






点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
葡萄美酒夜光杯,欲饮琵琶马上催。
大家好,我是Python进阶者。
前言
前几天在才哥交流群里边遇到一个叫【上海-数据分析-小粒】的粉丝提了一个小问题,如下:
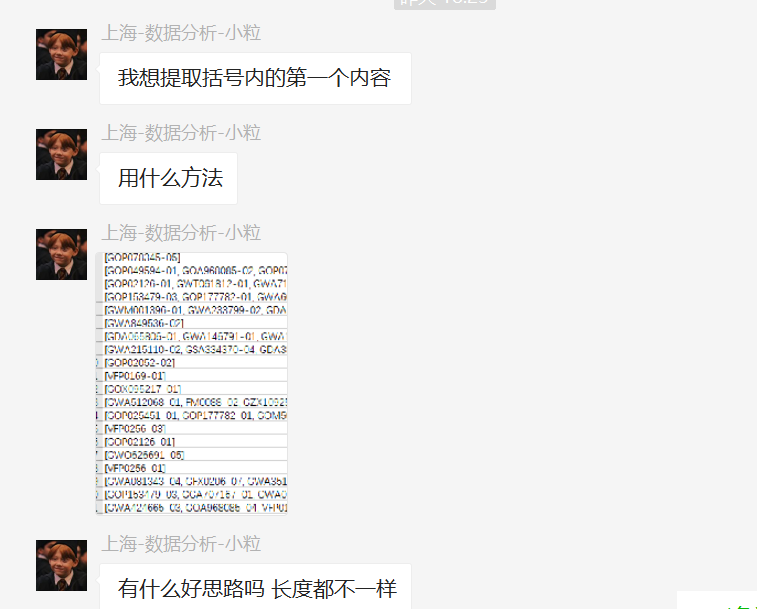
数据如下:
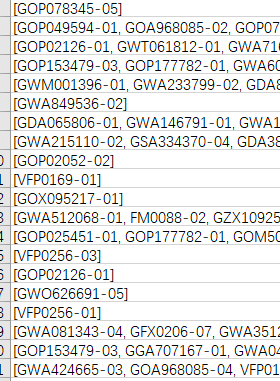 咋一看,这个题目倒是也确实不太难,群里提供思路的人也很多,一起来看看吧!
咋一看,这个题目倒是也确实不太难,群里提供思路的人也很多,一起来看看吧!
思路和实现方法
针对这个问题,群里的小伙伴纷纷献策,这里盘点4个思路和实现方法。
方法一
下面是【北京-数分-阿汤】大佬给的思路,使用列表切两次,分别以一次逗号,一次括号,要做判断,如果没逗号就切括号;还有就是写正则。
方法二
下面是【深圳-运营-梧桐】大佬给的思路,使用excel分列,先根据逗号分列,然后分别将括号[和]替换掉,几秒钟的事。
方法三
下面是【武汉-优化算法-derek】大佬给的思路和代码实现,本质上也是切片处理。
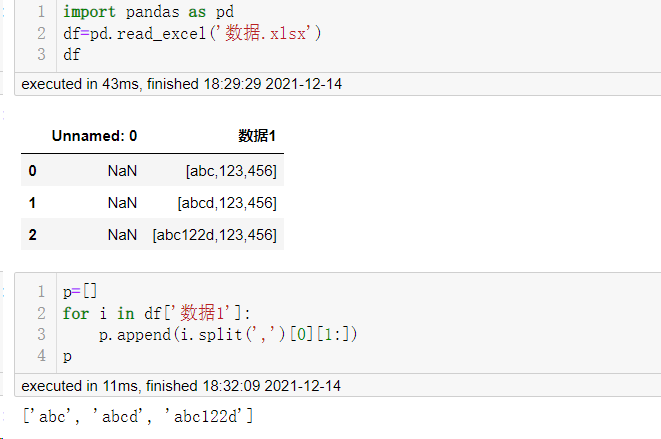 不过产品经理发话了,有的数据没逗号,需要加条规则,把右括号先替换为逗号,然后就有了下面的结果:
不过产品经理发话了,有的数据没逗号,需要加条规则,把右括号先替换为逗号,然后就有了下面的结果:
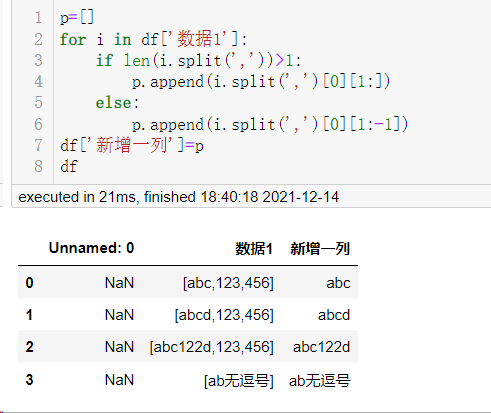
方法四
下面是【常州-销售-MT】大佬给的思路和【北京-金融-Bran】大佬给的代码实现,使用lambda x:eval(x)转列表,用apply效率应该能提高一些,代码如下:
df['新增一列']=df.数据1.apply(lambda x:x.replace('[','').replace(']',''))
df.新增一列=df.新增一列.str.split(',',expand=True)[0]但是需要注意:原来字符串不能直接搞成list,否则就都拆散了。
总结
这篇文章基于粉丝提问,盘点了4种方法针对模板字符串进行分割和提取,总的来说,用apply会快很多,因为apply跟lambda可以简化很多操作,而且lambda里面也可以写判断语句,很方便。
最后感谢【上海-数据分析-小粒】粉丝提问,感谢【北京-数分-阿汤】、【深圳-运营-梧桐】、【武汉-优化算法-derek】、【常州-销售-MT】、【北京-金融-Bran】大佬给出的思路和代码。当然方法肯定还不只是上面4种,也欢迎大家多多发散思维,提出新的方法。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~















 817
817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









