






点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
红豆生南国,春来发几枝。
大家好,我是Python进阶者。
一、前言
前几天在Python钻石交流群【大写一个Y】问了一个Python网络爬虫的问题,问题如下:大佬们 问个问题,我写了一个能把源请求头和cookies转换成字典格式的函数,运行之后cookies是成功了的,但是hesders的字典总是出现换行符 这个要怎么处理呀 研究2天了。
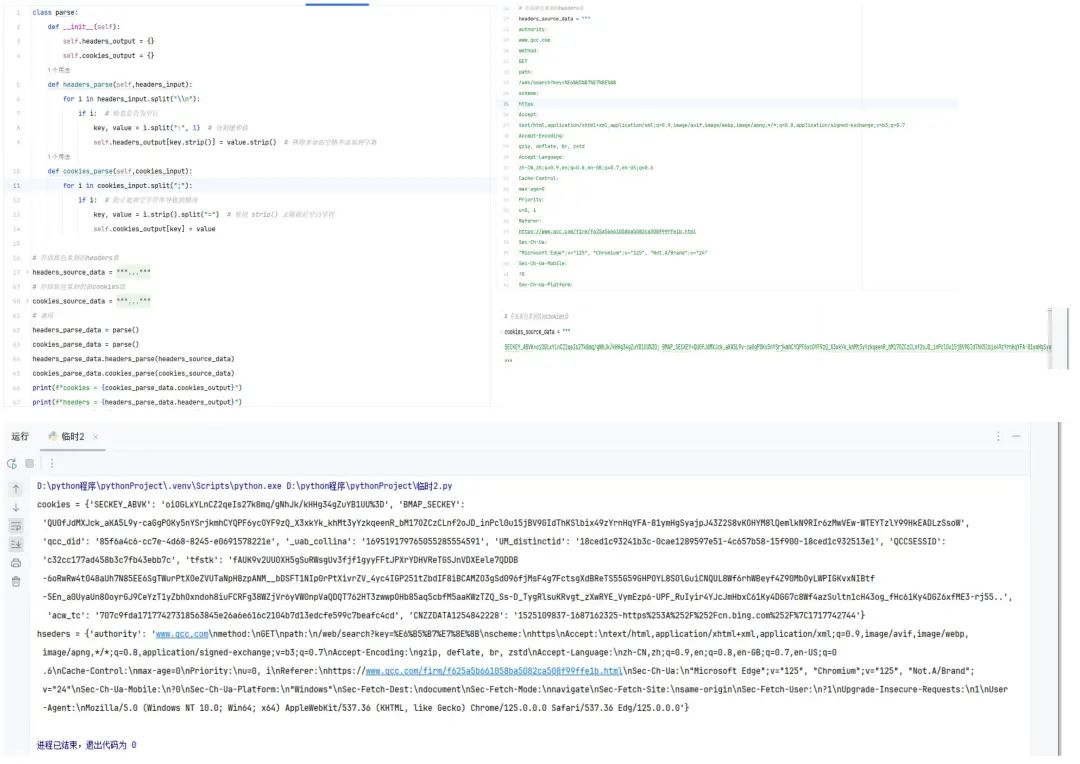
二、实现过程
这里【提请问粘给图截报错贴代源码】给了个思路如下:
【提请问粘给图截报错贴代源码】:这个是想练习语法吗,感觉转换这种的模块是有的
【大写一个Y 】:也有这方面因素,这么加吗?key, value = i.split("\\n",":",1)# 分割键和值
【提请问粘给图截报错贴代源码】:不对,你这个原字符串在for循环就有问题,先把:\n替换成其他的,再分割。
【大写一个Y 】:我试试
这里瑜亮老师也给了另外一个思路:
【瑜亮老师】:json转换一下试试
【大写一个Y 】:好的谢谢 我试试。
【大写一个Y 】:换了个方法 ,先把源头部转成列表,再用2的步长循环列表 就可以了。
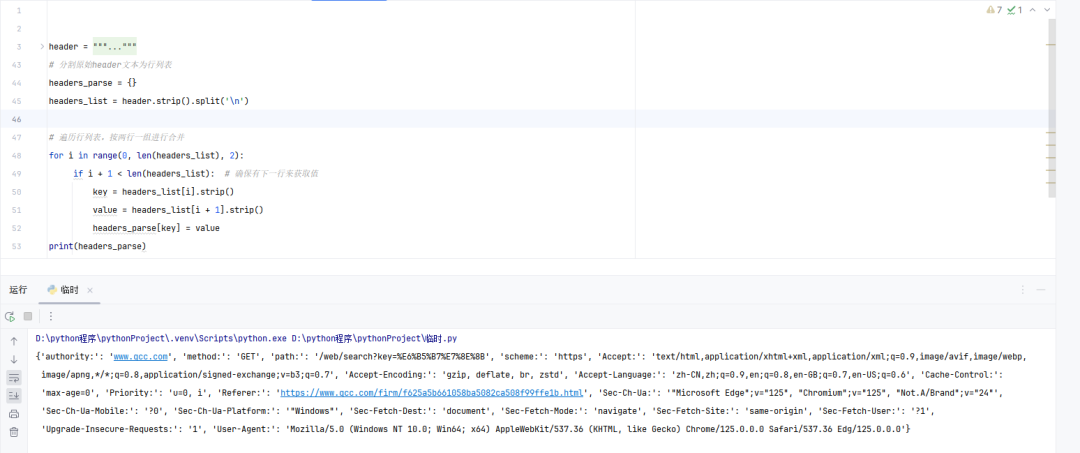
【瑜亮老师】:把最上面那个header内容发上来。你这样点两下,就复制出来了,而且结构很完整。不要用鼠标框选复制。
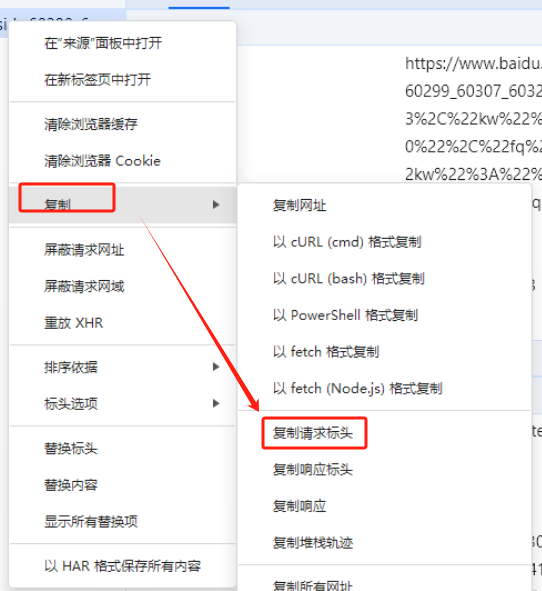
【大写一个Y 】:是的 不过最终也不是字典的格式 我就是想写一个函数 让他一步到位。
【提请问粘给图截报错贴代源码】:你试下这个,就是我说的方法,先把:\n替换成别的,再分割。代码如下:dict(map(lambda x: x.split('@#%'), headers_source_data.strip().replace(':\n', '@#%').split('\n')))【大写一个Y 】:我试试啊
【瑜亮老师】也给了一个代码,使用库实现:
import json
s = '''authority:
www.qcc.com
method:
GET
path:
/web/search?key=%E6%B5%B7%E7%8E%8B
scheme:
https
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding:
gzip, deflate, br, zstd
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cache-Control:
max-age=0
Priority:
u=0, i
Referer:
https://www.qcc.com/firm/f625a5b661058ba5082ca508f99ffe1b.html
Sec-Ch-Ua:
"Microsoft Edge";v="125", "Chromium";v="125", "Not.A/Brand";v="24"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
document
Sec-Fetch-Mode:
navigate
Sec-Fetch-Site:
same-origin
Sec-Fetch-User:
?1
Upgrade-Insecure-Requests:
1
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'''
s = s.replace('"', '').replace(':\n', '":"').replace('\n', '","')
s = '{"' + s + '"}'
s = json.loads(s)
print(s)你要是不想用json库,可以用这一行s = eval(s)。替换掉json那一行就行了。
顺利地解决了粉丝的问题。
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python基础的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【大写一个Y】提出的问题,感谢【提请问粘给图截报错贴代源码】、【瑜亮老师】给出的思路,感谢【Engineer】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(Python进阶者微信:2584914241),应粉丝要求,我创建了一些ChatGPT机器人交流群和高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~















 2120
2120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









