状态就是一致的了。
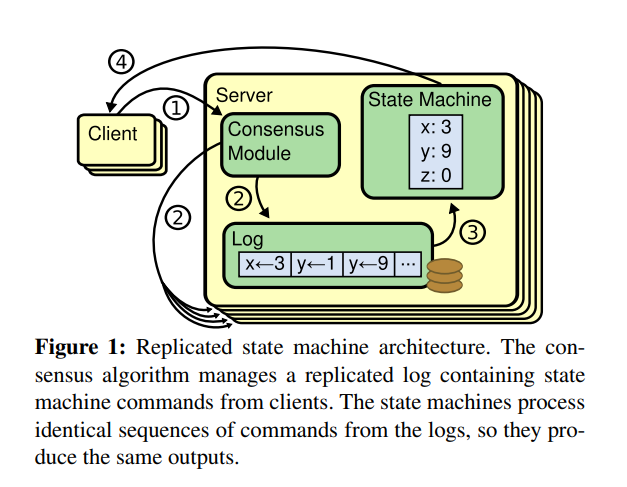
请求流程
- client发了一个请求给到leader,leader将“变化”(change)添加(appended)到自己的log中。
- leader在下一次heartbeat时,将“变化”(change)发送到所有的followers
- 一旦大多数follower承认了这个条目(entry),那么这个条目就会被提交(committed)
- 类似2PC,区别是leader不需要全部节点的回复,这样只要超过一半节点处于工作状态则系统就是可用的
- leader将请求response发送到client
NOTE
- Raft可以在网络分区(network partitions)时保持一致
- raft算法为了保证高可用,并不是强一致的,而是最终一致的
安全性(safety)
没时间了,下次再说…🏃♂️














 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









