









正则表达式一直以来都是比较难掌握的,并且正则匹配的效率一直不高,特别是java语言。
大数据还没来之前,正则匹配的效率问题还不算程序的大问题。
正则匹配比较常用与URL的匹配,正巧网络流量日志是典型大数据文件。
当大数据遇上正则匹配,抓狂的事情就发生了,效率极低。
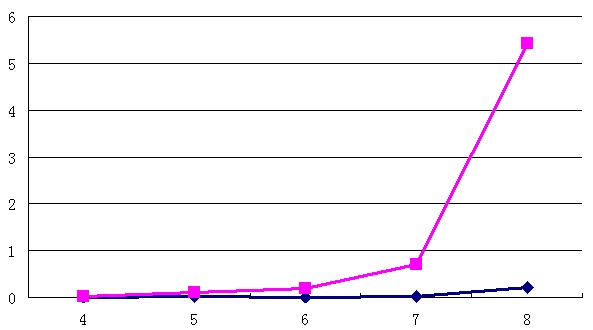
笔者做了一个简单的测试,对比了最简单的正则匹配(直接匹配某个字符串,没有任何通配符)和String的indexOf方法的效率
下图是随着匹配次数的增加,时间的增长情况,正则匹配呈指数增长。(横坐标是匹配次数,底数为10;纵坐标为时间,单位为秒)
Hadoop进行批量处理,不太适合逻辑太复杂的处理,有违Hadoop的机制。如何设计处理逻辑需要全面的考虑。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









