







前言
作者理科背景,非计算机专业,自学Python。此项目开发缘由是工作需要,出于兴趣,独立开发。
开发项目时,作者感觉个人力量实在微小,学习各模块用法,查阅资料就耗费大量时间、金钱,开发一度中断。后来,ChatGPT等AI工具横空出世,个人的脑力得到极大补充。本项目开发时,就使用了codeium插件,该插件使用了ChatGPT的服务,此项目能够运行很大一部分仰赖该工具的帮助。
在本项目的开发过程中,完成第一行代码就仿佛是播下一颗种子,在AI的帮助下,作者培育的这颗种子才得以快速长出主干。如今本项目已经初具雏形,作者已经很满意。随着这颗植物的茎干越发复杂,作者的能力已经有限,接下来的工作就交由其他专家完善了。
众所周知,ChatGPT无法在国内直接使用,而DeepSeek彼时尚未进入大众视线,其他国内AI工具效果也不佳,作者无法上传附件供AI分析,因此本项目的代码有多处优化空间。另外,代码变量命名等多有不规范之处,请读者海涵。
摘要:
本文介绍了一种专为分析化学行业设计的数据处理程序,该程序通过自动化处理实验数据,显著提高了数据处理的效率和准确性。程序采用Python编写,具备模块化设计,易于维护和升级,同时旨在符合国家相关标准。
关键词:
分析化学;数据处理;自动化;Python;模块化
引言
分析化学领域中数据处理的复杂性和劳动强度促使了自动化程序的开发。本文旨在介绍一种新型的数据处理程序,其设计背景、功能特点以及应用价值。
2. 程序设计与实现
2.1 项目背景
分析化学作为科学研究的重要分支,其实验过程中产生的数据量庞大且复杂。从业者在日常工作中经常面临数值修约、求平均数、求标准偏差以及制作数据透视表等繁琐的数据处理任务。随着现代仪器分析技术的发展,单个测试序列中能够分析的项目数量显著增加。因此在食品安全等领域,国家适时发布了一些多项目的标准,如《GB 23200.14-2016 食品安全国家标准 果蔬汁和果酒中512种农药及相关化学品残留量的测定 液相色谱-质谱法》。技术的进步带来了对数据处理自动化的迫切需求。
在检验检测行业中,实验数据的准确分析处理对于出具符合国家标准规定的报告至关重要。然而,传统的数据处理方法,如使用Excel进行操作,存在效率低下和容易出错的问题。特别是对于中小型检验检测机构,它们往往缺乏直接购买昂贵的实验室信息管理系统(LIMS)的能力,因此更加依赖于人工操作。此外,Excel的默认修约方式与国家标准《GB/T 8170-2008 数值修约规则与极限数值的表示和判定》的规定不符,需要编写复杂的函数来满足标准要求,这不仅增加了工作难度,也影响了数据处理的准确性。
针对上述问题,本项目旨在开发一种基于Python的分析化学数据处理程序,以实现数据处理的自动化和标准化。该程序的设计考虑了分析化学、科学研究、计量测量等领域的通用性,旨在通过模块化编写提高代码的可维护性和可扩展性。程序的核心功能包括数据清洗、数值修约、统计分析以及报告自动生成等,以期减少人工干预,降低劳动强度,并提高数据处理的效率和准确性。
2.2 功能特点
本程序具有以下功能:
- 数据处理功能:包括但不限于数据清洗、数值修约、计算平均数、标准偏差、生成数据透视表等,满足多样化的数据处理需求。
- 报告生成:程序能够根据处理后的数据,自动生成所需的报告文档,包括标准曲线、检测限、定量限、回收率和精密度等关键指标。
- 用户自定义:用户可以根据实际需求,通过修改程序中的参数和设置,来适应不同的数据处理场景。
本程序具有以下特点:
- 高效率与准确性:程序通过自动化处理,大幅提高了数据处理的速度,同时减少了人为错误,确保了数据处理的准确性。
- 模块化设计:采用模块化编程方法,各个功能模块负责特定的任务,便于代码的调用、修改、维护和升级。
- 减少人工干预:通过合理的控制流程,程序减少了对人工操作的依赖,从而降低了操作的复杂性和出错率。
- 通用性强:程序不仅适用于检验检测行业,还适用于分析化学、科学研究、计量测量等多个领域,具有广泛的适用性。
- 符合国家标准:程序中的数值修约规则严格遵循《GB/T 8170-2008 数值修约规则与极限数值的表示和判定》,确保了数据处理结果符合国家标准规定。
- 技术门槛低:程序基于Python语言开发,易于学习和使用,即使对于非专业的程序员,也能够快速上手。
- 成本效益:相比于购买昂贵的实验室信息管理系统,本程序提供了一种成本较低、技术门槛不高的解决方案。
2.3 系统说明
本程序专为检验检测行业中的实验数据的分析处理和报告出具工作而设计,其核心目的在于提高数据处理的效率和准确性,同时降低人力成本。程序的设计考虑了以下方面:
- 行业标准符合性:程序的设计目的是为了遵循《GB/T 32465-2015化学分析方法验证确认和内部质量控制要求》,确保实验室在首次采用标准方法之前,能够对其进行充分的验证。
- 性能指标覆盖:程序能够处理包括分析系统适应性、选择性、耐用性、线性及校准、回收率、准确度(正确度与精密度)、检出限和定量限、稳定性、检测能力、测量不确定度等在内的一系列性能指标。
- 复杂数据处理能力:针对实验结束后需要进行的复杂分析处理,如回收率、检出限、相对标准偏差等,程序提供了自动化的解决方案,以减少人工操作的出错率。
- 适用性广泛:虽然主要针对检验检测行业,但程序的通用性设计也使其适用于其他有类似数据处理需求的行业,如分析化学、科学研究、计量测量领域。
- 程序的运行环境:用户需要自行安装Python环境、必要的库、IDE,并设置好环境和解释器,以便程序的调试和运行。
2.4数据处理流程
程序运行的顺序包括数据的导入、处理、分析以及报告的生成等步骤详见下图。
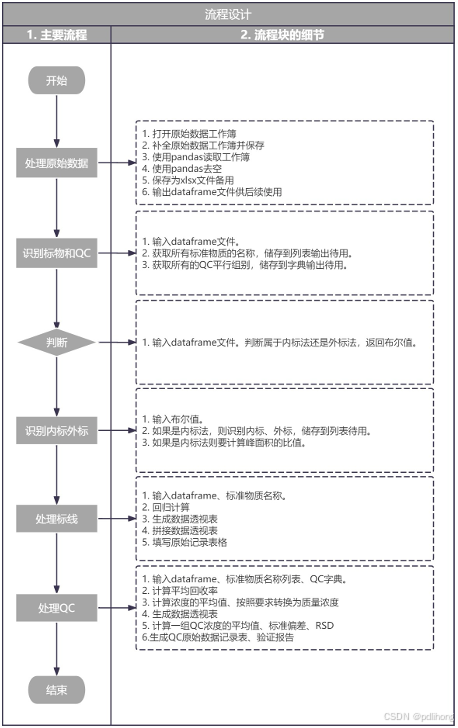
图表 1 程序运行顺序
程序中数据在各个模块之间的传输流转状况详见下图。
图表 2 程序中的数据传输示意图
3. 程序功能详解
3.1 使用方法
略
53种物质约需要86 s,具体时间视具体环境而不同,且调试用时更长。生成的文件就在项目文件夹中。
3.2 程序模块和功能
| 模块名称 |
功能 |
|
| 1 |
open_workbook |
打开工作簿。 |
| 2 |
save workbook |
保存工作簿 |
| 3 |
fill_and_get_title |
整理补全waters仪器产生的原始数据(xlsx文件) |
| 4 |
pandas_open |
使用pandas打开xIsx文件,转换为dataframe格式 |
| 5 |
pandas_write |
将dataframe数据写入xIsx文件并存储。 |
| 6 |
pandas_process |
使用pandas对dataframe进行数据清洗 |
| 7 |
pandas_get_compound_list |
识别物质名称,以列表的格式存储 |
| 8 |
identify_parallel_samples |
识别平行样品的名称,以列表的格式存储 |
| 9 |
get_internal_standard |
识别内标的名称,以列表的格式存储 |
| 10 |
get_external_standard |
识别外标的名称,以列表的格式存储 |
| 11 |
area_ratio |
计算峰面积的比值(内标法) |
| 12 |
concentration_m |
计算质量浓度 |
| 13 |
calculate_is_correlation |
计算内标法的标准曲线 |
| 14 |
calculate_correlation |
计算外标法的标准曲线 |
| 15 |
synthesis_regression_function |
生成标准曲线的方程 |
| 16 |
average_qc |
计算质控样品的平均值 |
| 17 |
calculate_rsd |
计算质控样品的相对标准偏差 |
| 18 |
recovery |
计算平均回收率(一个加标浓度下) |
| 19 |
generate_pivot table |
生成数据透视表(原始数据记录表) |
| 20 |
fill_word_table_std |
填写word模板(标准曲线原始数据记录表) |
| 21 |
fill_word_table |
填写word模板(原始数据记录表) |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











