







环境:JDK8
主要分析String类的一些常用的方法源码。
String
先看String类的定义:
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence
可以看到String类被final修饰,因此不能被继承。String类还实现了序列化接口Serializable、可比较的接口Comparable并指定范型为String,该接口必须要实现int compareTo(T o) 方法。最后还实现了字符序列CharSequence接口,该接口也有些常用的方法,如charAt(int index) 、length()、toString() 等
构造字符串
String类的无参构造函数:
/*** Initializes a newly created {@code String} object so that it represents* an empty character sequence. Note that use of this constructor is* unnecessary since Strings are immutable.*/public String() {this.value = "".value;}
其中value定义:
private final char[] value
该构造函数创建了一个空的字符串并存在字符数组value中。
再看一个有参的构造函数:
public String(char value[]) {this.value = Arrays.copyOf(value, value.length);}
该构造函数指定一个字符数组来创建一个字符序列。是通过Arrays的copyOf方法将字符数组拷贝到当前数组。
这样当修改字符数组的子串时,不会影响新字符数组。
经过以上分析可以看出,下面两个语句是等价的,因为String类底层使用char[]数组来存储字符序列。
char data[] = {'a', 'b', 'c'};String str = new String(data);
使用字节数组构造一个String
在Java中,String实例中保存有一个char[]字符数组,char[]字符数组是以unicode码来存储的,String 和 char 为内存形式,byte是网络传输或存储的序列化形式。所以在很多传输和存储的过程中需要将byte[]数组和String进行相互转化。所以,String提供了一系列重载的构造方法来将一个字符数组转化成String,提到byte[]和String之间的相互转换就不得不关注编码问题。
String(byte[] bytes, Charset charset) 是指通过charset来解码指定的byte数组,将其解码成unicode的char[]数组,够造成新的String。
-
这里的bytes字节流是使用charset进行编码的,想要将他转换成unicode的char[]数组,而又保证不出现乱码,那就要指定其解码方式。
如果我们在使用byte[]构造String的时候,使用的是下面这四种构造方法(带有charsetName或者charset参数)的一种的话,那么就会使用StringCoding.decode方法进行解码,使用的解码的字符集就是我们指定的charsetName或者charset。 我们在使用byte[]构造String的时候,如果没有指明解码使用的字符集的话,那么StringCoding的decode方法首先调用系统的默认编码格式,如果没有指定编码格式则默认使用ISO-8859-1编码格式进行编码操作。主要体现代码如下:
static byte[] encode(String charsetName, char[] ca, int off, int len)throws UnsupportedEncodingException{StringEncoder se = deref(encoder);String csn = (charsetName == null) ? "ISO-8859-1" : charsetName;if ((se == null) || !(csn.equals(se.requestedCharsetName())|| csn.equals(se.charsetName()))) {se = null;try {Charset cs = lookupCharset(csn);if (cs != null)se = new StringEncoder(cs, csn);} catch (IllegalCharsetNameException x) {}if (se == null)throw new UnsupportedEncodingException (csn);set(encoder, se);}return se.encode(ca, off, len);}
上面是编码清单,下面是解码清单:
static char[] decode(String charsetName, byte[] ba, int off, int len)throws UnsupportedEncodingException{StringDecoder sd = deref(decoder);String csn = (charsetName == null) ? "ISO-8859-1" : charsetName;if ((sd == null) || !(csn.equals(sd.requestedCharsetName())|| csn.equals(sd.charsetName()))) {sd = null;try {Charset cs = lookupCharset(csn);if (cs != null)sd = new StringDecoder(cs, csn);} catch (IllegalCharsetNameException x) {}if (sd == null)throw new UnsupportedEncodingException(csn);set(decoder, sd);}return sd.decode(ba, off, len);}
charAt
再看charAt(int index)方法源码:
public char charAt(int index) {if ((index < 0) || (index >= value.length)) {throw new StringIndexOutOfBoundsException(index);}return value[index];}
该方法返回字符序列中下标为index的字符。并且index的范围:(0,value.length].
concat
再看publicString concat(String str):
public String concat(String str) {int otherLen = str.length();if (otherLen == 0) {return this;}int len = value.length;char buf[] = Arrays.copyOf(value, len + otherLen);str.getChars(buf, len);return new String(buf, true);}
该方法先判断传递进来的参数字符串长度是否为0,如果是就返回当前字符串。
否则使用Arrays类的静态方法copyOf(char[] original, int newLength)
拷贝当前字符数组到新数组,指定长度为当前字符串长度加上参数字符串长度,然后通过getChars方法将value字符数组拷贝到buf字符数组,这点可以从getChars方法的实现中看到:
void getChars(char dst[], int dstBegin) {System.arraycopy(value, 0, dst, dstBegin, value.length);}
可以看到,连接字符串操作实际是字符串的拷贝。最后,返回连接成功后的字符串。
最后是一个特殊的私有包范围类型的构造方法,String除了提供了很多公有的供程序员使用的构造方法以外,还提供了一个包范围类型的构造方法(Jdk 8),我们看一下他是怎么样的:
String(char[] value, boolean share) {// assert share : "unshared not supported";this.value = value;}
从代码中我们可以看出,该方法和 String(char[] value)有两点区别:
-
第一个,该方法多了一个参数: boolean share,其实这个参数在方法体中根本没被使用,也给了注释,目前不支持使用false,只使用true。那么可以断定,加入这个share的只是为了区分于String(char[] value)方法,不加这个参数就没办法定义这个函数,只有参数不能才能进行重载。
-
第二个区别就是具体的方法实现不同。
我们前面提到过,String(char[] value)方法在创建String的时候会用到Arrays的copyOf方法将value中的内容逐一复制到String当中,而这个String(char[] value, boolean share)方法则是直接将value的引用赋值给String的value。
那么也就是说,这个方法构造出来的String和参数传过来的char[] value共享同一个数组。 那么,为什么Java会提供这样一个方法呢?
首先,我们分析一下使用该构造函数的好处:
-
首先,性能好,这个很简单,一个是直接给数组赋值(相当于直接将String的value的指针指向char[]数组),一个是逐一拷贝。当然是直接赋值快了。
-
其次,共享内部数组节约内存。
但是,该方法之所以设置为包范围,是因为一旦该方法设置为公有,在外面可以访问的话,那就破坏了字符串的不可变性。例如如下YY情形:
char[] arr = new char[] {'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd'};String s = new String(0, arr.length, arr); // "hello world"arr[0] = 'a'; // replace the first character with 'a'System.out.println(s); // aello world
如果构造方法没有对arr进行拷贝,那么其他人就可以在字符串外部修改该数组,由于它们引用的是同一个数组,因此对arr的修改就相当于修改了字符串。
所以,从安全性角度考虑,他也是安全的。对于调用他的方法来说,由于无论是原字符串还是新字符串,其value数组本身都是String对象的私有属性,从外部是无法访问的,因此对两个字符串来说都很安全。
在Jdk7 开始就有很多String里面的方法都使用这种“性能好的、节约内存的、安全”的构造函数。比如:substring、replace、concat、valueOf等方法(实际上他们使用的是public String(char[], int, int)方法,原理和本方法相同,已经被本方法取代)。
但是在Jdk 7中,substring已经不再使用这种“优秀”的方法了,为什么呢? 虽然这种方法有很多优点,但是他有一个致命的缺点,对于sun公司的程序员来说是一个零容忍的bug,那就是他很有可能造成内存泄露。
看一个例子,假设一个方法从某个地方(文件、数据库或网络)取得了一个很长的字符串,然后对其进行解析并提取其中的一小段内容,这种情况经常发生在网页抓取或进行日志分析的时候。下面是示例代码:
String aLongString = "...a very long string...";String aPart = data.substring(20, 40);return aPart;
在这里aLongString只是临时的,真正有用的是aPart,其长度只有20个字符,但是它的内部数组却是从aLongString那里共享的,因此虽然aLongString本身可以被回收,但它的内部数组却不能(如下图)。这就导致了内存泄漏。如果一个程序中这种情况经常发生有可能会导致严重的后果,如内存溢出,或性能下降。
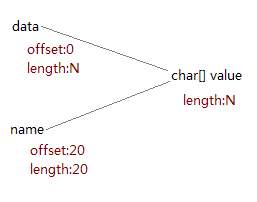
下面贴下jdk6的substring源码:
public String More ...substring(int beginIndex, int endIndex) {if (beginIndex < 0) {throw new StringIndexOutOfBoundsException(beginIndex);}if (endIndex > count) {throw new StringIndexOutOfBoundsException(endIndex);}if (beginIndex > endIndex) {throw new StringIndexOutOfBoundsException(endIndex - beginIndex);}return ((beginIndex == 0) && (endIndex == count)) ? this :new String(offset + beginIndex, endIndex - beginIndex, value);}
最后返回调用
String(int offset, int count, char value[]) {this.value = value;this.offset = offset;this.count = count;}
下面阅读一下jdk8中的substring方法和jdk6做个比较
substring
substring有两个重载方法:
public String substring(int beginIndex) {if (beginIndex < 0) {throw new StringIndexOutOfBoundsException(beginIndex);}int subLen = value.length - beginIndex;if (subLen < 0) {throw new StringIndexOutOfBoundsException(subLen);}return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);}
public String substring(int beginIndex, int endIndex) {if (beginIndex < 0) {throw new StringIndexOutOfBoundsException(beginIndex);}if (endIndex > value.length) {throw new StringIndexOutOfBoundsException(endIndex);}int subLen = endIndex - beginIndex;if (subLen < 0) {throw new StringIndexOutOfBoundsException(subLen);}return ((beginIndex == 0) && (endIndex == value.length)) ? this: new String(value, beginIndex, subLen);}
这两个重载方法都是先计算要截取的子串长度,判断边界最后返回调用new String(value, beginIndex, subLen)方法,我们来看一下这个方法:
public String(char value[], int offset, int count) {if (offset < 0) {throw new StringIndexOutOfBoundsException(offset);}if (count <= 0) {if (count < 0) {throw new StringIndexOutOfBoundsException(count);}if (offset <= value.length) {this.value = "".value;return;}}// Note: offset or count might be near -1>>>1.if (offset > value.length - count) {throw new StringIndexOutOfBoundsException(offset + count);}this.value = Arrays.copyOfRange(value, offset, offset+count);}
offset指第一个匹配的字符序列的索引,count指子串的长度。
最终该子串会被拷贝到字符数组value中,并且后续的字符数组的修改并不影响新创建的字符串。
可以看到JDK6后substring方法底层是字符串的拷贝而不是数组引用。
新的实现虽然损失了性能,而且浪费了一些存储空间,但却保证了字符串的内部数组可以和字符串对象一起被回收,从而防止发生内存泄漏,因此新的substring比原来的更健壮。
contains
再来看public boolean contains(CharSequence s):
public boolean contains(CharSequence s) {return indexOf(s.toString()) > -1;}
该直接调用indexOf(String)方法:
public int indexOf(String str) {return indexOf(str, 0);}
indexOf方法中又调用indexOf(String,int)方法,在该方法中又返回调用静态方法
static int indexOf(char[] source, int sourceOffset, int sourceCount, char[] target, int targetOffset, int targetCount, int fromIndex):
/*** Code shared by String and StringBuffer to do searches. The* source is the character array being searched, and the target* is the string being searched for.** @param source 要被搜索的字符串,即源字符串* @param sourceOffset 源字符串的偏移* @param sourceCount 源字符串的长度* @param target 要在这个字符串中搜索,即目标字符串* @param targetOffset 目标字符串偏移.* @param targetCount 目标字符串长度.* @param fromIndex 开始搜索的索引.*/static int indexOf(char[] source, int sourceOffset, int sourceCount,char[] target, int targetOffset, int targetCount,int fromIndex) {if (fromIndex >= sourceCount) {return (targetCount == 0 ? sourceCount : -1);}if (fromIndex < 0) {fromIndex = 0;}if (targetCount == 0) {return fromIndex;}char first = target[targetOffset];int max = sourceOffset + (sourceCount - targetCount);for (int i = sourceOffset + fromIndex; i <= max; i++) {/* Look for first character. */if (source[i] != first) {while (++i <= max && source[i] != first);}/* Found first character, now look at the rest of v2 */if (i <= max) {int j = i + 1;int end = j + targetCount - 1;for (int k = targetOffset + 1; j < end && source[j]== target[k]; j++, k++);if (j == end) {/* Found whole string. */return i - sourceOffset;}}}return -1;}
首先判断开始索引如果大于源字符串则返回,若目标字符串长度为0返回源字符串长度,否则返回-1.
然后迭代查找字符,若全部源字符串都找到则返回第一个匹配的索引,否则返回-1.
所以在public boolean contains(CharSequence s)方法中,若indexOf方法返回-1则返回false,否则返回true。
equals
public boolean equals(Object anObject) {if (this == anObject) {return true;}if (anObject instanceof String) {String anotherString = (String)anObject;int n = value.length;if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) {if (v1[i] != v2[i])return false;i++;}return true;}}return false;}
该方法首先判断this == anObject ?,也就是说判断要比较的对象和当前对象是不是同一个对象,如果是直接返回true,如不是再继续比较,然后在判断anObject是不是String类型的,如果不是,直接返回false,如果是再继续比较,到了能终于比较字符数组的时候,他还是先比较了两个数组的长度,不一样直接返回false,一样再逐一比较值。
join
最后阅读下jdk8新加入的String类的静态方法join,这个方法是通过分隔符delimiter来构造字符的:
public static String join(CharSequence delimiter, CharSequence... elements) {Objects.requireNonNull(delimiter);Objects.requireNonNull(elements);// Number of elements not likely worth Arrays.stream overhead.StringJoiner joiner = new StringJoiner(delimiter);for (CharSequence cs: elements) {joiner.add(cs);}return joiner.toString();}
StringJoiner 类也是jdk1.8开始加入的通过分隔符或前缀或后缀来构造字符串的,底层是字符序列的拷贝。
这个方法要求参数是都不能为空的,否则回报空指针异常,requireNonNull方法源码可以说明这点:
public static <T> T requireNonNull(T obj) {if (obj == null)throw new NullPointerException();return obj;}
该方法是jdk1.7开始加入的操作对象的工具类Objects包含的方法。
例子:
String message = String.join("-", "Java", "is", "cool");// message returned is: "Java-is-cool"
如有疏漏请指出,谢谢!
部分内容及图片参考:
http://www.hollischuang.com/archives/99















 4936
4936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









