







文章目录
IO编程
IO编程中,Stream(流)是一个很重要的概念,可以把流想象成一个水管,Input Stream就是数据从外面(磁盘、网络)流进内存,Output Stream就是数据从内存流到外面去。
-
第一种是CPU等着,也就是程序暂停执行后续代码,等100M的数据在10秒后写入磁盘,再接着往下执行,这种模式称为同步IO;
-
另一种方法是CPU不等待,只是告诉磁盘,“您老慢慢写,不着急,我接着干别的事去了”,于是,后续代码可以立刻接着执行,这种模式称为异步IO。
文件操作
open 函数
打开文件
open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Open file and return a stream. Raise OSError upon failure.
Character Meaning 'r'open for reading (default) 'w'open for writing, truncating the file first 'x'open for exclusive creation, failing if the file already exists 'a'open for writing, appending to the end of file if it exists 'b'binary mode 't'text mode (default) '+'open for updating (reading and writing)
| 打开模式 | 执行操作 |
|---|---|
| ‘r’ | 以只读方式打开文件(默认) |
| ‘w’ | 以写入的方式打开文件,会覆盖已存在的文件(相当于删掉后新写入一个文件) |
| ‘x’ | 如果文件已经存在,使用此模式打开将引发异常 |
| ‘a’ | 以写入模式打开,如果文件存在,则在末尾追加写入 |
| ‘b’ | 以二进制模式打开文件 |
| ‘t’ | 以文本模式打开(默认) |
| ‘+’ | 可读写模式(可添加到其他模式中使用) |
| 文件对象方法 | 执行操作 |
|---|---|
| f.close() | 关闭文件 |
| f.read([size=-1]) | 从文件读取size个字符,当未给定size或给定负值的时候,读取剩余的所有字符,然后作为字符串返回 |
| f.readline([size=-1]) | 从文件中读取并返回一行(包括行结束符\n),如果有size有定义则返回size个字符 |
| f.readlines([hint=-1]) | 一次读取所有内容并按行返回list, 适合读配置文件for line in f.readlines(): print(line.strip()) # 把末尾的'\n'删掉 |
| f.write(str) | 将字符串str写入文件 |
| f.writelines(seq) | 向文件写入字符串序列seq,seq应该是一个返回字符串的可迭代对象 |
| f.seek(offset, from) | 在文件中移动文件指针,从from(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offset个字节 |
| f.tell() | 返回当前在文件中的位置 |
| f.truncate([size=file.tell()]) | 截取文件到size个字节,默认是截取到文件指针当前位置 |
-
f = open("C:\\Users\\meij1\\Downloads\\new 1.txt", 'r'/'w')(双反引号,转义)or
f = open("C:/Users/meij1/Downloads/new 1.txt", 'r'/'w')(左斜杠更推荐) -
f.read() 默认读取剩余所有,指针也会到最后去
-
f.seek(位置,起始) f.seek(0, 0) 回到开始位置
-
读取二进制文件时,使用‘rb’,
>>> f = open('/Users/michael/test.jpg', 'rb') -
当文件中有非UTF-8的时候,需加上encoding部分, 当文件编码不规范时,出现非编码字符在read时可能报UnicodeDecodeError,这个时候要加errors参数。
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk', errors='ignore')
-
write特定编码的文本文件,请给
open()函数传入encoding参数,将字符串自动转换成指定编码。 -
关闭文件的两种方式:
由于文件读写时都有可能产生
IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件.- 使用
try ... finally来实现:
try: f = open('/path/to/file', 'r') print(f.read()) finally: if f: f.close()with语句来自动帮我们调用close()方法:
with open('/path/to/file', 'r') as f: print(f.read()) - 使用
eg:
record.txt
小客服:小甲鱼,今天有客户问你有没有女朋友?
小甲鱼:咦??
小客服:我跟她说你有女朋友了!
小甲鱼:。。。。。。
小客服:她让你分手后考虑下她!然后我说:"您要买个优盘,我就帮您留意下~"
小甲鱼:然后呢?
小客服:她买了两个,说发一个货就好~
小甲鱼:呃。。。。。。你真牛!
小客服:那是,谁让我是鱼C最可爱小客服嘛~
小甲鱼:下次有人想调戏你我不阻止~
小客服:滚!!!
================================================================================
小客服:小甲鱼,有个好评很好笑哈。
小甲鱼:哦?
小客服:"有了小甲鱼,以后妈妈再也不用担心我的学习了~"
小甲鱼:哈哈哈,我看到丫,我还发微博了呢~
小客服:嗯嗯,我看了你的微博丫~
小甲鱼:哟西~
小客服:那个有条回复“左手拿著小甲魚,右手拿著打火機,哪裡不會點哪裡,so easy ^_^”
小甲鱼:T_T
================================================================================
小客服:小甲鱼,今天一个会员想找你
小甲鱼:哦?什么事?
小客服:他说你一个学生月薪已经超过12k了!!
小甲鱼:哪里的?
小客服:上海的
小甲鱼:那正常,哪家公司?
小客服:他没说呀。
小甲鱼:哦
小客服:老大,为什么我工资那么低啊??是时候涨涨工资了!!
小甲鱼:啊,你说什么?我在外边呢,这里好吵吖。。。。。。
小客服:滚!!!
split the conversation
''' split files '''
def save_file(boy, girl, count):
# create file name
boy_file_name = 'boy_' + str(count) + '.txt'
girl_file_name = 'girl_' + str(count) + '.txt'
# open the files with write
boy_content = open(boy_file_name, "w", encoding='utf-8')
girl_content = open(girl_file_name, "w", encoding='utf-8')
# write the contents from list
boy_content.writelines(boy)
girl_content.writelines(girl)
# close files
boy_content.close()
girl_content.close()
def split_file(file_name):
f = open(file_name, encoding='utf-8')
boy = []
girl = []
count = 1
for each_line in f:
if each_line[:6] != "======": # split the txt through '======'
# add lines into list
(role, line_speak) = each_line.split(':', 1)
if role == "小甲鱼":
boy.append(line_speak)
if role == "小客服":
girl.append(line_speak)
else:
# save files
save_file(boy, girl, count)
# empty the list for the next cycle
boy = []
girl = []
count += 1
# 3 paragraph with only 2 split lines, the last one need to be collected after for done
save_file(boy, girl, count)
f.close()
split_file('record.txt')
StringIO和BytesIO
StringIO: 内存中读写字符串
BytesIO: 内存中读写bytes
getvalue()方法用于获得写入后的str or bytes。
要把str写入StringIO,我们需要先创建一个StringIO,然后,像文件一样写入即可:
>>> from io import StringIO
>>> f = StringIO()
>>> f.write('hello')
5
>>> f.write(' ')
1
>>> f.write('world!')
6
>>> print(f.getvalue())
hello world!
要读取StringIO,可以用一个str初始化StringIO,然后,像读文件一样读取:
>>> from io import StringIO
>>> f = StringIO('Hello!\nHi!\nGoodbye!')
>>> while True:
... s = f.readline()
... if s == '':
... break
... print(s.strip())
...
Hello!
Hi!
Goodbye!
BytesIO实现了在内存中读写bytes,我们创建一个BytesIO,然后写入一些bytes:
>>> from io import BytesIO
>>> f = BytesIO()
>>> f.write('中文'.encode('utf-8')) # 写入的不是str,而是经过UTF-8编码的bytes。
6
>>> print(f.getvalue())
b'\xe4\xb8\xad\xe6\x96\x87'
读取:
>>> from io import BytesIO
>>> f = BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
>>> f.read()
b'\xe4\xb8\xad\xe6\x96\x87'
>>> f.read().decode('UTF-8')
'中文'
模块和包
模块(module)
-
是一个包含你所定义的函数和变量的文件,一个.py文件称为一个模块(module),最大的好处是提高了代码的可维护性,模块可以被别的程序引入,以使用该模块中的函数等功能。
-
使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中就不冲突,但变量名不能和内置函数名冲突。
-
模块使用import导入, 为防止模块名和系统模块名冲突,Python交互环境执行
import abc检查是否可以导入成功。 -
命名空间:使用 ***模块.方法()*的形式调用具体的方法
导入函数方法:
1) import 模块名
2)from 模块名 import 函数名1,函数名2
3) import 模块名 as 新名字
- if
__name__ == '__main__'
所有模块都有一个__name__属性,__name__的值取决于如何应用模块,在作为独立程序运行的时候,__name__属性的值是'__main__',而作为模块导入的时候,这个值就是该模块的名字了。
- if
包(package)
-
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
-
包(package)
- Python 把同类的模块放在一个文件夹中统一管理,这个文件夹称之为一个包
- 创建一个文件夹,用于存放相关的模块,文件夹的名字即包的名字
- 在文件夹中创建一个
__init__.py的模块文件,内容可以为空. - 将相关的模块文件放入文件夹中
使用方法: import 包名.模块名 as 缩写这样就可以使用了
-
请注意,每一个包目录下面都会有一个
__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是mycompany。类似的,可以有多级目录,组成多级层次的包结构。比如如下的目录结构:
mycompany ├─ web │ ├─ __init__.py │ ├─ utils.py │ └─ www.py ├─ __init__.py ├─ abc.py └─ utils.py文件
www.py的模块名就是mycompany.web.www,两个文件utils.py的模块名分别是mycompany.utils和mycompany.web.utils。 -
模块的使用,标准格式
#!/usr/bin/env python3 # -*- coding: utf-8 -*- ' a test module ' # 任何模块的第一个字符串都被视为模块的文档注释 __author__ = 'Michael Liao' # 作者留名 import sys # 导入模块 def test(): args = sys.argv if len(args)==1: print('Hello, world!') elif len(args)==2: print('Hello, %s!' % args[1]) else: print('Too many arguments!') if __name__=='__main__': test()
容器封装:对数据的封装,eg 列表、元组、字符串等
函数封装:对语句的封装
类的封装:对方法和属性的封装
eg. import urllib.request, urllib 是 Python 负责管理 URL 的包,用于访问网址
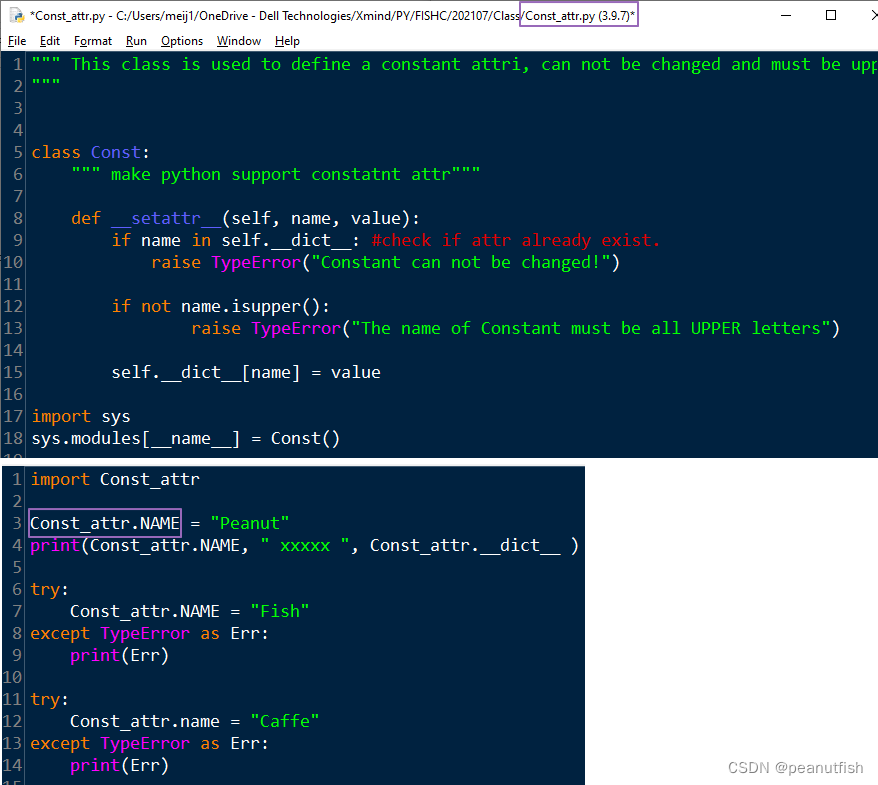
Eg:定义一个Const类使得python可以保存常量(不可修改,名称大写), sys.modules 是一个字典,它包含了从 Python 开始运行起,被导入的所有模块。键就是模块名,值就是模块对象。这里的sys.moudules[__name__] = Const()就规定了模块名为文件名(Const_attr),对应的对象为Const()的实例。

第三方模块
- 第三方库都会在Python官方的pypi.python.org网站注册,要安装一个第三方库,必须先知道该库的名称,可以在官网或者pypi上搜索,比如Pillow的名称叫Pillow,因此,安装Pillow的命令就是:
pip install Pillow
-
Anaconda 更方便, 这是一个基于Python的数据处理和科学计算平台,它已经内置了许多非常有用的第三方库,我们装上Anaconda,就相当于把数十个第三方模块自动安装好了,非常简单易用。
-
下载后直接安装,Anaconda会把系统Path中的python指向自己自带的Python,并且,Anaconda安装的第三方模块会安装在Anaconda自己的路径下,不影响系统已安装的Python目录。
安装好Anaconda后,重新打开命令行窗口,输入python,可以看到Anaconda的信息:
模块搜索路径
- 默认情况下,Python解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在
sys模块的path变量中: - 搜索路径
import sys --> sys.path
`[‘E:\\Python_FishC\\CLASS\\Module’, ‘C:\\Program Files (x86)[\\Python38\\python38.zip](file://Python38/python38.zip)’, ‘C:\\Program Files (x86)[\\Python38\\DLLs](file://Python38/DLLs)’, ‘C:\\Program Files (x86)[\\Python38\\lib](file://Python38/lib)’, ‘C:\\Program Files (x86)[\\Python38](file://Python38)’, ‘C:\\Users\\peanutfish\\AppData\\Roaming\\Python\\Python38\\site-packages’, ‘C:\\Program Files (x86)[\\Python38\\lib\\site-packages](file://Python38/lib/site-packages)’]
最佳存放位置:python38\lib\site-packages
- 方法1:需要到特定目录查找时,直接sys.path.append(‘directory path’) — 运行结束后失效
sys.path.append("E:\\\\Python_FishC\\\\CLASS\\\\Module\\\\temp")
- 方法二: 设置环境变量
PYTHONPATH,该环境变量的内容会被自动添加到模块搜索路径中。设置方式与设置Path环境变量类似。注意只需要添加你自己的搜索路径,Python自己本身的搜索路径不受影响
OS 模块 - 跨平台使用
os模块中关于文件/目录常用函数
| 函数名 | 使用方法 |
|---|---|
| getcwd() | 返回当前工作目录 |
| chdir(path) | 改变工作目录 |
| listdir(path='.') | 列举指定目录中的文件名('.'表示当前目录,'..'表示上一级目录) |
| mkdir(path) | 创建单层目录,如该目录已存在抛出异常 |
| makedirs(path) | 递归创建多层目录,如该目录已存在抛出异常,注意:'E:\\a\\b'和'E:\\a\\c'并不会冲突 |
| remove(path) | 删除文件 |
| rmdir(path) | 删除单层目录,如该目录非空则抛出异常 |
| removedirs(path) | 递归删除目录,从子目录到父目录逐层尝试删除,遇到目录非空则抛出异常 |
| rename(old, new) | 将文件old重命名为new |
| system(command) | 运行系统的shell命令, >>> os.system('cmd') >>> os.system('calc') |
| walk(top) | 遍历top路径以下所有的子目录,返回一个三元组:(路径, [包含目录], [包含文件])【具体实现方案请看:第30讲课后作业^_^】 list(os.walk(top)) |
| 以下是支持路径操作中常用到的一些定义,支持所有平台 | |
| os.curdir | 指代当前目录('.') >>> os.listdir(os.curdir) |
| os.pardir | 指代上一级目录('..') |
| os.sep | 输出操作系统特定的路径分隔符(Win下为'\\',Linux下为'/') |
| os.linesep | 当前平台使用的行终止符(Win下为'\r\n',Linux下为'\n') |
| os.name | os.uname()(linux) | 指代当前使用的操作系统(包括:'posix','nt', 'mac', 'os2', 'ce', 'java') |
os.environ – 操作系统中定义的环境变量
os.environ.get('PATH', ['default']) – 获取PATH变量, 对应key没找到的时候显示default信息
-
复制文件的函数在OS中不存在,原因是复制文件并非由操作系统提供的系统调用。理论上讲,我们通过上一节的读写文件可以完成文件复制,只不过要多写很多代码。但是可以用
shutil模块的copyfile()的函数作为补充。>>> shutil.copyfile('test1.log', 'test2.log') 'test2.log' -
列出当前目录下的所有目录,只需要一行代码:
>>> [x for x in os.listdir('.') if os.path.isdir(x)] ['.lein', '.local', '.m2', '.npm', '.ssh', '.Trash', '.vim', 'Applications', 'Desktop', ...] -
列出所有的
.py文件,也只需一行代码:>>> [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py'] ['apis.py', 'config.py', 'models.py', 'pymonitor.py', 'test_db.py', 'urls.py', 'wsgiapp.py']
os.path模块中关于路径常用函数
| 函数名 | 使用方法 |
|---|---|
| basename(path) | 去掉目录路径,单独返回文件名 |
| dirname(path) | 去掉文件名,单独返回目录路径 |
| join(path1[, path2[, ...]]) | 将path1, path2各部分组合成一个路径名 >>> os.path.join('C:\\', 'A', 'B', 'C') 'C:\\A\\B\\C' |
| split(path) | 分割文件名与路径,返回(f_path, f_name)元组。如果完全使用目录,它也会将最后一个目录作为文件名分离,且不会判断文件或者目录是否存在 |
| splitext(path) | 分离文件名与扩展名,返回(f_name, f_extension)元组 |
| getsize(file) | 返回指定文件的尺寸,单位是字节 |
| getatime(file) | 返回指定文件最近的访问时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) time.localtime(os.path.getatime('xxx\\ss1.txt')) time.gmtime(os.path.getatime('xxx\\ss1.txt')) |
| getctime(file) | 返回指定文件的创建时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
| getmtime(file) | 返回指定文件最新的修改时间(浮点型秒数,可用time模块的gmtime()或localtime()函数换算) |
| 以下为函数返回 True 或 False | |
| exists(path) | 判断指定路径(目录或文件)是否存在 |
| isabs(path) | 判断指定路径是否为绝对路径 |
| isdir(path) | 判断指定路径是否存在且是一个目录 |
| isfile(path) | 判断指定路径是否存在且是一个文件 |
| islink(path) | 判断指定路径是否存在且是一个符号链接 |
| ismount(path) | 判断指定路径是否存在且是一个挂载点 |
| samefile(path1, paht2) | 判断path1和path2两个路径是否指向同一个文件 |
查看、创建和删除目录可以这么调用:
# 查看当前目录的绝对路径:
>>> os.path.abspath('.')
'/Users/michael'
# 在某个目录下创建一个新目录,首先把新目录的完整路径表示出来, join在不同操作系统下回显示对应的分隔符(linux/mac --> / , win --> \)
>>> os.path.join('/Users/michael', 'testdir')
'/Users/michael/testdir'
# 然后创建一个目录:
>>> os.mkdir('/Users/michael/testdir')
# 删掉一个目录:
>>> os.rmdir('/Users/michael/testdir')
- exmaples:
eg1: 搜索特定目录下及其子目录中的特定文件:
import os
def search_file(start_dir, target) :
os.chdir(start_dir)
for each_file in os.listdir(os.curdir) :
if each_file == target :
print(os.getcwd() + os.sep + each_file) # 使用os.sep是程序更标准
if os.path.isdir(each_file) :
search_file(each_file, target) # 递归调用
os.chdir(os.pardir) # 递归调用后切记返回上一层目录
eg2: 在父目录和子目录中搜索视频类型文件并将结果保存至文件中:
import os
file_video = []
def find_video(path):
os.chdir(path)
file_list = os.listdir(os.curdir)
for each_file in file_list:
if not os.path.isdir(each_file):
file_ext = os.path.splitext(each_file)[1]
if file_ext in ['.mp4', '.rmvb', '.avi']:
file_video.append(os.getcwd() + os.sep + each_file + '\n')
else:
find_video(each_file)
os.chdir(os.pardir)
path = input("Please input the path you want to find: ")
find_video(path)
f = open(os.getcwd() + os.sep + 'Videolist.txt', 'w')
for i in file_video:
f.writelines(i)
f.close()
eg3: 在父目录和子目录中查找所有txt文件中的某个关键字出现的行和行中位置
定义了4个函数
import os
def print_pos(key_dict):
keys = key_dict.keys()
keys = sorted(keys) # 由于字典是无序的,我们这里对行数进行排序
for each_key in keys:
print('关键字出现在第 %s 行,第 %s 个位置。' % (each_key, str(key_dict[each_key])))
def pos_in_line(line, key):
pos = []
begin = line.find(key)
while begin != -1:
pos.append(begin + 1) # 用户的角度是从1开始数
begin = line.find(key, begin+1) # 从下一个位置继续查找
return pos
def search_in_file(file_name, key):
f = open(file_name)
count = 0 # 记录行数
key_dict = dict() # 字典,用户存放key所在具体行数对应具体位置
for each_line in f:
count += 1
if key in each_line:
pos = pos_in_line(each_line, key) # key在每行对应的位置
key_dict[count] = pos
f.close()
return key_dict
def search_files(key, detail):
all_files = os.walk(os.getcwd())
txt_files = []
for i in all_files:
for each_file in i[2]:
if os.path.splitext(each_file)[1] == '.txt': # 根据后缀判断是否文本文件
each_file = os.path.join(i[0], each_file)
txt_files.append(each_file)
for each_txt_file in txt_files:
key_dict = search_in_file(each_txt_file, key)
if key_dict:
print('================================================================')
print('在文件【%s】中找到关键字【%s】' % (each_txt_file, key))
if detail in ['YES', 'Yes', 'yes']:
print_pos(key_dict)
key = input('请将该脚本放于待查找的文件夹内,请输入关键字:')
detail = input('请问是否需要打印关键字【%s】在文件中的具体位置(YES/NO):' % key)
search_files(key, detail)
pickle module(泡菜模块)
序列化:将列表之类转换成二进制进行永久保存,pickle.dump()保存,pickle.load()反序列化读出
pickle.dumps()方法把任意对象序列化成一个bytes
>>> d = dict(a=1, b=2)
>>> d
{'a': 1, 'b': 2}
>>> pickle.dumps(d)
b'\x80\x04\x95\x11\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x01a\x94K\x01\x8c\x01b\x94K\x02u.'
>>>
Note: pickle的数据只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
以wb打开文件,pickle.dump()保存内容
# 以wb打开文件,pickle.dump()保存内容
>>> import pickle
>>> list1 = [123, '456', 3.14, [678]]
>>> pickle_file = open("E:\\Python_FishC\\file\\list1.pkl", "wb")
>>> pickle.dump(list1, pickle_file)
>>> pickle_file.close()
# 以rb打开文件,pickle.load()读出文件
>>> pickle_file = open("E:\\Python_FishC\\file\\list1.pkl", "rb")
>>> list2 = pickle.load(pickle_file)
>>> print(list2)
[123, '456', 3.14, [678]]
JSON 格式化
对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
| JSON类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| “string” | str |
| 1234.56 | int或float |
| true/false | True/False |
| null | None |
Python内置的json模块提供了非常完善的Python对象到JSON格式的转换。dump() 和 load()方法和pickle一样,将数据存入/读出文件, 对于dict对象,转换如如丝般顺滑。
>>> d = dict([('apple', 1),('pitaya', 2)])
>>> d
{'apple': 1, 'pitaya': 2}
>>> json.dumps(d) # dumps直接转换成json格式
'{"apple": 1, "pitaya": 2}'
>>> s1 = '{"a":2,"b":3}'
>>> s1
'{"a":2,"b":3}'
>>> json.loads(s1) # loads反序列化回来
{'a': 2, 'b': 3}
>>>
优点:由于JSON标准规定JSON编码是UTF-8,所以我们总是能正确地在Python的str与JSON的字符串之间转换。
JSON 进阶 – 将普通class对象保存
>>> import json
# 创建一个普通class Student
>>> class Student:
... def __init__(self, name, age, score):
... self.name = name
... self.age = age
... self.score = score
...
>>> s = Student('Akali', 18, 99)
# 直接dumps马上报错说Student对象无法被json序列化
>>> json.dumps(s)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
...
TypeError: Object of type Student is not JSON serializable
错误的原因是Student对象不是一个可序列化为JSON的对象。
如果连class的实例对象都无法序列化为JSON,这肯定不合理!
别急,我们仔细看看dumps()方法的参数列表,可以发现,除了第一个必须的obj参数外,dumps()方法还提供了一大堆的可选参数:
https://docs.python.org/3/library/json.html#json.dumps
这些可选参数就是让我们来定制JSON序列化。前面的代码之所以无法把Student类实例序列化为JSON,是因为默认情况下,dumps()方法不知道如何将Student实例变为一个JSON的{}对象。
可选参数default就是把任意一个对象变成一个可序列为JSON的对象,我们只需要为Student专门写一个转换函数,再把函数传进去即可, 这样,Student实例首先被student2dict()函数转换成dict,然后再被顺利序列化为JSON:
>>> def student2dict(std):
... return {'name': std.name, 'age': std.age, 'score': std.score}
...
>>> json.dumps(s, default=student2dict)
'{"name": "Akali", "age": 18, "score": 99}'
>>> s2 = json.dumps(s, default=student2dict)
>>> s2
'{"name": "Akali", "age": 18, "score": 99}'
更方便的方法,普适各种class, 因为通常class的实例都有一个__dict__属性,它就是一个dict,用来存储实例变量。也有少数例外,比如定义了__slots__的class。
>>> json.dumps(s, default=lambda object:object.__dict__)
'{"name": "Akali", "age": 18, "score": 99}'
>>> s.__dict__
{'name': 'Akali', 'age': 18, 'score': 99}
>>>
同样的道理,如果我们要把JSON反序列化为一个Student对象实例,loads()方法首先转换出一个dict对象,然后,我们传入的object_hook函数负责把dict转换为Student实例:
>>> def dict2student(d):
... return Student(d['name'], d['age'], d['score'])
...
>>> json.loads(s2, object_hook=dict2student)
<__main__.Student object at 0x019AFDD8>
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









